ClickHouse安装
采用doker安装测试:
拉取服务端
docker pull yandex/clickhouse-server
拉取客户端
docker pull yandex/clickhouse-client
启动ck-server:
docker run -d --name ck-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 -p 9009:9009 yandex/clickhouse-server
进入容器:
docker exec -it ck-server /bin/bash
然后执行:
clickhouse-client
测试查看库以及建表:
建库:
show databases;
创建表并指定表引擎:
create table default.user_table(id UInt16, name String, age UInt16) ENGINE = TinyLog();
常用数据类型
-
整型: 固定长度的整型,包括有符号整型或无符号整型。有符号整型:Int8 - Int64, 无符号整型:UInt8 - UInt64, 使用场景: 个数、数量、也可以存储型 id。
-
浮点型:
Float32 - float
Float64 – double
建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。 -
布尔类型:可以使用 UInt8 类型,取值限制为 0 或 1。
-
Decimal类型: 有符号的浮点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会
Decimal32(s),相当于 Decimal(9-s,s),有效位数为 1~9
Decimal64(s),相当于 Decimal(18-s,s),有效位数为 1~18
Decimal128(s),相当于 Decimal(38-s,s),有效位数为 1~38
使用场景: 一般金额字段、汇率、利率等字段为了保证小数点精度,都使用 Decimal进行存储。 -
字符串 :
String
字符串可以任意长度的。它可以包含任意的字节集,包含空字节。FixedString(N)
固定长度 N 的字符串,N 必须是严格的正自然数。当服务端读取长度小于 N 的字符串时候,通过在字符串末尾添加空字节来达到 N 字节长度。 当服务端读取长度大于 N 的字符串时候,将返回错误消息。
与 String 相比,极少会使用 FixedString,因为使用起来不是很方便。
使用场景:名称、文字描述、字符型编码。 固定长度的可以保存一些定长的内容,比如一些编码,性别等但是考虑到一定的变化风险,带来收益不够明显,所以定长字符串使用意义有限。 -
时间类型:
目前 ClickHouse 有三种时间类型
Date 接受年-月-日的字符串比如 ‘2019-12-16’
Datetime 接受年-月-日 时:分:秒的字符串比如 ‘2019-12-16 20:50:10’
Datetime64 接受年-月-日 时:分:秒.亚秒的字符串比如‘2019-12-16 20:50:10.66’
日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值。 -
枚举类型
包括 Enum8 和 Enum16 类型。Enum 保存 'string'= integer 的对应关系。
Enum8 用 'String'= Int8 对描述。
Enum16 用 'String'= Int16 对描述。
使用场景:对一些状态、类型的字段算是一种空间优化,也算是一种数据约束。但是实
际使用中往往因为一些数据内容的变化增加一定的维护成本,甚至是数据丢失问题。所以谨
慎使用。 -
数组
Array(T):由 T 类型元素组成的数组。
T 可以是任意类型,包含数组类型。 但不推荐使用多维数组,ClickHouse 对多维数组
的支持有限。例如,不能在 MergeTree 表中存储多维数组。• 创建数组方式 1,使用 array 函数 SELECT array(1, 2) AS x, toTypeName(x) ;
• 创建数组方式 2:使用方括号 SELECT [1, 2] AS x, toTypeName(x);
常用的表引擎
表引擎决定了如何存储表的数据。表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关参数
TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表,生产环境上作用有限。可以用于平时练习测试用。
create table t_tinylog ( id String, name String) engine=TinyLog;
Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过 10G/s)。一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概 1 亿行)的场景`
*MergeTree
ClickHouse 中最强大的表引擎当属 MergeTree(合并树)引擎及该系列(*MergeTree)中的其他引擎,支持索引和分区,地位可以相当于 innodb 之于 Mysql
建表语句格式:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2,
...
PROJECTION projection_name_1 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY]),
PROJECTION projection_name_2 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY])
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
[SETTINGS name=value, ...]
