
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解!
01 hive知识点(1)
第1点:数据仓库的概念
由于hive它是基于hadoop的一个数据仓库工具,老刘先讲讲数据仓库的一些东西,再开始讲hive。
数据仓库,听名字就知道它是用来存放数据的一个仓库,仓库不同于工程,仓库只用来存放东西,不生产,也不消耗。
精简的讲,数据仓库它本身不生产数据,也不会消耗数据,数据从外部来,供给外部使用,主要用于数据分析,对企业的支持决策做一些辅助。
第2点:数据仓库的特征
数据仓库有4个特征:
面向主题的:就是说它都是有目的的进行构建数据仓库,用它干某件事;
集成的:就是说将所有用到的数据都集成到一起;
非易失的:就是说里面的数据一般都不会改变;
时变的:就是说随着时间的发展,数据仓库的分析手段也会发生改变。
第3点:数据仓库和数据库的区别
看到之前讲的数据仓库概念就知道,这两个区别大了。
首先举个例子,客户在银行做的每笔交易都会写入数据库,被记录下来,就相当于用数据库记账。
而数据仓库是分析系统的数据平台,它从事务系统获取数据,并做汇总、加工,为决策者提供决策的一些依据。
比如,某银行某分行一个月发生多少交易,该分行当前存款余额是多少。如果存款又少,消费交易又多,那么该地区就有必要设立ATM了。
接着要说的是,数据库和数据仓库的区别实际上讲的是OLTP和OLAP的区别。
操作性处理,OLTP联机事务处理,也可以叫做面向交易的处理系统,它是针对于具体业务在数据库联机的日常操作,通常对记录进行查询、修改,人们一般关心操作的响应时间、数据是否安全、完整和并发的相关问题。
分析型处理,联机分析处理OLAP,一般针对于某些主题的历史数据进行分析,支持管理决策。
总结一下就是,数据仓库的出现,不是为了取代数据库。
数据库是面向事务的设计,数据仓库是面向主题的设计。
数据库存储的一般是业务数据,数据仓库存储的一般是历史数据。
数据库是为了捕获数据设计的,而数据仓库是为了分析数据设计的。
还有一点就是,数据仓库是在数据库已经大量存在的情况下,为了进一步挖掘数据资源,为了进行决策而产生的。
第4点:数据仓库分层
首先说说数据仓库可分为三层:
源数据层(ODS):它主要用于保管我们的原始数据;
数据仓库层(DW):它主要对源数据层过来的数据进行清洗,然后用于数据分析,大部分工作都是在这一层写sql;
数据应用层(APP):它主要用于数据的各种展示。
那为什么要进行数据仓库分层呢?
首先想想,一个非常复杂的问题,我们一般怎么解决,是不是通常把一个复杂的问题,分解成很多小问题,每个小问题相对于这个大问题,是不是相对容易点。
总结一下就说,对数据仓库进行分层,相当于把一个复杂的工作拆成多个简单的工作,每一层的处理逻辑相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,就算数据出现错误,我们也可以相对容易找到哪里出错,快速纠正错误。
进行数据仓库分层,达到了用空间换时间的效果,通过大量的预处理提升系统的效率。
第5点:hive是什么

简单一句话,由于mapreduce代码非常复杂,hive就是一个把SQL语句转换为mapreduce任务的工具,通过hive大大简化了mr的开发。
也可以这样说,hive的主要的工作就是将我们写的sql语句翻译成为mr的任务,运行在yarn上面,hive可以简单的理解为mr的客户端
第6点:hive和数据库的区别
区别太多了只说一点,Hive 不支持记录级别的增删改操作。
早期的版本,hive不支持,增删改,只支持查询操作,现在的版本,都支持。
但是实际工作当中不会用到增删改,只会用到查询操作select。
剩下的,大家自己去搜搜。
hive它只具有SQL数据库的外表,但应用场景完全不同。由于执行器MapReduce执行速度特别慢,hive只能做离线数据的处理。
第7点:hive的架构
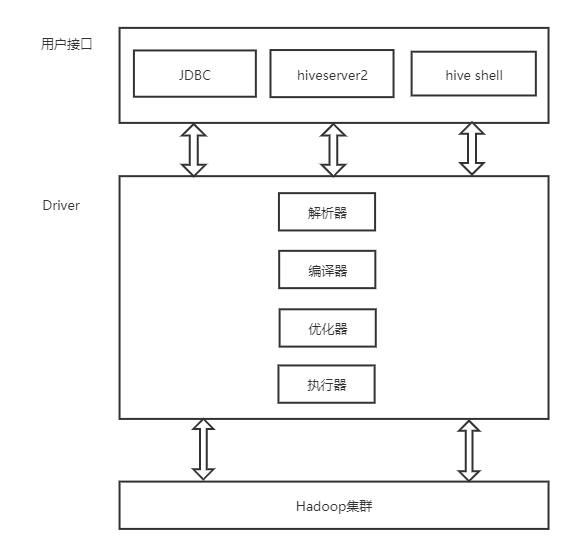
用户接口:提供用户通过各种方式来访问hive,可以通过jdbc,可以通过hiveserver2,还可以通过hive shell;
解析器:主要就是用于解析sql语法;
编译器:将解析之后的sql语法进行编译成为MR的任务;
优化器:有一定的优化功能,自动的会对我们写的sql语句进行调优,调优的功能有限的;
执行器:提交mr的任务到yarn上面去执行的;
底层的hadoop:数据存储hdfs,数据的计算mr,运行在yarn上面的。
第8点:hive的数据类型

