官网tutorial: http://api.mongodb.com/python/current/tutorial.html
本教程将要告诉你如何使用pymongo模块来操作MongoDB数据库。
一、先决条件
开始之前,我们需要确定电脑已经安装了pymongo和MongoDB.
1.安装pymongo
使用pip安装pymongo,在cmd命令行输入:
pip install pymongo
在python IDLE 中输入:import pymongo 没有报错表示安装成功。
2.安装MongoDB
参考这个链接:http://www.cnblogs.com/billyzh/p/5913687.html
如果不安装MongoDB会出现后面的一个问题。
3.MongoDB中的基本概念
在MongoDB中基本的概念是文档(document)、集合(collection)、数据库(database).
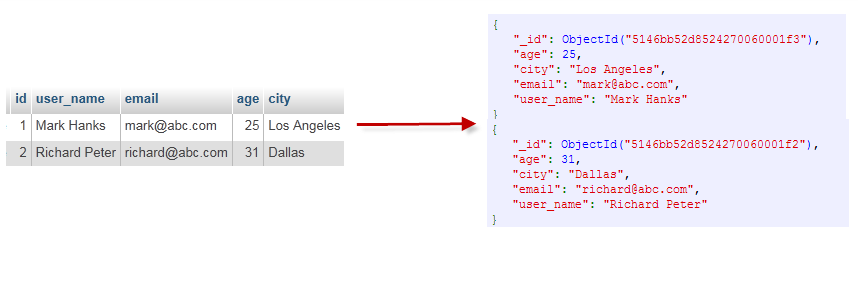
下图(盗的图)可能容易理解MongoDB中的一些概念:

通过下图实例,可以更直观的的了解MongoDB中的一些概念:
二、通过MongoClient建立一个连接
开始使用pymongo的第一步是创建一个MongoClient,来运行mongod实例。
>>> from pymongo import MongoClient
>>> client = MongoClient()
上面代码将会连接默认的host和port。也可指定:
>>> client = MongoClient('localhost',27017)
或者用MongoDB URI格式:
>>> client = MongoClient('mongodb://localhost:27017/')
默认状态下Mongo客户端是没有加密的,但是如果需要通过账户登录:
>>> client = MongoClient('mongodb://账号:密码@localhost:27017/')
三、获取一个数据库
一个MongoDB实例可以支持多个独立的数据库。使用PyMongo时,可以通过访问MongoClient的属性的方式来访问数据库。
>>> db = client.test_database
如果数据库名字使用属性方式不能访问(像test-database),也可以通过访问字典值的方式。
>>> db = client['test-database']
四、获取一个Collection
一个collection是一组存在MongoDB中的文件(documents),大致可以认为是关系型数据库中表的概念。
获取Collection方法与获取数据库方法一致:
>>> collection = db.test_collection #注意连接符是_不是-
或用字典方式:
>>> collection = db['test-collection']
需要注意的是,MongoDB里的collections(集合)和databases(数据库)都是惰性创建的,前面提到的所有命令
实际上没有对MongoDB server进行任何操作。当第一个文件插入后,collections和databases才会被创建。
五、文件(Documents)
数据在MongoDB中是用JSON类文件的形式表示和保存起来的。在pymongo中用字典来代表文件。
例如,下面这个字典可能被用来代表一篇博客文章:
>>> import datetime
>>> post = {
"author": "Mike",
"text": "My first blog post!",
"tags": ["mongodb","python","pymongo"],
"date": datetime.datetime.utcnow()
}
注意,文件里可以包含python原生(native)类型(datetime.datetime实例),这些类型的值会被自动在原生类型和BSON格式之间转换。
六、插入一个文件(Inserting a Document)
插入一个文件到collection中,可以使用insert_one()方法。
>>> posts = db.posts
>>> post_id = posts.insert_one(post).inserted_id
>>> post_id
ObjectId('57eb8f2177eddf292cbea0b3')
当一个文件被插入一个特殊的键值'_id',即使文件内没有_id这个键值,那么系统自动添加一个到文件里。
这是一个特殊键值,它的值在整个collection里是唯一的。insert()返回这个文件的_id值。
插入第一个文件后,这个posts collection 就真正的在server上创建了。我们可以通过查看数据库上的
所有collection来验证:
>>> db.collection_names(include_system_collections=False)
['posts']
七、获取单个文件 find_one()
在MongoDB中,最基本的查询是find_one。这个方法返回一个符合查询的文件,或者在没有匹配的时候返回None。
