提起大数据,不得不提由IBM提出的关于大数据的5V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性),而对于大数据领域的从业人员的日常工作也与这5V密切相关。大数据技术在过去的几十年中取得非常迅速的发展,尤以Hadoop和Spark最为突出,已构建起庞大的技术生态体系圈。
首先通过一张图来了解一下目前大数据领域常用的一些技术,当然大数据发展至今所涉及技术远不止这些。
BigData Stack:
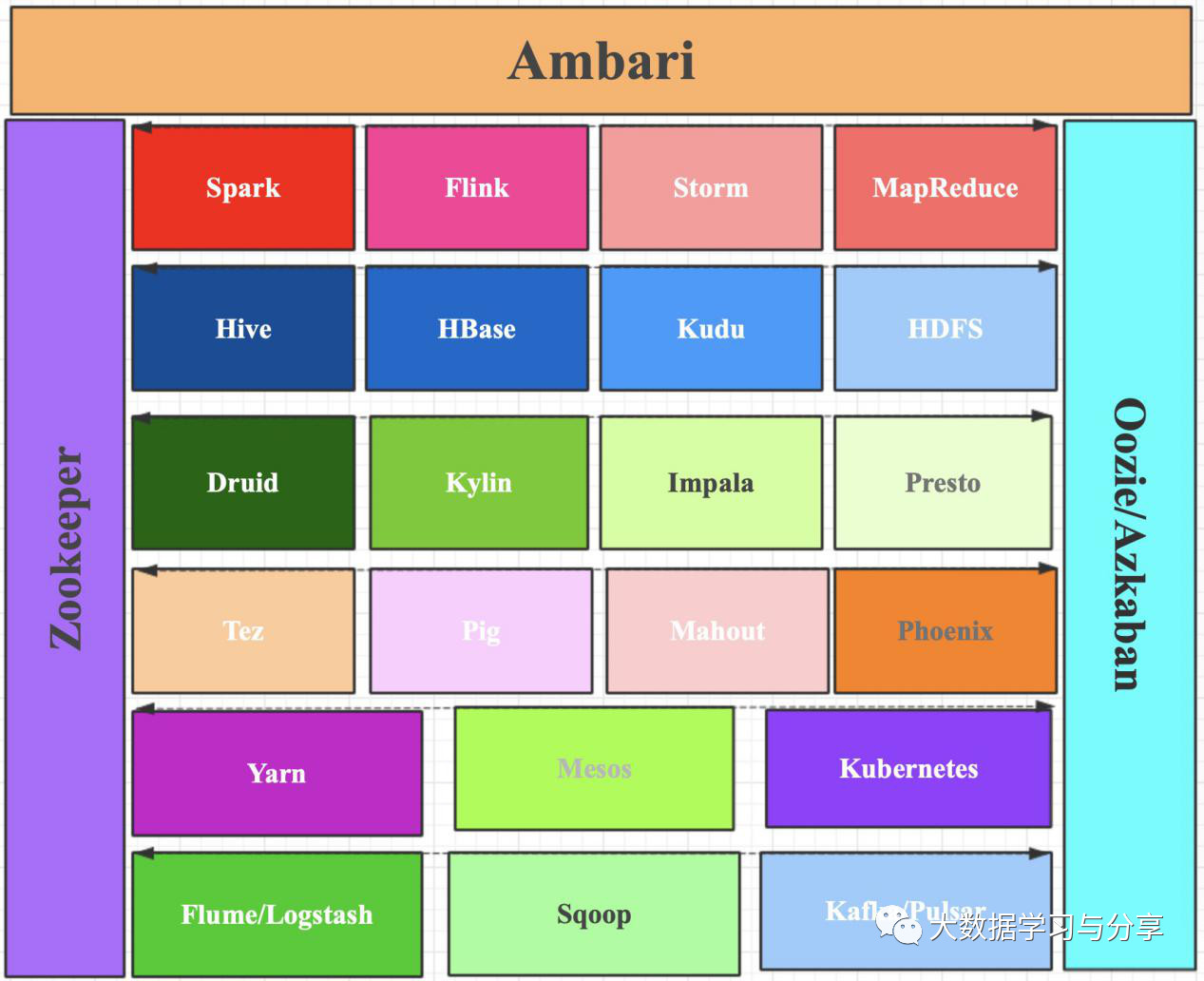
下面分不同层介绍各个技术,当然各个层并不是字面意义上的严格划分,如Hive既提供数据处理功能也提供数据存储功能,但此处将其划为数据分析层中
1. 数据采集和传输层
- Flume
Flume一个分布式、可靠的、高可用的用于数据采集、聚合和传输的系统。常用于日志采集系统中,支持定制各类数据发送方用于收集数据、通过自定义拦截器对数据进行简单的预处理并传输到各种数据接收方如HDFS、HBase、Kafka中。之前由Cloudera开发,后纳入Apache -
Logstash
ELK工作栈的一员,也常用于数据采集,是开源的服务器端数据处理管道 - Sqoop
Sqoop主要通过一组命令进行数据导入导出的工具,底层引擎依赖于MapReduce,主要用于Hadoop(如HDFS、Hive、HBase)和RDBMS(如mysql、oracle)之间的数据导入导出 - Kafka
分布式消息系统。生产者(producer)——消费者(consumer)模型。提供了类似于JMS的特性,但设计上完全不同,不遵循JMS规范。如kafka允许多个消费者主动拉取数据,而JMS中只有点对点模式消费者才会主动拉取数据。主要应用在数据缓冲、异步通信、汇集数据、系统接偶等方面 -
Pulsar
pub-sub模式的分布式消息平台,拥有灵活的消息模型和直观的客户端API。类似于Kafka,但Pulsar支持多租户,有着资产和命名空间的概念,资产代表系统里的租户。假设有一个Pulsar集群用于支持多个应用程序,集群里的每个资产可以代表一个组织的团队、一个核心的功能或一个产品线。一个资产可以包含多个命名空间,一个命名空间可以包含任意个主题
2. 数据存储层
- HBase
基于Google Bigtable的开源实现,是一个具有高可靠性、高性能、面向列、可伸缩性、典型的key/value分布式存储的nosql数据库系统,主要用于海量结构化和半结构化数据存储。它介于nosql和RDBMS之间,仅能通过行键(row key)和行键的range来检索数据,行数据存储是原子性的,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。HBase查询数据功能很简单,不支持join等复杂操作,不支持跨行和跨表事务 - Kudu
介于HDFS和HBase之间的基于列式存储的分布式数据库。兼具了HBase的实时性、HDFS的高吞吐,以及传统数据库的sql支持 -
HDFS
