SQL Server使用统计对象的histogram来估计谓词predicate的集势,并利用该信息来生成优化的执行计划。查询优化器通过检查
查询参数的值的方式来进行优化,这种模式也称之为“参数探查(parameter sniffing)”,其利在于:根据查询的当前参数值产生的执行计划可以提高应用程序的性能,我们也知道:计划缓存可以存储这些执行计划,以便相同查询再次执行时可以重用这些缓存的执行计划,这极大地节省了时间和CPU资源(查询优化器不需要再次编译)。
虽然查询优化器可以和计划缓存很好地协同工作,不过,偶尔也会发生一些性能问题。由于查询优化器可以为同一个查询产生多个执行计划,这主要取决于参数值、缓存,就该查询的一个实例而言(得益于better plan),仅重用这些计划的某一个可能是个性能问题,不过,使用显式的参数查询问题是已知问题,使用存储过程就是这样一个例子。下面我通过一些例子来介绍该问题并给出一些修复的建议。
首先,在AdventureWorks数据库中创建以下存储过程:
CREATE PROCEDURE test (@pid int)
AS
SELECT * FROM Sales.SalesOrderDetail
WHERE ProductID = @pid
接着,开启显示执行计划,运行以下语句来执行存储过程:
EXEC test @pid = 897
由于查询优化器估计满足该参数的查询有一小部分记录,产生了以下的执行计划,该计划使用“索引查找”运算符,以便快速通过现有的非聚集索引来找到记录,使用“键查询”运算符,基于查询请求的其他列来对表进行搜索。
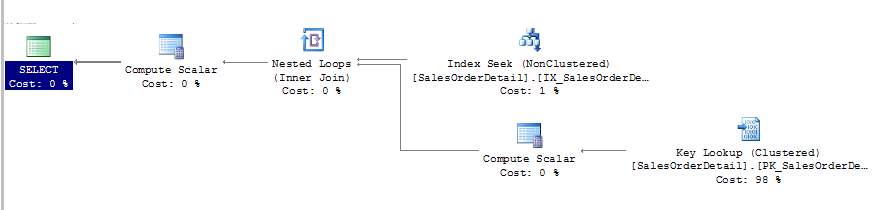
从上图可以看出,索引查找与键查询组合查询在本例中是不错的选择,原因是查询具有较高的选择性,下面用不同的ProductID再运行一次存储过程,为方便查看结果,开启SET STATISTICS ON语句来显示磁盘活动的IO数:
SET STATISTICS IO ON
go
EXEC test @pid = 870
go
IO统计:
(4688 row(s) affected)
Table 'SalesOrderDetail'. Scan count 1, logical reads 14377, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
当第二次执行存储过程,SQL Server需要执行约14000次的逻辑读,而SalesOrderDetail表约有1240个页,显然其所需开销比扫描整个表的开销大10倍。那么,第二次的执行为何会如此慢?当SQL Server第二次执行时,它使用了第一次执行产生的执行计划,对于本例来说,对于第一个查询中使用的参数而产生的计划是优化的,但不适用于第二个查询。
现在清除计划缓存从内存中删除当前的执行计划,再次用先前的参数运行存储过程:
DBCC freeproccache
EXEC test @pid=870
由于计划缓存中没有可用的计划,SQL Server使用ProductID为870进行优化,并为其生成一个优化的执行计划,新的计划则使用“聚集索引扫描”,如下图所示:

上面执行的I/O数如下:
(4688 row(s) affected)
Table 'SalesOrderDetail'. Scan count 1, logical reads 1241, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
从执行的IO信息可以知道,这次的执行仅扫描了1241次逻辑读,相比于先前的14337个页来说要小得多。
当然,这并不是说使用存储过程有问题,需要知道有这样一个问题:当调用存储过程时使用不同的参数时,其性能会随着其参数不同而发生变化,针对此问题,有一些可用的方案供考虑。
Typical参数的优化
有一种可能情况:当某个查询在相同的执行计划中多次执行受益,极大地减小了优化的开销,对于这种情况,可以使用OPTIMIZE FOR 提示(此提示在SQL SERVER 2005引入)。对于多数可能的值来说,使用此提示可以生成优化的计划,只有使用典型的参数不使用最佳的计划。
假设,几乎所有我们的存储过程都使用索引查找和键查询运算,将会得到受益,你可以用以下的方式来重写存储过程:
alter PROCEDURE test (@pid int)
AS
SELECT * FROM Sales.SalesOrderDetail
WHERE ProductID = @pid
OPTION (OPTIMIZE FOR (@pid = 897))
当第一次运行存储过程时,优化器会针对897进行优化,而不在乎在执行时指定的参数值,该计划则存储在计划缓存中,用于后续的存储过程调用。用以下值再次进行测试:
EXEC test @pid = 870
你可以通过其执计划查看详细的信息,如下图所示:
<ParameterList>
<ColumnReference Column="@pid" ParameterCompiledValue="(897)" ParameterRuntimeValue="(870)" />
</ParameterList>
使用此提示的好处是可以极大地控制哪一个计划存储在计划缓存,以备重用,在先前的例子中,你对两个执行计划中的哪一个存储在计划缓存中没有控制。
每执行时优化
若没有可用的参数或计划可用,你还可以对每一次的执行进行优化查询,但这样要付出一定的优化开销,使用RECOMPILE提示来优化。
ALTER PROCEDURE test (@pid int)
AS
SELECT * FROM Sales.SalesOrderDetail
WHERE ProductID = @pid
OPTION (RECOMPILE)
再次运行存储过程:
EXEC test @pid = 897
<ParameterList>
<ColumnReference Column="@pid" ParameterCompiledValue="(897)" ParameterRuntimeValue="(897)" />
</ParameterList>
这次查询在执行时已经进行优化,根据当前的参数值来生成一个优化的查询。
在先前的旧版本SQL Server中,也采取一些其他的方法实现:使用“本地变量”来替换“参数探测”问题。