当只有一个文件符合条件的时候,或者只对第一个符合条件的文件感兴趣的时候,这个方法是很有用的。
我们用find_one()来获取posts collection 里的第一个文件:
>>> posts.find_one()
{'date': datetime.datetime(2016, 9, 27, 3, 56, 26, 78000), 'author': 'Mike',
'_id': ObjectId('57e9edea77eddf223cde3314'), 'tags': ['mongodb', 'python', 'pymongo'],
'text': 'My first blog post!'}
返回结果是一个我们之前插入的符合条件的字典类型值。
注意,返回的文件里包含_id这个键值,这是自动添加的。
find_one()还支持对特定元素进行匹配的查询。限制我们文档的作者是"Mike",可以这么做:
>>> posts.find_one({"author":"Mike"})
{'date': datetime.datetime(2016, 9, 27, 3, 56, 26, 78000), 'author': 'Mike',
'_id': ObjectId('57e9edea77eddf223cde3314'), 'tags': ['mongodb', 'python', 'pymongo'],
'text': 'My first blog post!'}
如果我们用不同的作者,比如:"Eliot",将不会得到结果。
>>> posts.find_one({"author":"Eliot"})
>>>
八、按照ObjectId查询
通过_id也可以进行查询,在例子中就是ObjectId:
>>> post_id
ObjectId('57eb54a877eddf292cbea0a8')
>>> posts.find_one({"_id": post_id})
{'date': datetime.datetime(2016, 9, 28, 5, 25, 53, 6000), 'author': 'Mike',
'_id': ObjectId('57eb54a877eddf292cbea0a8'), 'tags': ['mongodb', 'python'],
'text': 'My first blog post!'}
注意:ObjectId 并不等同于它的字符串形式。
>>> post_id_as_str = str(post_id)
>>> posts.find_one({"_id": post_id_as_str}) #No result
>>>
在web应用的一个常见任务就是在request的URL里获取ObjectId,然后找到与之匹配的文件。
在本例中,必须要先从字符串转换为ObjectId,然后传给find_one:
>>> from bson.objectid import ObjectId
#从URL里获取post_id,然后把它作为字符串传入
>>> def get(post_id):
#将字符串转换为ObjectId
document = client.db.collection.find_one({"_id": ObjectId(post_id)})
小插曲:
MongoDB以BSON格式保存数据。BSON字符串都是UTF-8编码的,所以pymongo必须确保它保存的字符串值
包含有效地UTF-8数据.常规字符串(<type ‘str’>)都是有效的,可以不改变直接保存。
Unicode字符串(<type ‘unicode’>)就需要先编码成UTF-8格式。
九、批量插入
为了让查询更有趣,我们多插入几个文件。除了单个文件插入,也可以通过给insert_many()方法传入
一个列表(list),作为该方法的第一个参数,进行批量插入操作。
这将会插入列表(list)中的每个文件(document)到集合中去,而且只向server发送一条命令:
new_posts = [{"author": "Mike",
"text": "Another post!",
"tags": ["bulk", "insert"],
"date": datetime.datetime(2009, 11, 12, 11, 14)
},
{"author": "Eliot",
"title": "MongoDB is fun",
"text": "and pretty easy too!",
"date": datetime.datetime(2009, 11, 10, 10, 45)
}]
>>> result = posts.insert_many(new_posts)
>>> result.inserted_ids
[ObjectId('57eb700b77eddf292cbea0a9'), ObjectId('57eb700b77eddf292cbea0aa')]
这个例子里有一些比较有趣的地方:
insert_many()现在返回两个ObjectId实例,每个代表一个插入的文件。
new_posts[1]与其他的posts内容格式不相同,里面没有"tags”。另外我们增加了一个新的“title”域。这就是MongoDB所提到的无schema特点。
