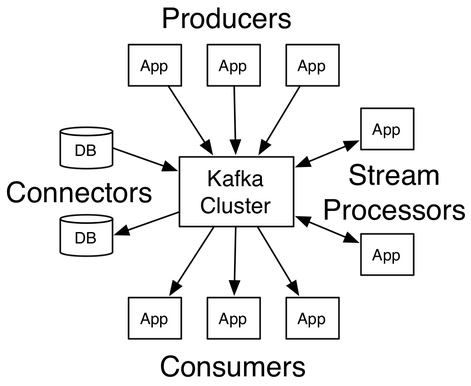
提到Kafka很多人的第一印象就是它是一个消息系统,但Kafka发展至今,它的定位已远不止于此,而是一个分布式流处理平台。对于一个流处理平台通常具有三个关键能力:
1. 发布和订阅消息流,在这一点上它与消息队列或企业消息系统类似
2. 以容错的持久化方式存储消息流
3. 在消息流产生时处理它们
目前,Kafka通常应用于两大类应用:
1. 构建实时的流数据管道,可靠地在系统和应用程序之间获取数据
2. 构建实时流的应用程序,对数据流进行转换或响应
下面我们来一起看一下,Kafka是如何实现以上所说的功能的?首先了解Kafka几个特性:
-
Kafka作为一个集群运行在一个或多个服务器上,这些服务器可以跨越多个数据中心
-
Kafka集群存储的数据流是以topic为类别的
- 每个消息(也叫记录record)是由一个key,一个value和一个时间戳构成
Kafka四个核心API
-
Producer API,允许应用程序发布消息到1个或多个topic
-
Consumer API,允许应用程序订阅一个或多个topic,并处理它们订阅的消息
-
Streams API,允许应用程序充当一个流处理器,从1个或多个topic消费输入流,并产生一个输出流到1个或多个输出topic,有效地将输入流转换到输出流
- Connector API,允许构建运行可重复使用的生产者或消费者,将topic和现有的应用程序或数据系统连接起来。例如,一个关系型数据库的连接器可以捕获到该库下每一个表的变化
Client和Server之间的通讯,是通过一条简单的、高性能支持多语言的TCP协议。并且该协议保持与老版本的兼容。Kafka提供了Java客户端。除了Java 客户端外,客户端还支持其他多种语言。
Topic和Log
Topic是发布的消息的类别名,可以用来区分来自不同系统的消息。Kafka中的topic可以有多个订阅者:即一个topic可以有零个或多个消费者订阅消费消息。
对于每一个topic,Kafka集群维护一个分区日志,如下图:
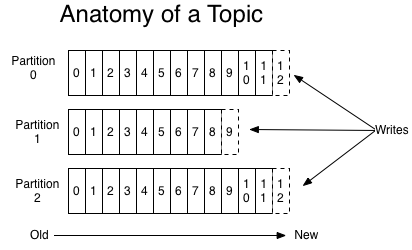
每一个分区都是一个顺序的、不可变的序列数据, 并且不断的以结构化的提交log方式追加。分区中的每条消息都被分配了称之为offset的序列号,在每个分区中offset是唯一的,通过它可以定位一个分区中的唯一一条记录。 无论消息是否被消费,Kafka集群都会持久的保存所有发布的消息,直到过期。Kafka的性能和数据大小无关,所以长时间存储数据没有什么问题。
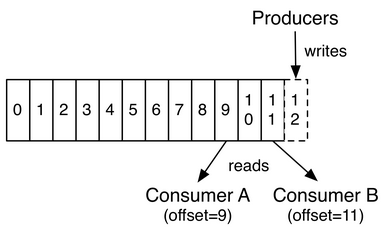
实际上,每个消费者所持有的仅有的元数据就是offset,也就是消费者消费在这个log中的位置。这个offset由消费者控制:一般情况下,当消费者消费消息的时候,offset随之线性的增加。但是因为实际offset由消费者控制,消费者可以任意指定它的消费位置。同时,一个消费者消费消息不会影响其他的消费者。
Kafka中采用分区的设计主要有两个目的:第一,当日志大小超过了单台服务器的限制,允许日志进行扩展。每个单独的分区都必须受限于主机的文件限制,不过一个主题可能有多个分区,因此可以处理大量的数据。第二,分区可以作为并行处理的单元。
分布式
log的分区被分布到集群中的多个服务器上。每个服务器处理它分到的分区,根据配置每个分区还可以有多个副本作为备份容错。
每个分区有一个leader,零个或多个follower。leader处理此分区的所有读写请求,而follower被动的同步leader数据。如果leader宕机,其它的一个follower会被推举为新的leader。一台服务器可能同时是一个分区的leader,另一个分区的follower。这样可以在集群中进行负载均衡,避免所有的请求都只让一台或者某几台服务器处理。
Geo-Replication
Kafka MirrorMaker为集群提供了geo-replication即异地数据同步技术的支持。借助MirrorMaker,消息可以跨多个数据中心或云区域进行复制。你可以在active/passive场景中用于备份和恢复; 或者在active/active场景中将数据置于更接近用户的位置,或者支持数据本地化。
生产者
生产者可以采用轮询、随机等策略来决定将数据发布到所选择的topic中的某个partition上。
消费者
消费者使用一个消费者组名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例,消费者实例可以分布在多个进程中或者多个机器上。
如果所有的消费者实例在同一个消费者组中,消息记录会负载平衡到每一个消费者实例。
如果所有的消费者实例在不同的消费者组中,每条消息记录会广播到所有的消费者进程。
如图,这个Kafka集群有两台server,四个分区和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
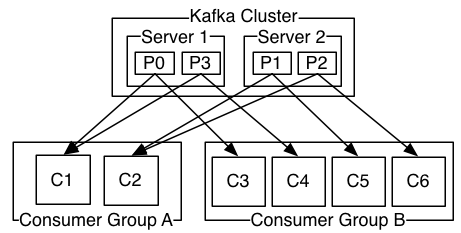
