上篇文章中提到了使用pillow对手写文字进行预处理,本文介绍如何使用kNN算法对文字进行识别。
基本概念
k最邻近算法(k-Nearest Neighbor, KNN),是机器学习分类算法中最简单的一类。假设一个样本空间被分为几类,然后给定一个待分类的特征数据,通过计算距离该数据的最近的k个样本来判断这个数据属于哪一类。如果距离待分类属性最近的k个类大多数都属于某一个特定的类,那么这个待分类的数据也就属于这个类。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。kNN在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别,在决策时,只与极少量的相邻样本有关。通常,k是不大于20的整数。
下图所示,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
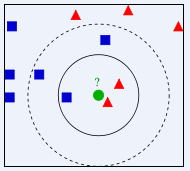
在理想情况下,k值选择1,即只选择最近的邻居。在现实生活中往往没这么理想,比如对于价格来说,有些顾客消息闭塞,可能会为 “最近的邻居”多付很多钱,所以应当货比三家,多选择一些邻居,取均值来减少噪声。实际上,k值过大或过小都将影响结果。
计算过程
过程如下:
- 计算训练集中的点与当前点之间的距离;
- 按距离降序排序;
- 选取与当前点距离最小的k个点;
- 如果是数值型数据,计算前k个点的均值;如果是离散数据,计算前k个点所在类别出现的频率;
- 如果是数值型数据,返回前k个点的均值作为预测数值;如果是离散数据,返回前k个点出现频率最高的类别作为预测分类。
代码如下:
1 from os import listdir 2 3 #将图片文件转换为向量 4 def img2vector(filename): 5 with open(filename) as fobj: 6 arr = fobj.readlines() 7 8 vec, demension = [], len(arr) 9 for i in range(demension): 10 line = arr[i].strip() 11 for j in range(demension): 12 vec.append(int(line[j])) 13 14 return vec 15 16 #读取训练数据 17 def createDataset(dir): 18 dataset, labels = [], [] 19 files = listdir(dir) 20 for filename in files: 21 label = int(filename[0]) 22 labels.append(label) 23 dataset.append(img2vector(dir + '/' + filename)) 24 25 return dataset, labels 26 27 #计算谷本系数 28 def tanimoto(vec1, vec2): 29 c1, c2, c3 = 0, 0, 0 30 for i in range(len(vec1)): 31 if vec1[i] == 1: c1 += 1 32 if vec2[i] == 1: c2 += 1 33 if vec1[i] == 1 and vec2[i] == 1: c3 += 1 34 35 return c3 / (c1 + c2 - c3) 36 37 def classify(dataset, labels, testData, k=20): 38 distances = [] 39 40 for i in range(len(labels)): 41 d = tanimoto(dataset[i], testData) 42 distances.append((d, labels[i])) 43 44 distances.sort(reverse=True) 45 #key label, value count of the label 46 klabelDict = {} 47 for i in range(k): 48 klabelDict.setdefault(distances[i][1], 0) 49 klabelDict[distances[i][1]] += 1 / k 50 51 #按value降序排序 52 predDict = sorted(klabelDict.items(), key=lambda item: item[1], reverse=True) 53 return predDic 54 55 dataset, labels = createDataset('trainingDigits') 56 testData = img2vector('testDigits/8_19.txt') 57 print(classify(dataset, labels, testData))
我们事先使用pillow对手写数字进行了二值化处理,形成一个32*32的矩阵,并将每个训练样本保存到一个txt文件,文件名以数字开头,这个数字就是手写数字的label,如3_1.txt,其中的内容是:
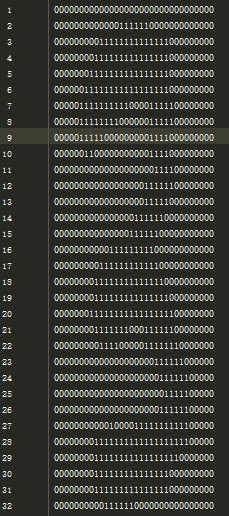 由于特征值仅由0和1构成,可以将二维的样本数据保存到一维数组,img2vector完成了数据的转换。在计算相似度时,使用谷本系数(Tanimoto)计算有限离散集之间的距离,其公式是:
由于特征值仅由0和1构成,可以将二维的样本数据保存到一维数组,img2vector完成了数据的转换。在计算相似度时,使用谷本系数(Tanimoto)计算有限离散集之间的距离,其公式是: ,两者重合(相交)的越多,其相似度越高。classify对测试数据进行分类,返回一个包含了预测结果和结果几率的字典。
,两者重合(相交)的越多,其相似度越高。classify对测试数据进行分类,返回一个包含了预测结果和结果几率的字典。
加权kNN
在上述手写识别的例子中,供使用了900个测试样本,其中34个产生了误判,下图是一个误判的例子:

图中是手写数字1,程序判断为7,其原因是代码所用的方法有可能会选择很远的近邻:
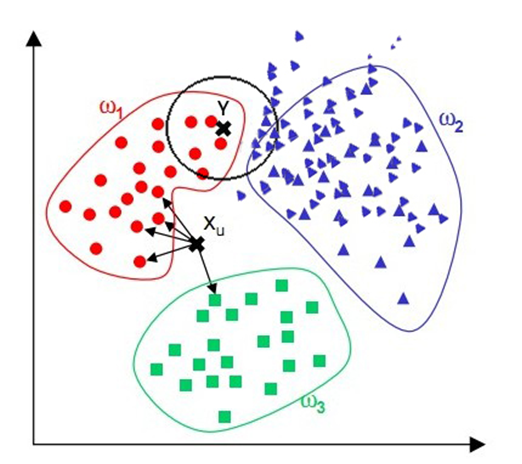
Y点肉眼去看因为在红色区域内很容易判断出多半属于红色一类,但因为蓝色过多,若K值选取稍大则很容易将其归为蓝色一类。为了改进这一点,可以为每个点的距离增加一个权重,这样距离近的点可以得到更大的权重。具体的加权方法将会在下一篇文章中介绍。
出处:微信公众号 "我是8位的"
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注作者公众号“我是8位的”