十、查询多个文件
为了得到更多的文件,我们使用find()方法。find()返回一个Cursor实例,可使我们遍历所有匹配的文件。
比如遍历每个posts collection里的文件:
>>> for post in posts.find():
post
与使用find_one()时候相同,可以传入一个文件来限制查询结果。比如查询作者"Mike" 文件:
>>> for post in posts.find({"author":"Mike"}):
post
十一、文件数量(Counting)
如果只想知道符合查询条件的文件有多少,可以用count()操作,而没必要进行完整的查询。
查询collection的文件总数:
>>> posts.count()
11
或者只是查询一些特定文件数量:
>>> posts.find({"author": "Mike"}).count()
10
十二、限定范围的查询
MongoDB支持多种高级查询。比如我们按照时间(小于某个时间)来查询,结果按作者名参数来排序:
>>> d = datetime.datetime(2009,11,12,12)
>>> for post in posts.find({"date":{"$lt":d}}).sort("author"):
print(post)
{'date': datetime.datetime(2009, 11, 10, 10, 45), 'author': 'Eliot', 'text': 'and pretty easy too!', '_id': ObjectId('57eb700b77eddf292cbea0aa'), 'title': 'MongoDB is fun'}
{'date': datetime.datetime(2009, 11, 12, 11, 14), 'author': 'Mike', '_id': ObjectId('57eb700b77eddf292cbea0a9'), 'tags': ['bulk', 'insert'], 'text': 'Another post!'}
这里使用了特殊的"$lt"操作符来进行范围查询,并调用sort()方法,对结果按照作者参数排序。
十三、索引(Indexing)
添加索引可以帮助加快某些查询,也可以添加额外的功能来查询和存储文件。
在这个示例中,我们将演示如何在一个键上创建一个唯一索引,这个索引将拒绝--那些已经在索引中存在该键值的文件。
首先,我们需要创建一个索引:
>>> result = db.profiles.create_index([('user_id',pymongo.ASCENDING)],unique = True)
>>> result
'user_id_1'
>>> list(db.profiles.index_information())
['_id_', 'user_id_1']
注意:现在我们有两个索引,一个索引 _id是MongoDB自己创建的。另外一个 user_id是我们刚刚创建的。
现在,让我们建立一些用户配置文件:
>>> user_profiles = [{'user_id':211,'name':'Luke'},{'user_id':212,'name':'Ziltoid'}]
>>> result = db.profiles.insert_many(user_profiles)
该索引可以防止我们的user_id已经插入集合中的文档:
>>> new_profile = {'user_id': 213, 'name': 'Drew'}
>>> duplicate_profile = {'user_id': 212, 'name': 'Tommy'}
>>> result = db.profiles.insert_one(new_profile) # This is fine.
>>> result = db.profiles.insert_one(duplicate_profile)
Traceback (most recent call last):
pymongo.errors.DuplicateKeyError: E11000 duplicate key error collection: test_database.profiles index: user_id_1 dup key: { : 212 }
关于索引的MongoDB文档链接:
问题:
1.pymongo.errors.ServerSelectionTimeoutError: localhost:27017: [WinError 10061] 由于目标计算机积极拒绝,无法连接。
原因:未装MongoDB或者MongoDB服务没有开启。(这个错误找了很长时间,哎。。。)
参考链接:http://www.cnblogs.com/greenteaone/p/3745734.html
2.在数据库存入了文件,如何查看呢?就需要用到MongoDB可视化工具了。
1)MongoBooster(已用)
下载地址:http://mongobooster.com/home
2)Robomongo
下载地址:https://robomongo.org/