该项目主要包含以下四个步骤步骤
1.数据理解
2.数据预处理
3.数据建模
数据集可以在kaggle网站下载,也可以到博主的网盘下载
背景介绍
根据titanic乘客的信息预测其是否能存活
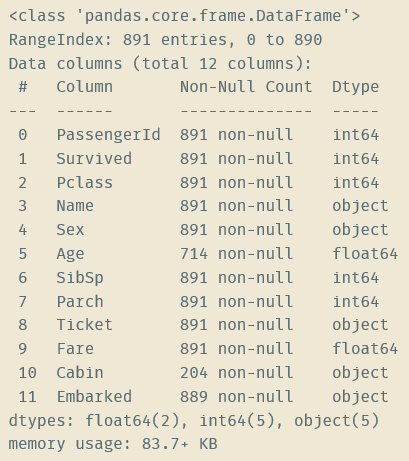
titanic数据集的样本共有11个特征,分别为
PassengerId:乘客的编号
Pclass:船舱的等级
Name:姓名
Sex:性别
Age:年龄
SibSp:非直系亲属的数量
Parch:直系亲属的数量
Ticket:船票号码
Fare:船票价格
Cabin:船舱位置
Embarked:登船的入口
在训练集中共891位旅客,其中幸存的旅客占38.38%
Jupyter Notebook代码如下
import pandas as pd import numpy as np from sklearn import tree from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.model_selection import GridSearchCV from sklearn.model_selection import cross_val_score import matplotlib.pyplot as plt import graphviz import csv
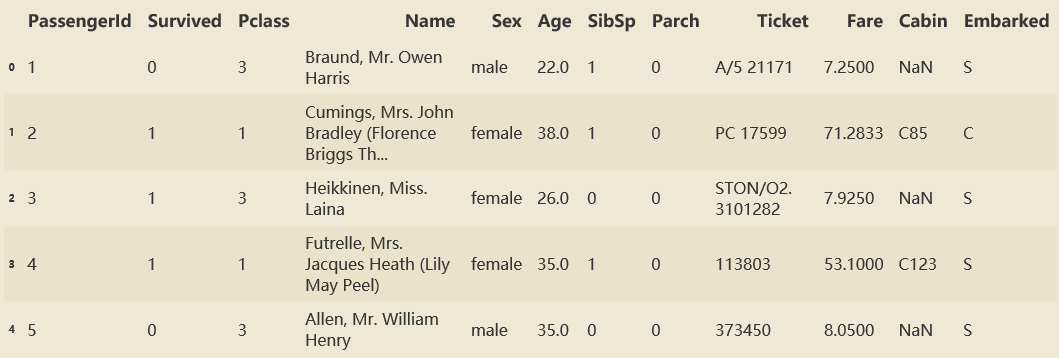
#读取训练数据 data = pd.read_csv('train.csv') #查看data的信息,可以看到data的列名、各列的非空项数量、各列的数据类型 data.info() #查看data的前5行 data.head()
#数据预处理函数 def data_preprocess(data, type): #删除缺失值过多的列,和观察判断来说和预测的y没有关系的列 data.drop(["Cabin","Name","Ticket"],inplace=True,axis=1) #处理缺失值,对缺失值较多的列进行填补,有一些特征只确实一两个值,可以采取直接删除记录的方法 data["Age"] = data["Age"].fillna(data["Age"].mean()) if type == 'train': data = data.dropna() #将二分类变量转换为数值型变量 data["Sex"] = (data["Sex"]== "male").astype("int") #将三分类变量转换为数值型变量 labels = data["Embarked"].unique().tolist() data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x)) return data
#数据预处理 data = data_preprocess(data, 'train') #划分特征与标签 Xdata = data.iloc[:,data.columns != "Survived"] Ydata = data.iloc[:,data.columns == "Survived"] #划分训练集与测试集 from sklearn.model_selection import train_test_split Xtrain, Xtest, Ytrain, Ytest = train_test_split(Xdata,Ydata,test_size=0.2) #修正测试集和训练集的索引 for i in [Xtrain, Xtest, Ytrain, Ytest]: i.index = range(i.shape[0])
#使用不同深度的决策树进行训练和测试 train_scores = [] test_scores = [] clfs = [] max_depth = 20 for i in range(1,max_depth+1): clf = DecisionTreeClassifier(random_state=20 ,max_depth=i ,criterion="entropy" ) clf = clf.fit(Xtrain, Ytrain) train_scores.append(clf.score(Xtrain,Ytrain)) test_scores.append(clf.score(Xtest,Ytest)) clfs.append(clf) print(max(test_scores)) plt.plot(range(1,max_depth+1),train_scores,color="red",label="train") plt.plot(range(1,max_depth+1),test_scores,color="blue",label="test") plt.xticks(range(1,max_depth+1)) plt.legend() plt.show()
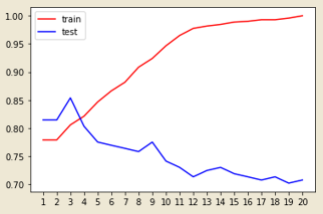
#选择在测试集上表现最好的决策树, n = test_scores.index(max(test_scores)) clf = clfs[n] #测试一下这棵最好的决策树 score = clf.score(Xtest, Ytest) print(score) #用全部数据训练最好的那棵树 clf = clf.fit(Xdata, Ydata)
#读取参赛数据并进行数据预处理 data = pd.read_csv('test.csv') data = data_preprocess(data, 'test') data["Fare"] = data["Fare"].fillna(data["Fare"].mean()) #填充缺失值 #对参赛样本进行预测 result = clf.predict(data) #将结果写入csv文件 csvfile = open("result.csv","w",newline = "") writer = csv.writer(csvfile) data = np.array([list(range(892,1310)),list(result)]) writer.writerow(['PassengerId','Survived']) writer.writerows(data.T) csvfile.close() print('finish')
Kaggle排名