通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个"逻辑订阅者"。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。
在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费者组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
Kafka只保证分区内的记录是有序的,而不保证topic中不同分区的顺序。如果想保证全局有序,那么只能有一个分区,但是这样处理的性能会大幅降低。
Kafka的几个确定性
1. 生产者发送消息到特定的topic的分区上,消息将会按照它们发送的顺序依次追加,也就是说,如果一个消息M1和M2使用相同的producer发送,M1先发送,那么M1将比M2的offset小,并且优先的出现在日志中
2. 消费者消费的消息也是按照消息在日志中存储的顺序
3. 如果一个topic配置了复制因子为N, 那么可以允许N-1台服务器宕机而不丢失任何已经提交的消息
Kafka作为一个消息系统
传统的消息系统有两种模式:队列和发布-订阅。在队列模式中,很多消费者从服务器读取消息并且每个消息只被其中一个消费者读取;在发布-订阅模式中消息则被广播给所有的消费者。这两种模式都有优缺点,队列的优点是允许多个消费者瓜分处理数据,这样可以扩展处理。但是,队列不支持多个订阅者,一旦消费者读取该消息后,该消息就没了。而发布-订阅允许你广播数据到多个进程,但是无法进行扩展处理,因为每条消息都会发送给所有的订阅者。
Kafka中消费者组有两个概念:在队列中消费者组允许同名的消费者组成员瓜分处理;在发布订阅中允许你广播消息给多个消费者组。
Kafka的优势在于每个topic都支持扩展处理以及允许多订阅者模式。
Kafka有比传统的消息系统更强的顺序保证
传统的消息系统按顺序保存数据,如果多个消费者从队列消费,则服务器按存储的顺序发送消息,尽管服务器按顺序发送,但消息是异步传递到消费者,因此消费者消费到的消息可能是无序的。这意味着在并行消费的情况下,顺序就无法保证。消息系统常常通过仅设1个消费者来解决这个问题,但是这意味着无法并行处理数据,性能也就相应降低。
Kafka中的partition就是一个并行处理单元。Kafka通过将topic中的一个partition分配给消费者组中的一个消费者进行消费,保证了消费的顺序保证和负载均衡。但是Kafka只能保证一个partition被顺序消费,并不能保证全局有序消费,除非只有一个partition。此外,相同的消费者组中如果有比分区数更多的消费者,则多出的消费者会处于空闲状态,不处理消息。
Kafka作为一个存储系统
写入到Kafka的数据会被写到磁盘并且备份以保证容错性,并可以通过应答机制,确保消息写入。
Kafka使用的磁盘结构,具有很好的扩展性,使得50kb和50TB的数据在服务器上表现一致。你可以认为kafka是一种高性能、低延迟的提交日志存储、备份和传播功能的分布式文件系统,并且可以通过客户端来控制读取数据的位置。
Kafka的流处理
Kafka流处理不仅仅用来读写和存储流式数据,它最终的目的是为了能够进行实时的流处理。
在Kafka中,流处理持续获取输入topic的数据,进行处理加工,然后写入输出topic。例如,一个零售APP,接收销售和出货的输入流,统计数量或调整价格后输出一系列流数据。
可以直接使用producer和consumer API进行简单的处理。但是对于复杂的数据转换,Kafka提供了更强大的streams API,可用于构建聚合计算或join多个流。这一功能有助于解决此类应用面临的硬性问题:如处理无序的数据,消费者代码更改的再处理,执行状态计算等。
sterams API建立在Kafka的核心之上:使用producer和consumer API作为输入,利用Kafka做状态存储,使用相同的消费者组机制在流处理器实例之间进行容错保障。
写在最后
消息传递、存储和流处理的组合是Kafka作为流式处理平台的关键特性。
像HDFS这样的分布式文件系统允许存储静态文件来进行批处理。这样系统可以有效地存储和处理历史数据。而传统的企业消息系统允许在你订阅之后处理将来的数据,并在这些数据到达时处理它。Kafka结合了这两种能力,这种组合对于Kafka作为流处理应用和流数据管道平台是至关重要的。
通过消息存储和低延迟订阅,流应用程序可以以同样的方式处理历史和将来的数据。一个单一的应用程序可以处理历史数据,并且可以持续不断地处理以后到达的数据,而不是在到达最后一条记录时就结束进程。这是一个广泛的流处理概念,其中包含批处理以及消息驱动应用程序。
同样,作为流数据管道,能够订阅实时事件使得Kafk具有非常低的延迟;同时Kafka还具有可靠存储数据的特性,可用来存储重要的支付数据或者与离线系统进行交互,系统可间歇性地加载数据,也可在停机维护后再次加载数据。流处理功能使得数据可以在到达时转换数据。
关注微信公众号:大数据学习与分享,获取更对技术干货