第9点:hive的DDL操作
可能会有人认为hive的DDL操作,以后直接百度或者翻资料就行,压根不用记,但是在老刘看来,至少要记住几个常用的命令,万一哪天别人问,自己想不起来,还要去百度搜一下,多尴尬啊!
首先说说hive的数据库操作:
1、创建数据库 create database if not exists db_hive; 2、显示所有数据库 show databases; 3、查询数据库 show databases like 'gmall'; 4、查看数据库详情 desc database gmall; 5、显示数据库详细信息 desc database extended gmall; 6、切换当前数据库 use gmall; 7、删除数据库 如果删除的数据库不存在,最好采用if exists 判断数据库是否存在 drop database if exists gmall; 如果数据库中有表存在,这里需要使用cascade强制删除数据库 drop database if exists gmall cascade;
接下里说说hive的DDL操作:
它有一个建表的语法,如果直接看这个语法,老刘不建议直接看,通过例子慢慢了解,查漏补缺最好。
hive建表分为内部表和外部表,首先讲创建内部表。
1、直接建表 先切换到自己要用的数据库 use myhive; create table stu(id int,name string); 2、通过AS 查询语句完成建表:将子查询的结果存在新表里,有数据 create table if not exists myhive.stu1 as select id, name from stu; 3、根据已经存在的表结构创建表 create table if not exists myhive.stu2 like stu; 4、查询表的类型 desc formatted myhive.stu;
根据查询表的类型,可以得到这张图,这张图包含了很多信息,后续会慢慢讲述到,大家放心!

一般最常用的就是创建内部表并指定字段之间的分隔符,指定文件的存储格式,以及数据存放的位置,注意这个数据存放的位置指的是在HDFS上的存储位置,千万不要记错了,老刘最开始就记错了!
创建的代码如下:
create table if not exists myhive.stu3(id int ,name string) row format delimited fields terminated by ' ' stored as textfile location '/user/stu2';
现在开始创建外部表,首先要知道什么是外部表,和内部表有什么区别?
外部表因为是指定其他的hdfs路径的数据加载到表当中来,所以hive表会认为自己不完全独占这份数据,所以删除hive表的时候,数据仍然存放在hdfs当中,不会删掉。
创建外部表的时候需要加上external关键字,location字段可以指定,也可以不指定,指定就是数据存放的具体目录,不指定就是使用默认目录 /user/hive/warehouse。
创建代码如下:
create external table myhive.teacher (t_id string,t_name string) row format delimited fields terminated by ' ';