建表示例:
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
主键并不唯一,会建索引
order by 是必须的,主键、分区非必须
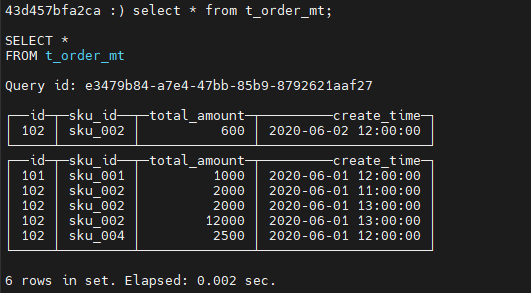
插入数据:
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
查询数据:
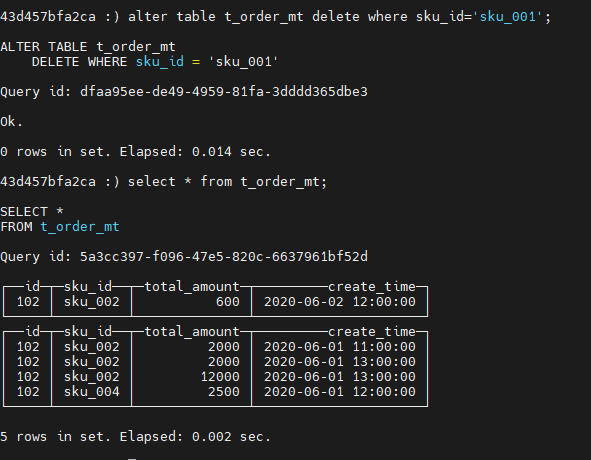
删除数据:
按条件删除:
alter table t_order_mt delete where sku_id='sku_001';
更新数据:
索引列不能进行更新
分布式表不能进行更新
不适合频繁更新或point更新
由于Clickhouse更新操作非常耗资源,如果频繁的进行更新操作,可能会弄崩集群,请谨慎操作。
alter table t_order_mt update total_amount=3000 where sku_id='sku_004';
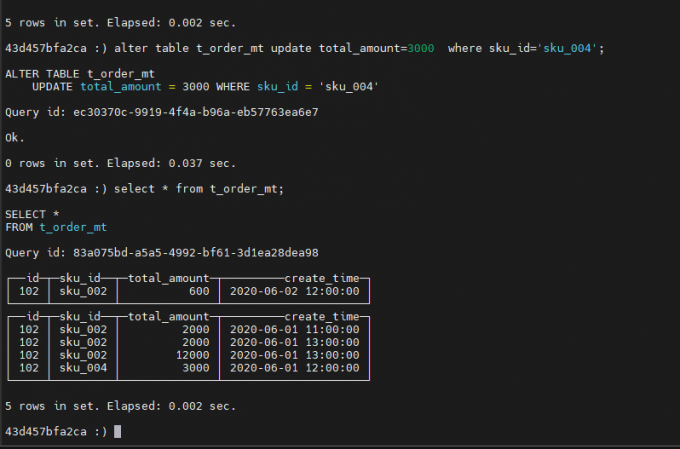
MergeTree 其实还有很多参数(绝大多数用默认值即可),但是三个参数是更加重要的
partition by分区(可选):
1)作用
分区的目的主要是降低扫描的范围,优化查询速度
2)如果不填
只会使用一个分区。(all)
3)分区目录
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文
件就会保存到不同的分区目录中。
4)并行
分区后,面对涉及跨分区的查询统计,ClickHouse 会以分区为单位并行处理。一分区一线程
5)数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作(等不及也可以手动通过 optimize 执行),把临时分区的数据,合并到已有分区中。
optimize table xxxx final;
查看数据存储:
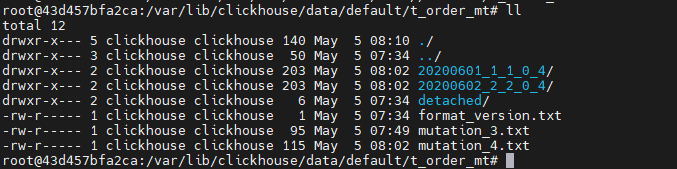
分区文件:
20200601_1_1_0_4/ --> PartitionId_MinBlockNum_MaxBlockNum_Level
PartitionId:
20200601,分区日期
数据分区ID生成规则
数据分区规则由分区ID决定,分区ID由PARTITION BY分区键决定。根据分区键字段类型,ID生成规则可分为:
1. 未定义分区键:
没有定义PARTITION BY,默认生成一个目录名为all的数据分区,所有数据均存放在all目录下
2. 整型分区键:
分区键为整型,那么直接用该整型值的字符串形式作为分区ID
3. 日期类分区键
String、Float类型等,通过128位的Hash算法取其Hash值作为分区ID
MinBlockNum:
最小分区块的编号,自增类型,从1开始向上递增。每产生一个新的目录分区就向上递增一个数字
MaxBlockNum:
最大分区块的编号,新创建的分区MinBlockNum等于MaxBlockNum的编号
Level:
合并的层级,被合并的次数。合并次数越多,层级值越大
分区路径下的内容:
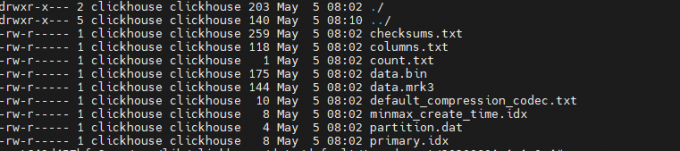
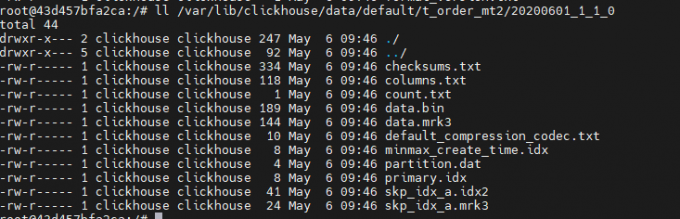
data.bin:数据文件(老版本会有多个数据文件,根据列划分,如:id.bin、sku_id.bin等)
data.mrk3:偏移量(标记文件,可加速查询。老版本会有多个标记文件,如id.mrk3、sku_id.mrk3等,与数据文件对应),在idx索引文件和bin数据文件之间起到了桥梁作用,mrk3结尾的文件,表示该表启用了自适应索引间隔
default_compression_codec.txt:压缩格式
count.txt:记录表的行数
columns.txt:列的信息

checksums.txt:校验文件,用于校验各个文件的正确性。存放各个文件的size以及hash值
primary.idx:主键的索引文件(稀疏索引),用于加快查询效率
partition.dat:分区信息
minmax_create_time.idx:分区键的最小最大值
再次执行插入操作:
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00’);
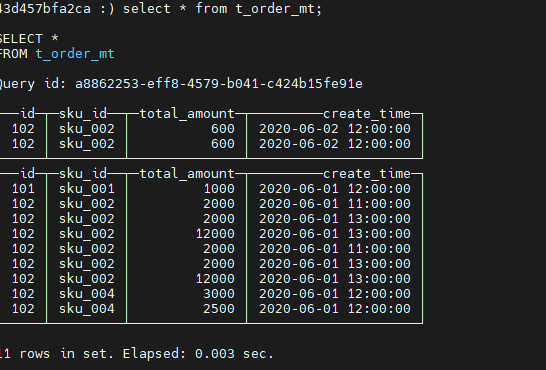
查看数据没有纳入任何分区需要合并:
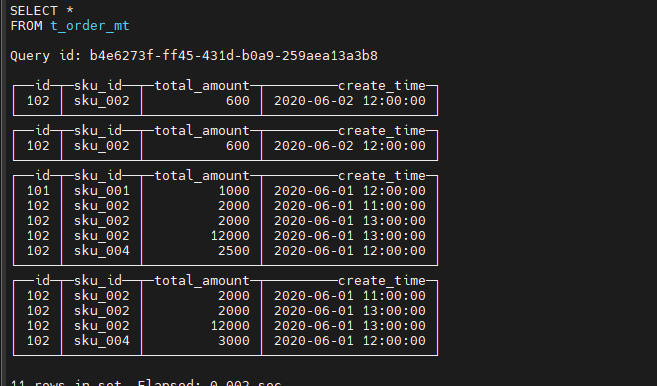
查看分区文件:
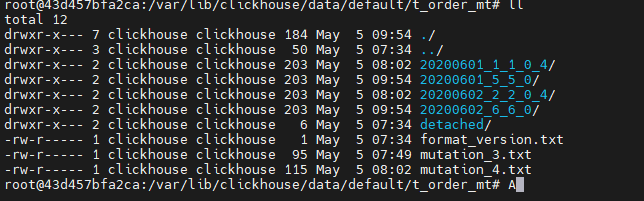
手动合并:
optimize table t_order_mt final;
再次查询:
再次查看数据文件:
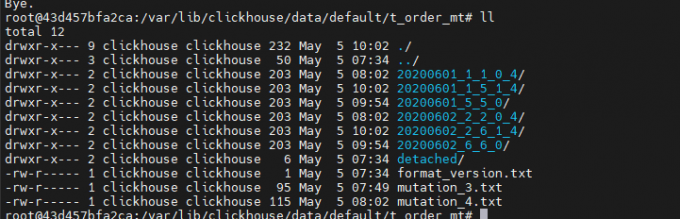
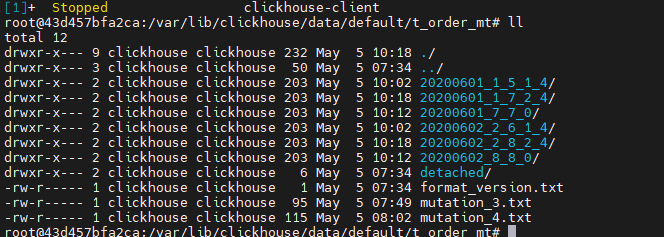
20200601_1_5_1_4/ 是由 20200601_1_1_0_4/ 20200601_5_5_0/ 合并得来的,后期会被清理掉
只合并某一分区:
再次插入数据:
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
查看数据:
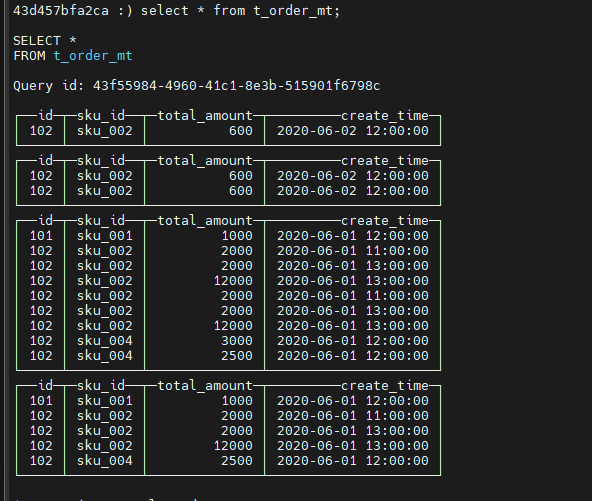
手动只合并指定分区(不行):
optimize table t_order_mt partition '20220601' final;
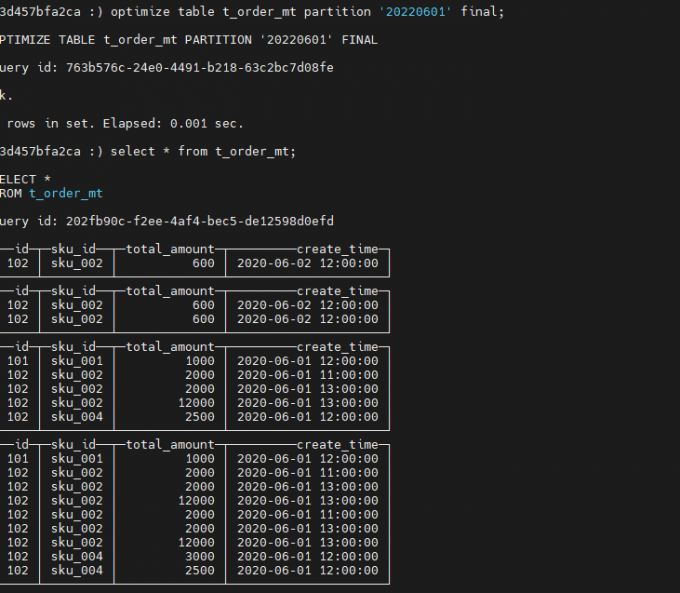
再次手动合并全表:
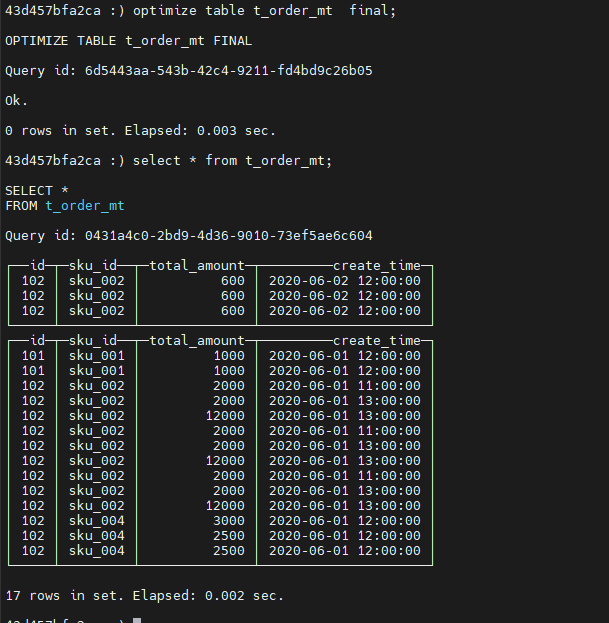
查看数据文件:
primary key主键(可选)
ClickHouse 中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同 primary key 的数据的。
