
在过去的几年里,Lakehouse作为一种新的数据管理范式,已独立出现在Databricks的许多用户和应用案例中。在这篇文章中,我们将阐述这种新范式以及它相对于之前方案的优势。
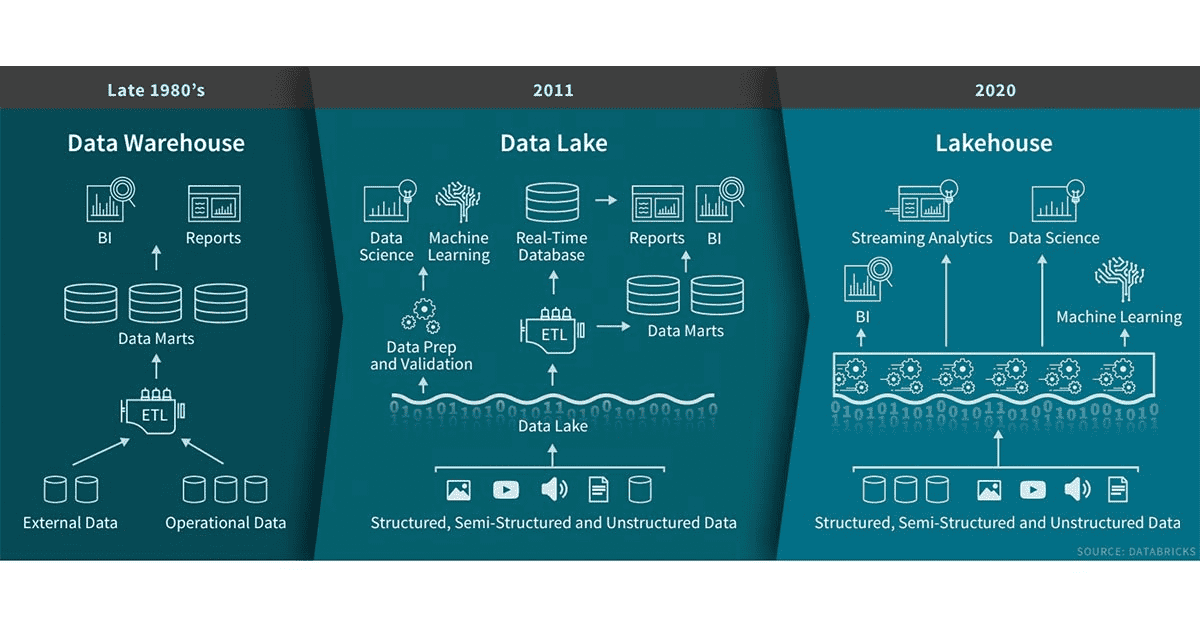
数据仓库在决策支持和商业智能应用方面有着悠久的历史。自20世纪80年代末问世以来,数据仓库技术一直在持续不断的发展,并且MPP体系架构使系统能够处理更大的数据量。尽管数据仓库非常适合处理结构化数据,但是对于很多现代企业,对非结构化数据、半结构化数据以及具有高多样性、高速度、高容量特性的数据处理也往往是必须的,数据仓库并不适用于此类场景的处理,并且成本方面也不是最具效益的。
随着很多公司开始从很多不同的数据源收集大量数据,架构师开始构想通过一个单一的系统来容纳不同分析产品和工作负载的数据。大约十年前,很多公司开始构建数据湖(存储各种格式原始数据的仓库)。虽然数据湖适合存储数据,但缺少一些关键功能(如不支持事务、无法提高数据质量、缺乏一致性/隔离性)导致几乎不可能融合处理数据的追加和读取、批和流处理任务。由于这些原因,数据湖之前的许多承诺没有兑现,并且在许多情况下还会丧失数据仓库原本的很多优势。
很多公司对各类数据应用包括SQL分析、实时监控、数据科学和机器学习的灵活性、高性能系统的需求并未减少。AI的大部分最新进展是有可用于更好处理非结构化数据(如text、images、video、audio)的模型,但这些恰恰是数据仓库未针对优化的数据类型。一种常见的解决方案是使用融合了数据湖、多个数据仓库以及其他的如流、时间序列、图和图像数据库的系统。但是维护这一整套系统是非常复杂的(维护成本相对较高),此外,数据专业人员通常需要跨系统进行数据的移动或复制,这又会导致一定的延迟。
什么是Lakehouse?
