模板题:
简要题意:
给定一个网络图,求其网络最大流(下简称 最大流)。
网络图的定义:每条边 ((u,v,w)) 表示 (u ightarrow v) 的 流量 为 (w),流量可以理解为,单位时间内能流过的最大的量。
最大流的定义:从源点开始到汇点,在让 单位时间内每条边流过的量不超过其流量 的情况下最大的运输量。(汇点即终点,源点即起点)
在实际生活中,网络流(就研究最大流)问题可以理解为 供水系统 。以样例为例:
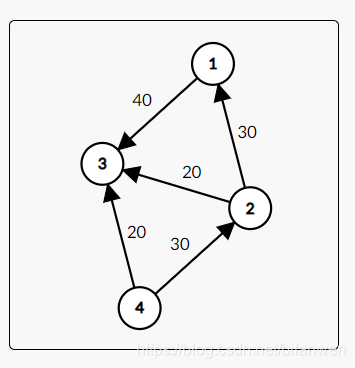
供水公司 的编号为 (4),你家的编号为 (3),而 中转供水处 只负责转运。网络图如图所示。
由一只聪明的猴子掌控着一些操作:即某某供水处往某某供水处运了多少水,而 水管的大小不同,流量也不同;如果流过的水超过水管的流量会直接渗出 ,所以产生了上面这个图。当然供水公司本着 赚更多钱 运更多的水(但不浪费水)的角度,希望供到你家尽量多的水。
这只猴子把 (4) 号节点放 (50L) 水出去,其中 (20L) 通过 (4 ightarrow 3) 这条边直接供向了你家。而 (30L) ,先是通过 (4 ightarrow 2) 这条边,到达了 (2) 号中转供水处。
然后 (30L) 又分作两份,(20L) 从 (2 ightarrow 3) 流过,剩余 (10L) 顺着 (2 ightarrow 1 ightarrow 3) 也到达了你家。
这是,你家就有了 (50L) 的水。
如果从 (4) 号节点流出了超过 (50L) 水,那么 (4 ightarrow 3) 和 (4 ightarrow 2) 这两条边无法承受流量。所以 水在水管里渗掉了,最终还是降为 (50L),浪费了水。
综上,该网络图的最大流 为 (50).
那么,如何解决网络流问题呢?
首先抛出一些定义便于说理,括号中是便于理解的说法。
-
设原网络图的点集为 (V).(由中转处,供水公司和你家构成)
-
割:将原图中所有顶点分成两个集合 (S) 和 (T = V - S) ,其中源点 (s) 在集合 (S) 中,汇点 (t) 在集合 (T) 中。如果把起点在(S) 中,终点在 (T) 中的边全部删除,就无法从 (s) 到达 (t) 了。这样的集合划分 ((S,T)) 称为一个割。(即将 (V) 分成两部分,使得如果把所有横跨两部分的水管删去,一滴水也到不了你家,比方说上图中,(S=(4)) 和 (T=(1,2,3)) 就是一个割,因为 (4 ightarrow 3) 和 (4 ightarrow 2) 的水管被删掉之后,供水就断了。可以理解成是 有向图中的割边(不严谨))
-
割的容量:即所有 (u ightarrow v (u in S , v in T)) 的流量之和。(即横跨两集合边的流量之和)
-
最小割:所有割中容量最小的那个。比方说上图中,(S=(4),T=(1,2,3)) 就是最小割。
-
最小割最大流定理:最大流等于最小割。具体证明因过于复杂略。(其实可以理解成,有一个 恐怖分子 想让你家喝不到水,他希望割断最短的水管而达到这个目的;那么如果 割掉这些水管可以导致供水系统崩溃并且它是最小的话,很显然,能供向你家的水就是这些水管的流量和了。如果比这个和小,肯定有更小的割;如果比这个和大,那么说明 还有其它水可以不通过这些水管流过,这就不是割了,也矛盾。大概是这样的,感性理解吧,不太严谨)
-
残余网络:即所有 实际流量与流量的差 构成的网络图。(就是如果这个水管能流过 (x),但种种原因使得它只流过 (y (y leq x)),那么用 (x-y) 构成网络图)
一种可能求最大流的方法是:采用 和 ( ext{Dijkstra}) 类似的流法,在残余网络中搜索松弛。没错!
