Kylin 技术架构图
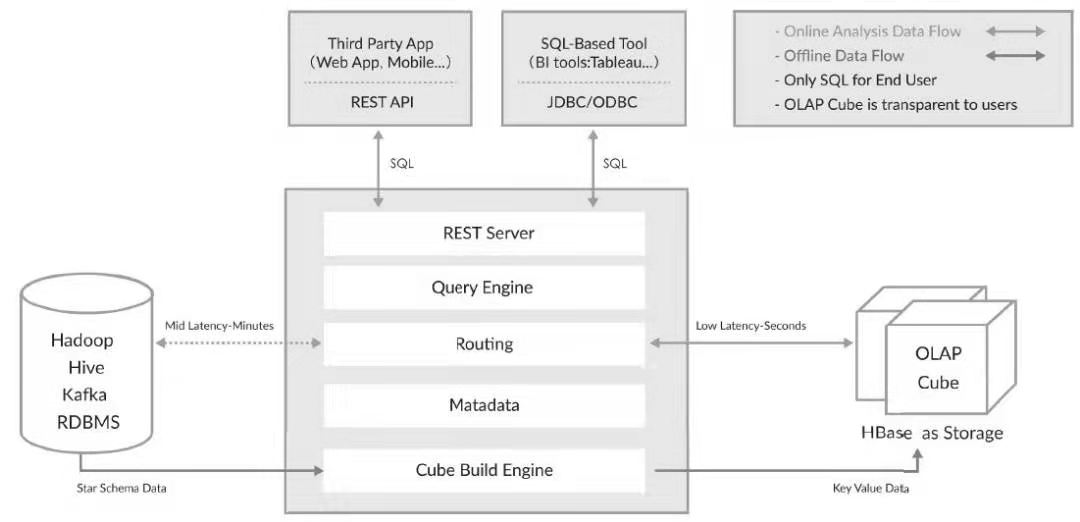
Kylin 系统可以分为在线查询和离线构建两部分
离线构建
- 数据源目前主要是 Hadoop、Hive、Kafka和 RDBMS,其中保持着待分析的用户数据
- Cube Build Engine(构建引擎)从数据源中抽取数据,并构建 Cube
- 数据以关系表的形式输入,且必须符合星形或雪花模型
- 用户可以新选择使用 MapReduce 或 Spark 进行构建
- 构建后的 Cube 保存在存储引擎中(目前 HBase 是默认的存储引擎)
在线查询
- 用户可以通过各种接口方式向 Kylin 发送 SQL 进行查询分析
- 无论哪种接口方式,最终 SQL 都会来到 REST 服务层,再转交给查询引擎进行处理
- SQL 语句是基于数据源的关系模型书写的,而不是 Cube(Kylin 在设计时刻意对查询用户屏蔽 Cube 的概念)
- 分析师只需要理解简单的关系模型就可以使用 Kylin,没有额外的学习门槛(传统的 SQL 应用也很容易迁移)
- 查询引擎解析 SQL,生成基于关系表的逻辑执行计划,然后将其转译为基于 Cube 的物理执行计划,最后查询预计算生成的 Cube 产生结果(整个过程不访问原始数据源)
Kylin 使用流程
- 定义数据集上的一个星形或雪花形模型
- 在定义的数据表上构建cube
- 使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果