分布式文件存储系统,具有高容错(high fault-tolerant)、高吞吐(high throughput)、高可用(high available)的特性。HDFS非常适合大规模数据集上的应用,提供高吞吐量的数据访问,可部署在廉价的机器上。它放宽了POSIX的要求,这样可以实现流的形式访问(文件系统中的数据。主要为各类分布式计算框架如Spark、MapReduce等提供海量数据存储服务,同时HDFS和HBase底层数据存储也依赖于HDFS
3. 数据分析层
- Spark
Spark是一个快速、通用、可扩展、可容错的、内存迭代式计算的大数据分析引擎。目前生态体系主要包括用于批数据处理的SparkRDD、SparkSQL,用于流数据处理的SparkStreaming、Structured-Streaming,用于机器学习的Spark MLLib,用于图计算的Graphx以及用于统计分析的SparkR,支持Java、Scala、Python、R多种数据语言 - Flink
分布式的大数据处理引擎,可以对有限数据流和无线数据流进行有状态的计算。Flink在设计之初就是以流为基础发展的,然后再进入批处理领域,相对于spark而言,它是一个真正意义上的实时计算引擎 - Storm
由Twitter开源后归于Apache管理的分布式实时计算系统。Storm是一个没有批处理能力的数据流处理计算引擎,storm提供了偏底层的API,用户需要自己实现很多复杂的逻辑 - MapReduce
分布式运算程序的编程框架,适用于离线数据处理场景,内部处理流程主要划分map和reduce两个阶段 - Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供HQL语句(类SQL语言)查询功能,存储依赖于HDFS。支持多种计算引擎,如Spark、MapReduce(默认)、Tez;支持多种存储格式,如TextFile、SequenceFile、RCFile、ORC、Parquet(常用);支持多种压缩格式,如gzip、lzo、snappy(常用)、bzip2 - Tez
支持DAG作业的开源计算框架。相对于MapReduce性能更好,主要原因在于其将作业描述为DAG(有向无环图),这一点与Spark类似 - Pig
基于Hadoop的大规模数据分析平台,它包含了一种名为Pig Latin的脚本语言来描述数据流,并行地执行数据流处理的引擎,为复杂的海量数据并行计算提供了一个简单的操作和编程接口。Pig Latin本身提供了许多传统的数据操作,同时允许用户自己开发一些自定义函数用来读取、处理和写数据,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算 -
Mahout
提供一些可扩展的机器学习领域经典算法的实现,Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。通过使用Apache Hadoop 库,可以将Mahout扩展到云中 -
Phoenix
构建在HBase之上的一个SQL层,能让我们通过标准的JDBC API操作HBase中的数据。Phoenix完全使用Java编写,作为HBase内嵌的JDBC驱动。Phoenix查询引擎会将SQL查询转换为一个或多个HBase scan,并编排执行以生成标准JDBC结果集
4. OLAP引擎
- Druid