引入
基于最短路中的松弛概念,我们考虑和最短路一样的做法。但是看这个图:
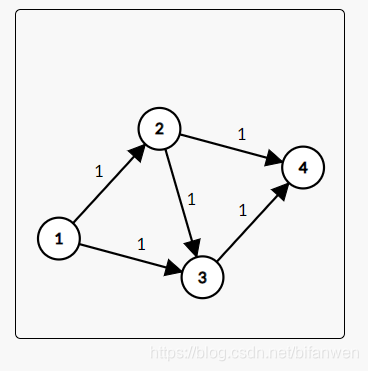
聪明的猴子选了 (1 ightarrow 2 ightarrow 3 ightarrow 4) 这条边之后,流量是 (1).
但是 你并不能把这条路上流量清 (0),因为明明存在 (1 ightarrow 2 ightarrow 4) ,(1 ightarrow 3 ightarrow 4) 这两条可以流量为 (2) 的路径。
猴子发现自己错了,然后尝试了所有路径……它对自己的杰作感到满意。
可是你会满意么?尝试所有路径是指数级的 爆炸性复杂度,实在无意义(不过 (30 \%) 的数据可以拿下,但对正解无益)。
也就是说,我们要想到一种 可以让程序反悔 的操作。
下面就引入了 ( ext{Ford-Fulkerson}) 算法,简称 ( ext{FF}) 算法。
算法一 ( ext{Ford-Fulkerson})
( ext{FF}) 的操作是:
-
当前不断寻找增广路(即不断搜索能继续流的路)
-
到汇点即有了一条路径,统计答案。然后将这条路径上所有边的流量减掉最终流量,建立反向边的边权为最终流量,构成残余网络。(你似乎明白残余网络是干什么的了)
-
不断寻找直到找不到为止。
还是上面那个图:
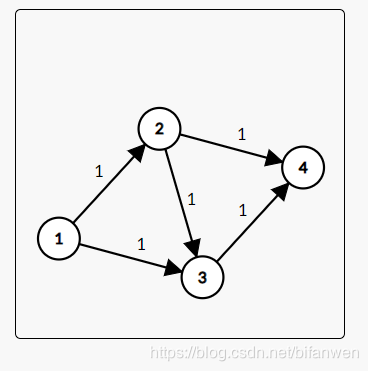
假设聪明的猴子还是找到 (1 ightarrow 2 ightarrow 3 ightarrow 4) 这条边。流量为 (1),它就会将 路径上所有水管的流量减少 (1),将其反相边流量增加 (1).这样的操作我们称为 “反悔” 操作。 一次之后变成了:
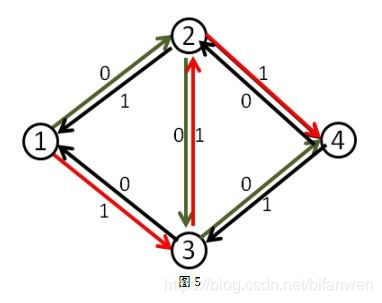
然后猴子又找到了 (1
ightarrow 3
ightarrow 2
ightarrow 4) 这条路径,两个答案 (1) 的和为 (2).
然后再 反悔一次 从 (1) 流不出水,所以结束,答案为 (2).
感性说明(不严谨):
最终流量为 (x),那么 (u ightarrow v) 减少 (x) 可以理解为:(u) 现在不想走这条边,想要实施别的增广,那么 给 (v) 维持输出 的同时收回自己的流量,反悔了一次;接着 走过这条反向路 的路径,显然 和之前的路径都走过这条 (u ightarrow v),所以说不影响答案。
因此,( ext{FF}) 算法的精髓在于反悔操作,对于当前图不断进行增广,反悔,最终得到答案。
程序实现过程不同,但效率是一样的。
比方说,( ext{FF}) 算法是 在流的过程中,判断能否流,然后边流边反悔 的,用 ( ext{bfs}) 实现,时间复杂度为 (O(n imes m^2)).