Lakehouse是一种结合了数据湖和数据仓库优势的新范式,解决了数据湖的局限性。Lakehouse使用新的系统设计:直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据结构和数据管理功能。如果你现在需要重新设计数据仓库,现在有了廉价且高可靠(以对象存储的格式)的存储可用,不妨考虑使用Lakehouse。
Lakehouse有如下关键特性:
- 事务支持
- 企业内部许多数据管道通常会并发读写数据。对ACID事务的支持确保了多方并发读写数据时的一致性问题
- Schema enforcement and governance
- Lakehouse应该有一种方式可以支持模式执行和演进、支持DW schema的范式(如星星或雪花模型),能够对数据完整性进行推理,并且具有健壮的治理和审计机制
- BI支持
- Lakehouse可以直接在源数据上使用BI工具。这样可以提高数据新鲜度、减少延迟,并且降低了在数据池和数据仓库中操作两个数据副本的成本
- 存储与计算分离
- 在实践中,这意味着存储和计算使用单独的集群,因此这些系统能够扩展到支持更大的用户并发和数据量。一些现代数仓也具有此属性
- 开放性
- 使用的存储格式是开放式和标准化的(如parquet),并且为各类工具和引擎,包括机器学习和Python/R库,提供API,以便它们可以直接有效地访问数据
- 支持从非结构化数据到结构化数据的多种数据类型
- Lakehouse可用于存储、优化、分析和访问许多数据应用所需的包括image、video、audio、text以及半结构化数据
- 支持各种工作负载
包括数据科学、机器学习以及SQL和分析。可能需要多种工具来支持这些工作负载,但它们底层都依赖同一数据存储库
- 端到端流
实时报表是许多企业中的标准应用。对流的支持消除了需要构建单独系统来专门用于服务实时数据应用的需求。
作为企业级的系统,除了要求具有以上特性外,还需要其他额外的功能特性。比如安全和访问控制工具是基本要求。特别是考虑到最近的隐私法规,数据治理功能变得至关重要(包括审计、保留和血缘关系)。对于数据发现工具,例如数据catalog和数据使用metrics也是需要的。
通过使用Lakehouse,这些企业功能特性只需要在一个系统中就能达到实现、测试和管理的目的。
早期示例
Databricks平台具有Lakehouse的特性。
微软的Azure Synapse Analytics服务与Azure Databricks集成,可实现类似Lakehouse模式。其他托管服务(例如BigQuery和Redshift Spectrum)具有上面列出的一些LakeHouse功能特性,但它们是主要针对BI和其他SQL应用。对于想要构建和实现自己系统的公司,可参考适合构建Lakehouse的开源文件格式(Delta Lake,Apache Iceberg,Apache Hudi)。
将数据湖和数据仓库合并至一个系统可以避免数据团队不必要的跨多个系统进行数据的访问,从而提高效率。对于大多数企业数据仓库来说,这些早期的Lakehouse中的SQL支持和与BI工具的集成级别通常已经能够满足需求。虽然可以使用物化视图和存储过程,但用户可能需要使用其他与传统数据仓库中的机制不同的机制。后者对于"lift and shift scenarios"(要求系统实现与旧的商业数据仓库几乎相同的语义)尤为重要。
Lakehouse对其他类型数据应用的支持又如何呢?Lakehouse的用户可以使用各种标准工具(Spark,Python,R,机器学习库)来处理像数据科学和机器学习等非BI工作负载。数据探索和精化是许多分析和数据科学应用的标准。Delta Lake的设计目的是让用户逐步提高Lakehouse中数据质量,直到数据可以使用为止(关于Delta Lake,建议阅读:
https://databricks.com/blog/2020/02/24/introducing-databricks-ingest-easy-data-ingestion-into-delta-lake.html)。
虽然分布式文件系统可以用于存储层,但对象存储在Lakehouse中更为常见。对象存储提供低成本、高可用的存储,在大规模并发读取方面表现出色,这是现代数据仓库的基本要求。
从BI到AI
Lakehouse是一种新的数据管理范式,它从根本上简化了企业数据基础设施,并且有望在机器学习即将颠覆每个行业的时代加速创新。过去,公司产品或决策过程中涉及的大多数数据都是来自操作系统的结构化数据,而如今,许多产品以计算机视觉和语音模型、文本挖掘等形式将AI融入其中。为什么要用Lakehouse而不是数据湖来进行AI?Lakehouse提供了数据版本控制、治理、安全性和ACID属性,即使是非结构化数据也需要这些属性。
当前Lakehouse降低了成本,但其性能仍可能落后于拥有多年投资和实际部署的专业系统(如数据仓库)。用户可能更喜欢某些工具(BI工具、IDEs, notebooks),因此Lakehouse还需要改进其用户体验和与流行工具的连接,以便更具吸引力。随着技术的不断发展和成熟,这些问题将得到解决。随着时间的推移,Lakehouse将缩小这些差距,同时保留更简单、更具成本效益和更能为多种数据应用服务的核心特性。
本文参译于:
https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html —— by Ben Lorica, Michael Armbrust, Ali Ghodsi, Reynold Xin and Matei Zaharia Posted in Company Blog | January 30, 2020
关注微信公众号:大数据学习与分享,获取更对技术干货