聚集型事实表概念
数据仓库的性能是数据仓库建设是否成功的重要标准之一。
聚集主要是通过汇总明细粒度数据来获得改进查询性能的效果。通过访问聚集数据,可以减少数据库在响应查询时必须执行的工作量,能够快速响应用户的查询,同时有利于减少不同用户访问明细数据带来的结果不一致问题。尽管聚集能带来良好的收益,但需要事先对其进行加载和维护,这将会对给 ETL 带来更多的挑战。
淘宝将使用频繁的公用数据,通过聚集进行沉淀,比如卖家最近l 天的交易汇总表、卖家最近N 天的交易汇总表、卖家自然年交易汇总表等。这类聚集汇总数据,被叫作“公共汇总层”。
聚集的基本原则
-
一致性
聚集表必须提供与查询明细粒度数据一致的查询结果。从设计角度来看,确保一致性,最简单的方法是确保聚集星形模型中的维度和度量与原始模型中的维度和度量保持一致。
-
避免单一表设计
不要在同一个表中存储不同层次的聚集数据;否则将会导致双重计算或出现更糟糕的事情。在聚集表中有些行存放按天汇总的交易额,有些行存放按月汇总的交易额, 这将会让使用者产生误用导致重复计算。为了避免此类问题,通用的做法是在聚集时显式地加人数据层级列以示区别,但是这样会加大使用者的使用成本。行之有效的另一种方法是把按天与按月汇总的交易额用两列存放,但是需要在列名或者列注释上能分辨出来。
-
聚集粒度可不同
聚集并不需要保持与原始明细粒度数据一样的粒度,聚集只关心所需要查询的维度。订单涉及的维度有商品、买家、卖家、地域等,比如可以按照商品汇总一天的交易额,可以按照卖家汇总一天的营业额(交易额) , 可以按照商品与地域汇总一月的交易额。
聚集的基本步骤
-
确定聚集维度
在原始明细模型中会存在多个描述事实的维度,如日期、商品类别、卖家等,这时候需要确定根据什么维度聚集,如果只关心商品的交易额情况,那么就可以根据商品维度聚集数据。
-
确定一致性上钻
这时候要关心是按月汇总还是按天汇总,是按照商品汇总还是按照类目汇总,如果按照类目汇总,还需要关心是按照大类汇总还是小类汇总。当然,我们要做的只是了解用户需要什么,然后按照他们想要的进行聚集。
-
确定聚集事实
在原始明细模型中可能会有多个事实的度量,比如在交易中有交易额、交易数量等,这时候要明确是按照交易额汇总还是按照成交数量汇总。
淘宝公共汇总层设计
基本原则
除了聚集的基本原则外,淘宝公共汇总层设计还必须遵循以下原则:
-
数据公用性
汇总的聚集会有第三者使用吗?基于某个维度的聚集是不是经常用于数据分析中?如果答案是肯定的,那么就有必要把明细数据经过汇总沉淀到聚集表中
-
不跨数据域
数据域是在较高层次上对数据进行分类聚集的抽象。淘宝以业务过程进行分类,如交易统一划到交易域下,商品的新增、修改放到商品域下。
-
区分统计周期
在表的命名上要能说明数据的统计周期,如 _Id 表示最近 1 天, td 表示截至当天, nd 表示最近 N 天