而另一个 ( ext{Edmonds–Karp}) 算法(下简称 ( ext{EK}) 算法)是通过不断 ( ext{bfs}) 实现的,时间复杂度也为 (O(n imes m^2)).
注:由于各种各样的常数问题,LOJ #101. 最大流 上面跑 ( ext{EK}) 能过,( ext{FF}) 过不了;而本题是 ( ext{FF}) 能过,( ext{EK}) 过不了。(那题要用 ( ext{long long}))
所以实践告诉我们,还是 dinic 比较稳定 算法的时间复杂度也有一部分取决于常数。所以本题两篇代码都给出。
( ext{EK}) 算法:(( ext{LOJ}) 满分,洛谷 (70))
#pragma GCC optimize(2)
#include<cstdio>
#include<queue>
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
typedef long long ll;
const ll INF=1e18;
const ll N=1e2+1;
inline ll read(){char ch=getchar();ll f=1;while(ch<'0' || ch>'9') {if(ch=='-') f=-f; ch=getchar();}
ll x=0;while(ch>='0' && ch<='9') x=(x<<3)+(x<<1)+ch-'0',ch=getchar();return x*f;}
queue<ll> q; ll flow[N],ans; // flow[i] 是当前最大流量
ll n,m,s,t,g[N][N],pre[N]; // pre[i] 记录前驱 , 利于反悔
inline ll bfs(ll s,ll t) { //增广一次
while(!q.empty()) q.pop();
memset(pre,-1,sizeof(pre));
pre[s]=0; q.push(s); flow[s]=INF;
while(!q.empty()) {
ll u=q.front(); q.pop();
if(u==t) break;
for(ll i=1;i<=n;i++)
if(g[u][i]>0 && pre[i]==-1ll) {
pre[i]=u; flow[i]=min(flow[u],g[u][i]);
q.push(i); //可以增广则更新一次 , 类似于 dijkstra
}
} return (pre[t]==-1ll)?-1ll:flow[t];
}
inline void EK(ll s,ll t) {
ll x=0;
while((x=bfs(s,t))!=-1ll) { //只要增广路存在则继续
ll k=t; while(k!=s) {
ll l=pre[k];
g[l][k]-=x; g[k][l]+=x;
k=l; //反悔 , 一次次迭代路径
} ans+=x; //记录答案
}
}
int main(){
n=read(),m=read(),s=read(),t=read();
while(m--) {
ll u=read(),v=read(),w=read();
g[u][v]+=w;
} EK(s,t); printf("%lld
",ans);
return 0;
}
( ext{FF}) 算法:(( ext{LOJ} space 75pts) (不过因为出题人把所有测试点放在一个 ( ext{Subtask}) 所以是 (0) 分,但 实际上是 (75pts)),洛谷 (100pts)).