主键的设定主要依据是查询语句中的 where 条件。
根据条件通过对主键进行某种形式的二分查找,能够定位到对应的 index granularity,避免了全表扫描
index granularity: 直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse 中的 MergeTree 默认是 8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据
稀疏索引的好处就是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行进行一点扫描
order by(必选)
order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by 是 MergeTree 中唯一一个必填项,甚至比 primary key 还重要,因为当用户不设置主键的情况,很多处理会依照 order by 的字段进行处理(比如后面会讲的去重和汇总)。
要求:主键必须是 order by 字段的前缀字段。
比如 order by 字段是 (id,sku_id) 那么主键必须是 id 或者(id,sku_id)
二级索引(跳数索引)
目前在 ClickHouse 的官网上二级索引的功能在 v20.1.2.4 之前是被标注为实验性的,在
这个版本之后默认是开启的。
1)老版本使用二级索引前需要增加设置
是否允许使用实验性的二级索引(v20.1.2.4 开始,这个参数已被删除,默认开启)
set allow_experimental_data_skipping_indices=1;
2)创建测试表
create table t_order_mt2(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime,
INDEX a total_amount TYPE minmax GRANULARITY 5
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
TYPE:索引类型,minmax记录最小最大值
其中 GRANULARITY N 是设定二级索引对于一级索引粒度的粒度。(会对一级索引分块做合并)
3)插入数据、
insert into t_order_mt2 values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
4)对比效果
使用下面语句进行测试,可以看出二级索引能够为非主键字段的查询发挥作用
clickhouse-client --password --send_logs_level=trace <<< 'select * from t_order_mt2 where total_amount > toDecimal32(900., 2)'
Password for user (default):
