首先上源码:
一.概要
使用了2种AI算法:
一种是经典的Pierre Dellacherie算法
一种基于基于深度搜索的算法:
由于时间因,只测试了一次Pierre Dellacherie算法
消行数13W+
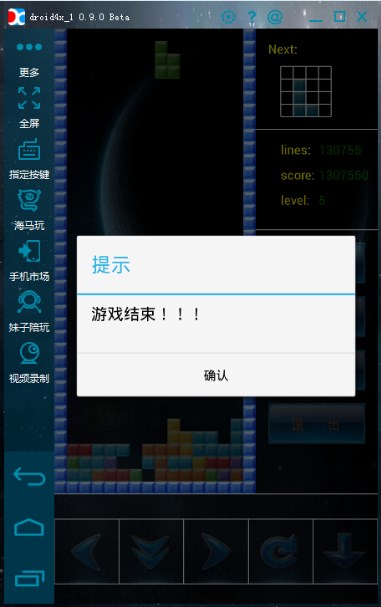
第2种算法没有花时间去测试,理论上消行数应该比较可观
下面简单介绍2种AI算法实现思路
二.Pierre Dellacherie算法:(只考虑当前方块)
Pierre Dellacherie官网:
AI算法主要是评分函数: 所以只介绍评分函数
<1>、尝试着对当前落子的每一种旋转变换、从左到右地摆放,产生所有摆法。
<2>、对每一种摆法进行评价。评价包含如下6项指标:
1.下落高度(Landing Height):
当前方块落下去之后,方块中点距底部的方格数
事实上,不求中点也是可以的,详见官网
我实现的方法是分别求出当前方块固定后, 最高点和最低点之和的平均值
2.消行数(Rows eliminated)
消行层数与当前方块贡献出的方格数乘积
3.行变换(Row Transitions):
从左到右(或者反过来)检测一行,当该行中某个方格从有方块到无方块(或无方块到有方块),
视为一次变换。游戏池边界算作有方块。行变换从一定程度上反映出一行的平整程度,越平整值越小
该指标为所有行的变换数之和
如图:■表示有方块,□表示空格(游戏池边界未画出)
■■□□■■□□■■□□ 变换数为6
□□□□□■□■□■□■ 变换数为9
■■■■□□□□□□■■ 变换数为2
■■■■■■■■■■■■ 变换数为0
4.列变换(Column Transitions):大意同上
列变换从一定程度上反映出一列中空洞的集中程度,空洞越集中值越小
5.空洞数(Number of Holes)
不解释
6.井的总和(Well Sums):
井指两边皆有方块的空列。该指标为所有井的深度连加到1再求总和
注意一列中可能有多个井,如图:
■□□
■□■
■□■
■■■
■□■
■□■
■□■
中间一列为井,深度连加到一的和为 (2+1)+(3+2+1)=9
各项指标权重经验值:
1 -4.500158825082766
2 3.4181268101392694
3 -3.2178882868487753
4 -9.348695305445199
5 -7.899265427351652
6 -3.3855972247263626
最后的评分函数:
private void PierreDellacherie(int boxIndex,int releaseLines) {
int highestY = calcApex(mFirstBoxs);
int landingHeight = landingHeight(boxIndex);
int erodedPieceCellsMetric = erodedPieceCellsMetric(mFirstBoxs,mCurX,mCurY,boxIndex,releaseLines);
int boardRowTransitions = boardRowTransitions(mFirstBoxs,highestY);
int boardColTransitions = boardColTransitions(mFirstBoxs,highestY);
int boardBuriedHoles = boardBuriedHoles(mFirstBoxs,highestY);
int boardWells = boardWells(mFirstBoxs,highestY);
int score = -45*landingHeight + 34*erodedPieceCellsMetric -
32*boardRowTransitions -
93*boardColTransitions -
79*boardBuriedHoles -
34*boardWells;
refreshScore(score);
} 三.基于深度搜索(考虑下一个方块)
1.深度搜索模型
假设游戏宽度为10,只考虑平移下落的可能,在极端的情况下,方块有4种旋转类型 (可以做表优化)
那么对于当前方块则有 4*10 = 40种下落情况
那么有 下一个方块有 4*10 = 40种下落情况
深度遍历则有 40 * 40 = 1600种情况
所以Tetris的AI算法是常量阶
public void seekBestStrategy() {
// 获取当前游戏模型最高点
// 深度搜索存在的情况
for (int rotate = 0;rotate < getRotateCount(mCurType);rotate++) {
for (int i = 0;i < mTetrisGame.mGameWidth - 2;i++) {
// 检测当前坐标是否能移动
// 模拟下落 (类似与人类在大脑思考某种行为的后果如何)
// 设置当前状态
// 消行
// 遍历下一个方块 (遍历下一个方块函数功能和本函数类似,只是该调用变成了评价函数)
// 恢复背景数组状态(最高点向下copy)
}
}
// 找到一个最佳点
setFind(true);
} 2.评价函数
再次强调一遍,AI的关键在于评价函数
a. 脑残评价策略
只考虑2次消行数, 和2次游戏后最终局面的高度
这样会造成大量空洞,游戏很快死掉
b. 简单评价策略
在脑残策略的基础上增加了每列的空洞数量
实现方法也很简单,从最高点向下找空洞
有所改善,但是还是很快死掉
c. 高端策略
在简单策略的基础上增加:
a. 高度差之和
b. 高山数量 (当前列高于临近列)
c 深坑数量 (当前列低于临近列)
d 平均高度
上面的一些权值反映游戏局面地势的平缓程度
然后每种取不同权值,权值不同AI效果不同 (经验主义)