交易汇总表设计
聚集是指针对原始明细粒度的数据进行汇总,下图为淘宝交易事务事实表
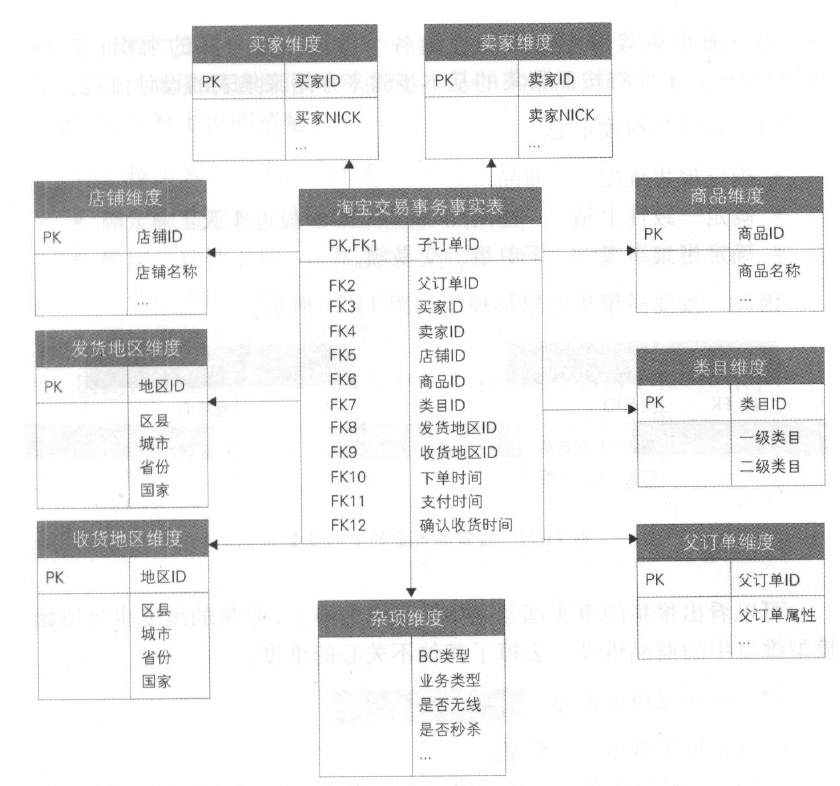
潜在的聚集如下表:

可以看出聚集的组合可能性为各个维度属性个数的乘积: 2× 2 ×2× 2 × 3 × 5 …
按照商品粒度汇总
- 确定聚集维度一一商品
- 确定一致性上钻一一按商品(商品ID )最近 1 天汇总
- 确定聚集事实一一下单量、交易额
因此,按商品聚集的星形模型如下:
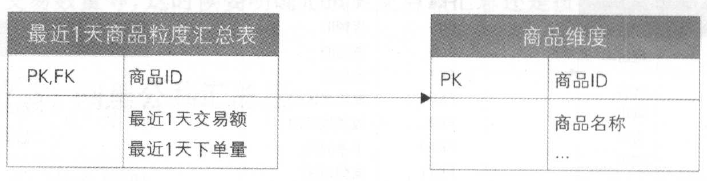
可以看出聚集的事实都是原始模型中的事实,聚集的维度也是原始模型维度中的商品维度,去掉了其他不关心的维度。
按照卖家粒度汇总
- 确定聚集维度一一卖家
- 确定一致性上钻一一按卖家(卖家ID )最近 7 天和最近30 天汇总
- 确定聚集事实一一交易额
因此,按卖家聚集的星形模型如下:
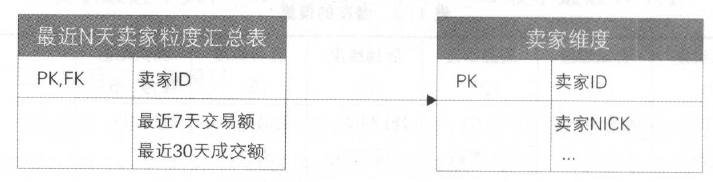
前面在“聚集的基本原则”中说过,应该避免将不同层级的数据放在一起,为此我们选择用两列存放7 天和30 天的事实,但是需要在列
名和字段注释上说明清楚。
按照卖家、买家、商品粒度汇总
- 确定聚集维度一一卖家、买家、商品
- 确定一致性上钻一一按卖家(卖家ID ) 、买家(买家ID )、商品(商品ID )最近 1 天汇总
- 确定聚集事实一一交易额
因此,按卖家、买家、商品聚集的星形模型如下:
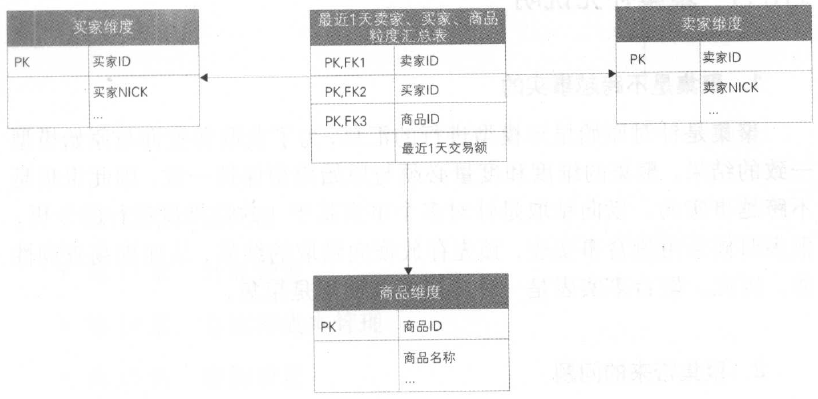
可以看出聚集的粒度越细,记录的条数越多,就会越接近原始明细模型的粒度。
按照二级类目汇总
-
确定聚集维度一一类目
-
确定一致性上钻一一按最近 1 天类目维度的二级维度属性汇总
-
确定聚集事实一一交易额
因此,按二级类目聚集的星形模型如下:
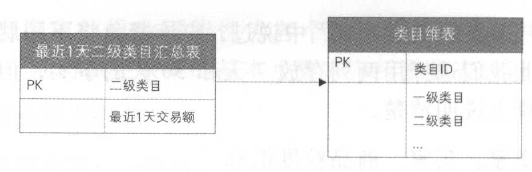
与之前的三个聚集表不同的是,这个聚集模型不是根据维度主键属性进行的聚集,而是根据类目的层次维度属性进行的上钻聚集。
注意事项
聚集是不跨越事实的
聚集是针对原始星形模型进行的汇总,为了获取和查询与原始模型一致的结果,聚集的维度和度量必须与原始模型保持一致,因此聚集是
不跨越事实的。
横向钻取是针对多个事实基于一致性维度进行的分析,很多时候采用融合事实表,预先存放横向钻取的结果,从而提高查询性能。因此,融合事实表是一种导出模式而不是聚集。
聚集带来的问题
聚集会带来查询性能的提升,但聚集也会增加 ETL 维护的难度。
当子类目对应的一级类目发生变更时,先前存在的、已经被汇总到聚集表中的数据需要被重新调整。这一额外工作随着业务复杂性的增加,会导致多数 ETL 人员选择简单强力的方法,删除并重新聚集数据。