[43d457bfa2ca] 2022.05.06 09:49:04.685967 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Debug> executeQuery: (from 127.0.0.1:36672) select * from t_order_mt2 where total_amount > toDecimal32(900., 2)
[43d457bfa2ca] 2022.05.06 09:49:04.686370 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "total_amount > toDecimal32(900., 2)" moved to PREWHERE
[43d457bfa2ca] 2022.05.06 09:49:04.686553 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Trace> ContextAccess (default): Access granted: SELECT(id, sku_id, total_amount, create_time) ON default.t_order_mt2
[43d457bfa2ca] 2022.05.06 09:49:04.686608 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Trace> InterpreterSelectQuery: FetchColumns -> Complete
[43d457bfa2ca] 2022.05.06 09:49:04.686774 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Debug> default.t_order_mt2 (44a15a48-e7a1-48af-be39-61c672cd8555) (SelectExecutor): Key condition: unknown
[43d457bfa2ca] 2022.05.06 09:49:04.686887 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Debug> default.t_order_mt2 (44a15a48-e7a1-48af-be39-61c672cd8555) (SelectExecutor): MinMax index condition: unknown
[43d457bfa2ca] 2022.05.06 09:49:04.687383 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Debug> default.t_order_mt2 (44a15a48-e7a1-48af-be39-61c672cd8555) (SelectExecutor): Index `a` has dropped 1/2 granules.
