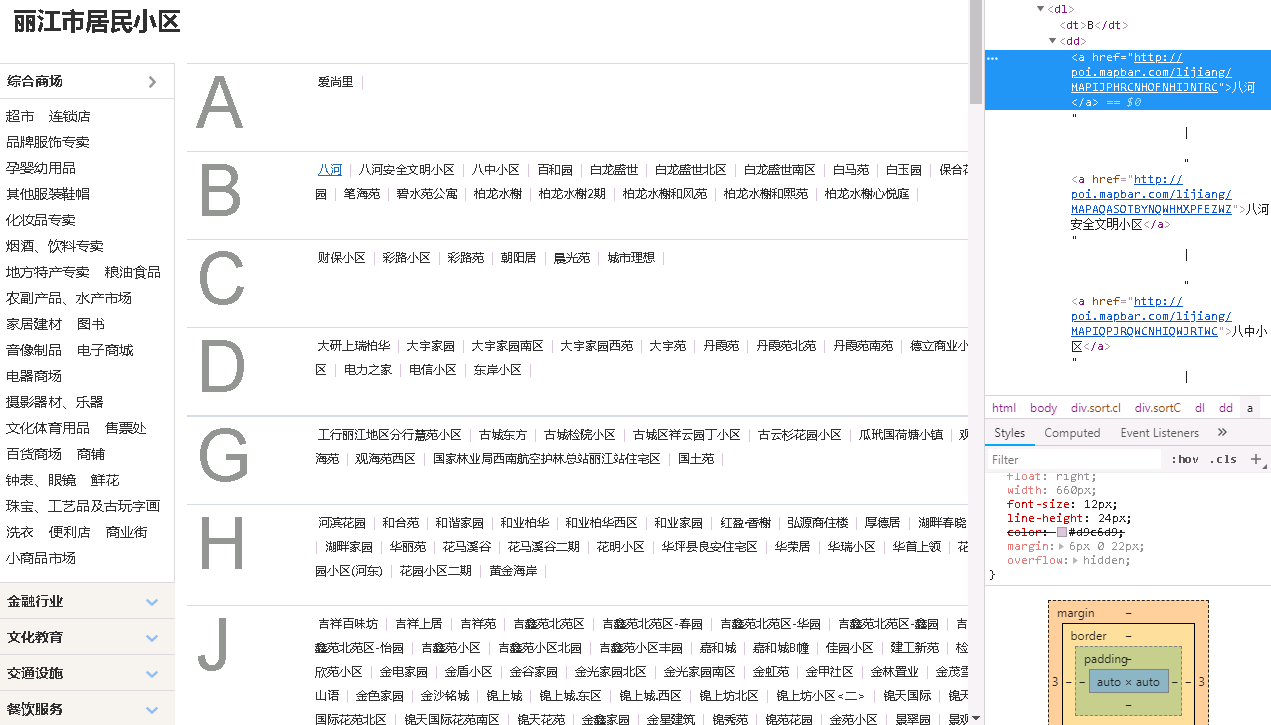
之前做命名实体识别地址时,因为丽江很多地名比较奇怪,不能直接用pyltp提取,准备添加自定义字典,增加地址提取准确率。
地址数据源:
http://poi.mapbar.com/lijiang/
这里以丽江为例,其他地方的地名爬取原理一样的。
获取地址分类:
// 当前页面地址:http://poi.mapbar.com/lijiang/901/
// css选择器
$(".sortBox a")
// init(211) [a#520, a#530, a#541, a
$(".sortBox a")[0].innerHTML
// "超市"
$(".sortBox a")[0].href
// "http://poi.mapbar.com/lijiang/520/"
提取地名:
// 提取某个分类下所有地名标签
// css选择器
$(".sortC a")
// init(328) [a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, a, …]
// 获取标签文字
$(".sortC a")[0].innerHTML
// "爱尚里"
$(".sortC a")[1].innerHTML
// "八河"
$(".sortC a")[1].href
// "http://poi.mapbar.com/lijiang/MAPIJPHRCNHOFNHIJNTRC"
示例代码:
import requests
from bs4 import BeautifulSoup
class AddressType:
def __init__(self):
self.type = ''
self.url = ''
class Address:
def __init__(self):
self.name = ''
self.type = ''
self.url = ''
self.location = ''
self.phone = ''
# 获取地址类型
def get_address_type_url(url):
address_type_list = []
try:
data = requests.get(url).text
xml_data = BeautifulSoup(data, "lxml")
address_type_content = xml_data.select(".sortBox a")
for item in address_type_content:
address_type = AddressType()
address_type.type = item.get_text()
address_type.url = item.get('href')
address_type_list.append(address_type)
except Exception as ex:
print(ex)
finally:
return address_type_list
# 获取某个类型下所有地名
def get_address_name(url):
try:
data = requests.get(url).text
xml_data = BeautifulSoup(data, "lxml")
address_content = xml_data.select(".sortC a")
for item in address_content:
print(item.get_text())
except Exception as ex:
print(ex)
address_type = get_address_type_url('http://poi.mapbar.com/lijiang/980/')
for item in address_type:
print(item.type,item.url)
get_address_name(item.url)
Github地址:
https://github.com/haibincoder/AddressCrawer
数据源示例: