单机环境搭建
安装
mkdir /opt/bigdata tar xf hadoop-2.6.5.tar.gz mv hadoop-2.6.5 /opt/bigdata/ pwd /opt/bigdata/hadoop-2.6.5 vi /etc/profile export JAVA_HOME=/usr/java/default export HADOOP_HOME=/opt/bigdata/hadoop-2.6.5 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile
配置hadoop的角色:
cd $HADOOP_HOME/etc/hadoop 必须给hadoop配置javahome要不ssh过去找不到 vi hadoop-env.sh export JAVA_HOME=/usr/java/default 给出NN角色在哪里启动 vi core-site.xml <property> <name>fs.defaultFS</name> <value>hdfs://node01:9000</value> </property> 配置hdfs 副本数为1.。。。 vi hdfs-site.xml <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/local/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/var/bigdata/hadoop/local/dfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node01:50090</value> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>/var/bigdata/hadoop/local/dfs/secondary</value> </property> 配置DN这个角色再那里启动 vi slaves node01
初始化&启动:
hdfs namenode -format 创建目录 并初始化一个空的fsimage VERSION CID start-dfs.sh 第一次:datanode和secondary角色会初始化创建自己的数据目录 http://node01:50070 修改windows: C:WindowsSystem32driversetchosts 192.168.150.11 node01 192.168.150.12 node02 192.168.150.13 node03 192.168.150.14 node04
格式化成功:

格式化后:只创建的name目录
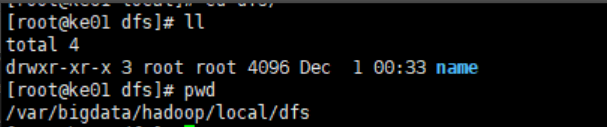
启动dfs后:

简单使用:
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root
验证知识点:
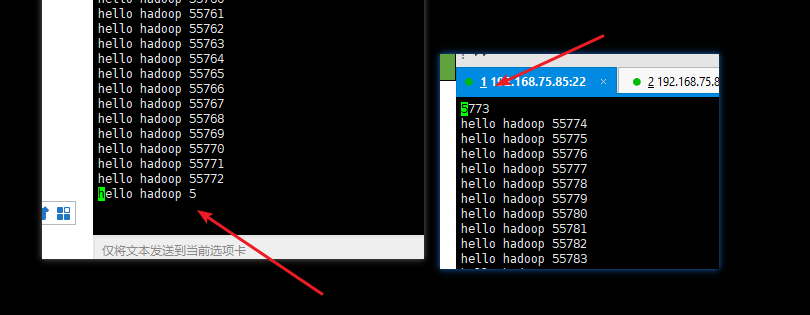
cd /var/bigdata/hadoop/local/dfs/name/current 观察 editlog的id是不是再fsimage的后边 cd /var/bigdata/hadoop/local/dfs/secondary/current SNN 只需要从NN拷贝最后时点的FSimage和增量的Editlog hdfs dfs -put hadoop*.tar.gz /user/root cd /var/bigdata/hadoop/local/dfs/data/current/BP-281147636-192.168.150.11-1560691854170/current/finalized/subdir0/subdir0 for i in `seq 100000`;do echo "hello hadoop $i" >> data.txt ;done hdfs dfs -D dfs.blocksize=1048576 -put data.txt cd /var/bigdata/hadoop/local/dfs/data/current/BP-281147636-192.168.150.11-1560691854170/current/finalized/subdir0/subdir0 检查data.txt被切割的块,他们数据什么样子
文件被切割后的样子:
注意点:
- 一定要同步时间
- 一定要关闭防火墙,
- 如果先启动hdfs,在关闭防火墙或者同步时间,就会启动不起来dataNode,解决方式: 1.关闭hdfs、 2.删除目录 /var/bigdata/hadoop/local/dfs下所有的文件、 3.重新格式化文件、 4.重新启动
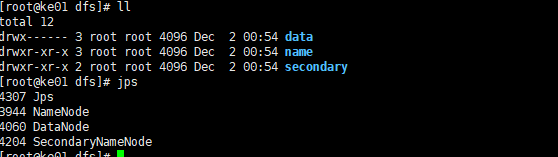
启动成功后editslog和fsimage



jps进程信息:成功启动dataNode、nameNode、secondary