[43d457bfa2ca] 2022.05.06 09:49:04.687412 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Debug> default.t_order_mt2 (44a15a48-e7a1-48af-be39-61c672cd8555) (SelectExecutor): Selected 2/2 parts by partition key, 1 parts by primary key, 2/2 marks by primary key, 1 marks to read from 1 ranges
[43d457bfa2ca] 2022.05.06 09:49:04.687464 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Debug> MergeTreeInOrderSelectProcessor: Reading 1 ranges in order from part 20200601_1_1_0, approx. 5 rows starting from 0
101 sku_001 1000 2020-06-01 12:00:00
102 sku_002 2000 2020-06-01 11:00:00
102 sku_002 2000 2020-06-01 13:00:00
102 sku_002 12000 2020-06-01 13:00:00
102 sku_004 2500 2020-06-01 12:00:00
[43d457bfa2ca] 2022.05.06 09:49:04.688172 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Information> executeQuery: Read 5 rows, 160.00 B in 0.002156268 sec., 2318 rows/sec., 72.46 KiB/sec.
[43d457bfa2ca] 2022.05.06 09:49:04.688229 [ 56 ] {0bb9bae0-2cf6-4caf-8fac-00b5eebacdc1} <Debug> MemoryTracker: Peak memory usage (for query): 0.00 B.
添加索引之后,分区目录下会有索引文件
数据TTL(数据存活时间)
TTL 即 Time To Live,MergeTree 提供了可以管理数据表或者列的生命周期的功能。
1)列级别TTL
CREATE TABLE example_table
(
d DateTime,
a Int TTL d + INTERVAL 1 MONTH,
b Int TTL d + INTERVAL 1 MONTH,
c String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d;
ALTER TABLE example_table
MODIFY COLUMN
c String TTL d + INTERVAL 1 DAY;
(1)创建测试表
create table t_order_mt3(
id UInt32,
sku_id String,
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
依赖create_time,依赖的这个字段不能是主键,类型必须是日期
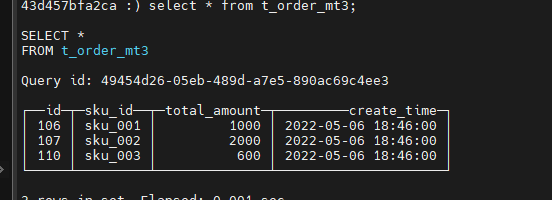
(2)插入数据
insert into t_order_mt3 values
(106,'sku_001',1000.00,'2022-05-06 18:46:00'),
(107,'sku_002',2000.00,'2022-05-06 18:46:00'),
(110,'sku_003',600.00,'2022-05-06 18:46:00');
手动合并:
optimize table t_order_mt3 final;
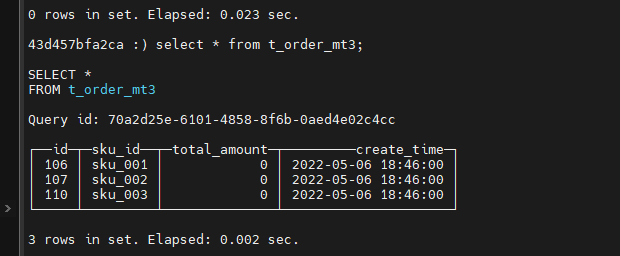
手动合并,查看效果 到期后,指定的字段数据归 0
- 表级TTL
格式:
CREATE TABLE example_table
(
d DateTime,
a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH [DELETE],
d + INTERVAL 1 WEEK TO VOLUME 'aaa',
d + INTERVAL 2 WEEK TO DISK 'bbb’;
ALTER TABLE example_table
MODIFY TTL d + INTERVAL 1 DAY;
涉及判断的字段必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
能够使用的时间周期:
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER
- YEAR
下面的这条语句使数据会在 create_time 之后 10 秒丢失
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
43d457bfa2ca :) alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
ALTER TABLE t_order_mt3
MODIFY TTL create_time + toIntervalSecond(10)
Query id: 50099625-4e36-43e1-af1b-79150a7c5f4e
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 22.1.3 revision 54455.
Ok.
0 rows in set. Elapsed: 0.082 sec.
43d457bfa2ca :) select * from t_order_mt3;
SELECT *
FROM t_order_mt3
Query id: 5ca91a43-1514-47db-8959-90192dcd1051
Ok.
0 rows in set. Elapsed: 0.001 sec.
ReplacingMergeTree(保证最终一致性)
ReplacingMergeTree 是 MergeTree 的一个变种,它存储特性完全继承 MergeTree,只是多了一个去重的功能。 尽管 MergeTree 可以设置主键,但是 primary key 其实没有唯一约束的功能。如果你想处理掉重复的数据,可以借助这个 ReplacingMergeTree
去重时机:数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。
去重范围:
如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重。
所以 ReplacingMergeTree 能力有限, ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
案例:
1)创建表
create table t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
ReplacingMergeTree() 填入的参数为版本字段,重复数据保留版本字段值最大的。
如果不填版本字段,默认按照插入顺序保留最后一条
2)向表中插入数据
insert into t_order_rmt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
3)执行查询(已合并)
43d457bfa2ca :) select * from t_order_rmt;
SELECT *
FROM t_order_rmt
Query id: 08b26cf7-b5ae-4c02-ac67-cb47926ce492
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
4 rows in set. Elapsed: 0.038 sec.
4)通过测试得到结论
实际上是使用 order by 字段作为唯一键
去重不能跨分区
只有同一批插入(新版本)或合并分区时才会进行去重
认定重复的数据保留,版本字段值最大的
如果版本字段相同则按插入顺序保留最后一笔
SummingMergeTree
对于不查询明细,只关心以维度进行汇总聚合结果的场景。如果只使用普通的MergeTree的话,无论是存储空间的开销,还是查询时临时聚合的开销都比较大。
ClickHouse 为了这种场景,提供了一种能够“预聚合”的引擎 SummingMergeTree
案例
1)建表:
create table t_order_smt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =SummingMergeTree(total_amount)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id );
2)插入数据
insert into t_order_smt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
3) 查询数据
43d457bfa2ca :) select * from t_order_smt;
SELECT *
FROM t_order_smt
Query id: 21cf0648-fff1-48b8-9064-d8f2278b40af
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 16000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
4 rows in set. Elapsed: 0.007 sec.
4)结论
以 SummingMergeTree()中指定的列作为汇总数据列
可以填写多列必须数字列,如果不填,以所有非维度列且为数字列的字段为汇总数
据列
以 order by 的列为准,作为维度列
其他的列按插入顺序保留第一行
不在一个分区的数据不会被聚合
只有在同一批次插入(新版本)或分片合并时才会进行聚合
5)问题
能不能直接执行以下 SQL 得到汇总值
select total_amount from XXX where province_name=’’ and create_date=’xxx’
不行,可能会包含一些还没来得及聚合的临时明细
如果要是获取汇总值,还是需要使用 sum 进行聚合,这样效率会有一定的提高,但本
身 ClickHouse 是列式存储的,效率提升有限,不会特别明显。
select sum(total_amount) from province_name='' and create_date='xxx