开源的、基于列存储的、分布式的,适用于实时数据分析的存储系统,能够快速聚合、灵活过滤、毫秒级查询和低延迟数据导入。通过使用Bitmap indexing加速列存储的查询速度,并使用CONCISE算法来对bitmap indexing进行压缩,使得生成的segments比原始文本文件小很多,并且它的各个组成部分之间耦合性低,如果不需要实时数据完全可以忽略实时节点 - Kylin
最初由eBayInc.开发并贡献至开源社区的分布式分析引擎。提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的Hive表。需要使用者对数仓模型有深度了解,并需构建cube。能够与多种可视化工具,如Tableau,PowerBI等,令用户可以使用BI工具对Hadoop数据进行分析 - Impala提供对HDFS、HBase等数据的高性能、低延迟的交互式SQL查询功能的大数据查询分析引擎,由Cloudera开源。它基于Hive,使用Hive的元数据在内存中计算,具有实时、批处理、高并发等优点
-
Presto
开源的分布式大数据SQL查询引擎,适用于交互式分析查询。可以将多个数据源的数据进行合并,并且可以直接从HDFS读取数据,在使用前不需要大量的ETL操作
5. 资源管理层
- Yarn
Yarn是一个资源调度平台,负责为运算程序分配资源和调度,不参与用户程序内部工作。核心组件包括:ResourceManager(全局资源管理器,负责整个系统的资源管理和分配)、NodeManager(每个节点上的资源和任务管理器) - Kubernetes
又称K8s,为容器化的应用提供资源调度、部署运行、均衡容灾、服务注册、扩容缩容等功能的自动化容器操作的开源平台。具体体现在:自动化容器的部署和复制、随时扩展或收缩容器规模、将容器组织成组,并且提供容器间的负载均衡等。Kubernetes支持docker和Rocket,可以将Docker看成Kubernetes内部使用的低级别组件 -
Mesos
类似于Yarn,也是一个分布式资源管理平台,为MPI、Spark作业在统一资源管理环境下运行。它对Hadoop2.0支持很好,但国内用的不多
6. 工作流调度器
- Oozie
基于工作流引擎的任务调度框架,能够提供能够提供对MapReduce和Pig 任务的调度与协调
-
Azkaban
由LinkedIn开源,相对Oozie更轻量级。用于在一个工作流内以一个特定顺序运行一组任务,通过一种kv文件格式来建立任务之间的依赖关系并为用户提供了易于使用的web界面来维护和跟踪允许任务的工作流
7. 其他
- Ambari
基于web的安装部署工具,支持对大多数的Hadoop组件,如HDFS、MapReduce、Hive、Pig、HBase等的管理和监
- Zookeeper
分布式协调服务即为用户的分布式应用程序提供协调服务,如主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁等,它本身也是一个分布式程序(部署奇数台,只要由半数以上zookeeper节点存活,zookeeper集群就能正常提供服务),它是Google Chubby一个开源实现
关注微信公众号:大数据学习与分享,获取更多技术干货