#pragma GCC optimize(2)
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+1;
inline int read(){char ch=getchar();int f=1;while(ch<'0' || ch>'9') {if(ch=='-') f=-f; ch=getchar();}
int x=0;while(ch>='0' && ch<='9') x=(x<<3)+(x<<1)+ch-'0',ch=getchar();return x*f;}
int n,m,s,t; bool vis[N];
vector<pair<int,int> > G[N];
inline int found(int x,int y) {
for(int i=0;i<G[x].size();i++)
if(G[x][i].first==y) return i;
} //表示找到 x->y 的路返回其位置
inline int dfs(int u,int flow) { //返回当前最大流 , 为 0 说明无法流
if(u==t) return flow;
vis[u]=1; for(int i=0;i<G[u].size();i++) {
int v=G[u][i].first,w=G[u][i].second;
if(!w || vis[v]) continue;
int x=dfs(v,min(flow,w)); //下一步
if(x>0) { //可以流
G[u][i].second-=x;
int y=found(v,u);
G[v][y].second+=x; //反悔一次
return x;
}
} return 0; //所有尝试没有答案则无解
}
int main(){
n=read(),m=read(),s=read(),t=read();
while(m--) {
int u=read(),v=read(),w=read();
G[u].push_back(make_pair(v,w));
G[v].push_back(make_pair(u,0)); //细节 , 便于之后操作
} int t,ans=0;
while((memset(vis,0,sizeof(vis))) && (t=dfs(s,INT_MAX))>0) ans+=t; //可以增广则增广一次
printf("%d
",ans);
return 0;
}
算法二 ( ext{dinic})
上面的 ( ext{FF}) 和 ( ext{EK}) 算法,虽然实现不同但本质完全一样,因为常数问题,我们难以确定它们的最终效率究竟如何,因此我们需要更优的算法。
注意到在 ( ext{FF})(下文中用 ( ext{FF}) 代称两种算法)每次反悔的时间不是很妙,大量操作也不是很优。
注意到一种优化,如果我们把 ( ext{FF}) 中,(u ightarrow v) 这条边当 (v) 遍历完毕时,那么我们直接从 (u) 重新尝试其它的 (u ightarrow v) .
那么,这样快了许多是不错的,但是 出现绕长路,走回路 的棘手问题。
所以,我们根据 搜索树 的思路,提出了 分层图 的概念。
分层图 其实就是按照和源点的距离进行分层。用人话说,就是源点自己是 (1) 层,源点 (i) 步能 流到(流量为 (0) 就算了)
的是 (i+1) 层。
这样的分层,我们每次 只需要从 (i) 层往 (i+1) 层探索即可。
那么你会问了:如何判断当前有解呢?
如果最终汇点有层数的话,说明能流到汇点,就有解;如果流不到汇点,就是没有层数,那肯定是无解。分层既可以优化搜索效率,又可以做无解判断。好!
理论上时间复杂度:(O(n imes m)).(由于根本跑不满这个时间,所以仍然能通过,两个 ( ext{OJ}) 都测过了)
实际得分:(100pts).
// 这是洛谷上交的 , 去 LOJ 的话要开 long long
#pragma GCC optimize(2)
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+1;
inline int read(){char ch=getchar();int f=1;while(ch<'0' || ch>'9') {if(ch=='-') f=-f; ch=getchar();}
int x=0;while(ch>='0' && ch<='9') x=(x<<3)+(x<<1)+ch-'0',ch=getchar();return x*f;}
int n,m,s,t,ans=0,dep[N],q[N];
vector<pair<int,int> > G[N];
inline bool bfs() { //探索
memset(dep,0,sizeof(dep)); int l,r; //用左右指针实现队列
q[l=r=1]=s; dep[s]=1; while(l<=r) {
int u=q[l++]; for(int i=0;i<G[u].size();i++) {
int v=G[u][i].first,w=G[u][i].second;
if(!w || dep[v]) continue; //流过或者流量为 0
dep[v]=dep[u]+1,q[++r]=v; //探索
}
} return dep[t];
}
inline int found(int x,int y) {
for(int i=0;i<G[x].size();i++)
if(G[x][i].first==y) return i;
}
inline int dfs(int u,int dis) {
if(u==t) return dis;
int out=0; for(int i=0;i<G[u].size();i++) {
int v=G[u][i].first,w=G[u][i].second;
if(!w || dep[v]!=dep[u]+1) continue;
int x=dfs(v,min(dis,w));
G[u][i].second-=x; int y=found(v,u);
G[v][y].second+=x; dis-=x; out+=x;
} return dep[u]=(out==0)?0:dep[u],out;
} //基本和 FF / EK 一样
int main(){
n=read(),m=read(),s=read(),t=read();
while(m--) {
int u=read(),v=read(),w=read();
G[u].push_back(make_pair(v,w));
G[v].push_back(make_pair(u,0));
} while(bfs()) ans+=dfs(s,2e9); //这里如果交 LOJ 要把 2e9 适当开大 , 实测 2e12 可以通过
printf("%d
",ans); //交 LOJ 要把 %d 改成 %lld
return 0;
}