总结一下内部表与外部表的区别:
1、外部表在创建的时候需要加上external关键字。
2、内部表删除后,表的元数据和真实数据都被删除了;但是外部表删除后,仅仅只是把该表的元数据删除了,真实数据还在,后期还是可以恢复出来。
那我们一般什么时候使用内部与外部表呢?
由于内部表删除表的时候会同步删除HDFS的数据文件,所以如果我们确定一个表仅仅是我们自己独占使用,其他人不适用的时候就可以创建内部表,如果一个表的文件数据,其他人也要使用,那么就创建外部表。
一般外部表都是用在数据仓库的ODS层,内部表都是用在数据仓库的DW层。
那表创建好之后,如何把数据导进去呢?一般使用load的方式来加载数据到内部表或者外部表,不用insert。
load数据可以从本地文件系统加载或者也可以从hdfs上面的数据进行加载,注意本地系统指的是linux系统。
① 从本地系统加载数据到表里面
首先创建在本地系统创建一个文件,把数据表上传到这个文件里,然后在把这个文件上传到表里。
mkdir -p /kkb/install/hivedatas load data local inpath '/kkb/install/hivedatas/teacher.csv' into table myhive.teacher;
注意,本地系统导入要加上一个local;
② 从hdfs上面导入数据
首先在hdfs上创建一个目录,把数据文件上传上去,然后在把这个文件上传到表里。
hdfs dfs -mkdir -p /kkb/hdfsload/hivedatas hdfs dfs -put teacher.csv /kkb/hdfsload/hivedatas # 在hive的客户端当中执行 load data inpath '/kkb/hdfsload/hivedatas' overwrite into table myhive.teacher;
第10点:hive的分区表
Hive中的分区就是分目录,把表的数据分目录存储,存储在不同的文件夹下,后期按照不同的目录查询数据,不需要进行全量扫描,提升查询效率。
创建分区表语法:
create table score(s_id string,c_id string, s_score int) partitioned by (month string) row format delimited fields terminated by ' ';
创建一个表多个分区:
create table score2 (s_id string,c_id string, s_score int) partitioned by (year string,month string,day string) row format delimited fields terminated by ' ';
接下来就是把数据加载到分区表中,老刘觉得这些需要掌握,大家认真点!加载数据到分区表当中去
load data local inpath '/kkb/install/hivedatas/score.csv' into table score partition (month='201806');
加载数据到多分区表当中去
load data local inpath '/kkb/install/hivedatas/score.csv' into table score2 partition(year='2018',month='06',day='01');
第11点:综合练习
这一点是老刘唯一觉得一些资料上讲的不错的地方,在经历了大量的基础DDL操作后,能加速记住这些操作的唯一方法就是做一个小练习,下面就是关于hive基础操作的一个小练习。
需求描述:现在有一个文件score.csv文件,里面有三个字段,分别是s_id string, c_id string,s_score int,字段都是使用 进行分割,存放在集群的这个目录下/scoredatas/day=20180607,这个文件每天都会生成,存放到对应的日期文件夹下面去,文件别人也需要公用,不能移动。需求,创建hive对应的表,并将数据加载到表中,进行数据统计分析,且删除表之后,数据不能删除。
根据这些需求,我们可以知道的是要创建一个外部分区表,但是有意思的是老刘看的资料上,它并不是先建表再导入数据,它是先导入数据后再建立表,非常有意思。
cd /kkb/install/hivedatas/ hdfs dfs -mkdir -p /scoredatas/day=20180607 hdfs dfs -put score.csv /scoredatas/day=20180607/
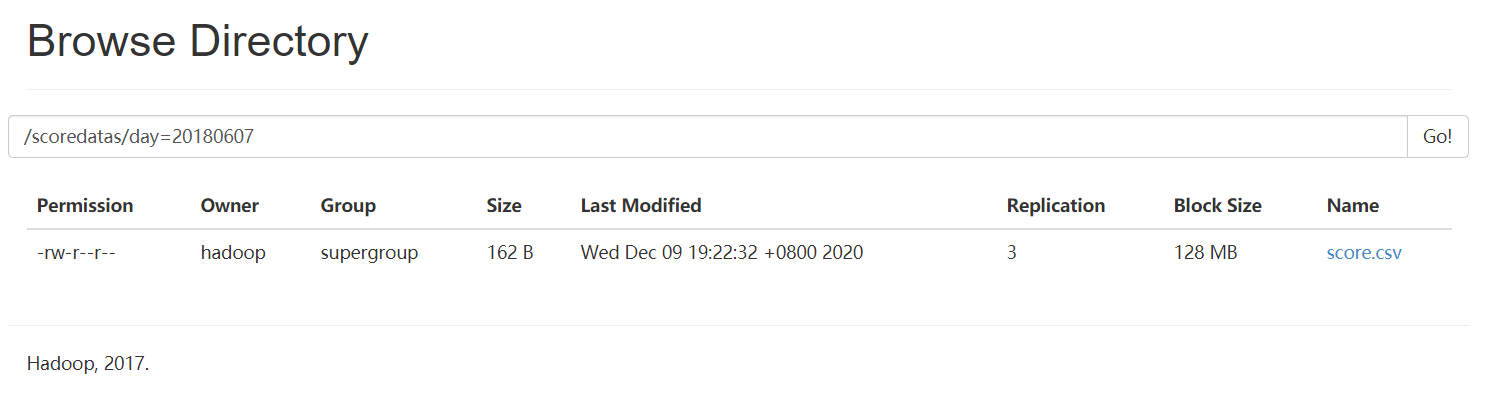 数据文件导入后,再建立外部分区表,并指定文件数据存放目录。
数据文件导入后,再建立外部分区表,并指定文件数据存放目录。
create external table score4(s_id string, c_id string,s_score int) partitioned by (day string) row format delimited fields terminated by ' ' location '/scoredatas';
进行数据查询,发现表里面并没有数据。

是这样的,如果我们先建立分区表再通过load导入数据,表里面肯定会有数据的;
如果直接将文件放在hdfs上面对应的位置,即使我们表指定的存储位置和上传数据的位置一致,但由于mysql里面就没有记录元数据分区的信息,就没有数据,就需要进行修复,刷新mysql元数据信息即可。
有一个知识点就是hive的元数据存在于mysql中,在mysql中会有一个hive库,存放相应的表,一共53张表。

当然就像老刘之前说的,先建立表,在通过load导入数据,表里面是绝对有数据的。
02 总结
hive的知识点主要偏实践,在学习过程中要进行大量的练习,才能真正的掌握。老刘尽量用大白话对hive的第一部分知识点进行了讲解,希望能够帮助到大家。有什么想说的,可以直接联系公众号:努力的老刘!