kafka的前言知识: 1:Kafka是什么? 在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。kafka是一个生产-消费模型。
Producer:生产者,只负责数据生产,生产者的代码可以集成到任务系统中。
数据的分发策略由producer决定,默认是defaultPartition Utils.abs(key.hashCode) % numPartitions
Broker:当前服务器上的Kafka进程,俗称拉皮条。只管数据存储,不管是谁生产,不管是谁消费。
在集群中每个broker都有一个唯一brokerid,不得重复。
Topic:目标发送的目的地,这是一个逻辑上的概念,落到磁盘上是一个partition的目录。partition的目录中有多个segment组合(index,log)
一个Topic对应多个partition[0,1,2,3],一个partition对应多个segment组合。一个segment有默认的大小是1G。
每个partition可以设置多个副本(replication-factor 1),会从所有的副本中选取一个leader出来。所有读写操作都是通过leader来进行的。
特别强调,和mysql中主从有区别,mysql做主从是为了读写分离,在kafka中读写操作都是leader。
ConsumerGroup:数据消费者组,ConsumerGroup可以有多个,每个ConsumerGroup消费的数据都是一样的。
可以把多个consumer线程划分为一个组,组里面所有成员共同消费一个topic的数据,组员之间不能重复消费。 2:Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。 3:Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。 4:Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
5:无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
6:Kafka核心组件:Topic :消息根据Topic进行归类;Producer:发送消息者;Consumer:消息接受者;broker:每个kafka实例(server);Zookeeper:依赖集群保存meta信息。
7:消息系统的核心作用就是三点:解耦,异步和并。
8:kafka生产数据时的分组策略?
默认是defaultPartition Utils.abs(key.hashCode) % numPartitions。
上文中的key是producer在发送数据时传入的,produer.send(KeyedMessage(topic,myPartitionKey,messageContent))。
9:kafka如何保证数据的完全生产?
ack机制:broker表示发来的数据已确认接收无误,表示数据已经保存到磁盘。
0:不等待broker返回确认消息。
1:等待topic中某个partition leader保存成功的状态反馈。
-1:等待topic中某个partition 所有副本都保存成功的状态反馈。
10:broker如何保存数据?
在理论环境下,broker按照顺序读写的机制,可以每秒保存600M的数据。主要通过pagecache机制,尽可能的利用当前物理机器上的空闲内存来做缓存。
当前topic所属的broker,必定有一个该topic的partition,partition是一个磁盘目录。partition的目录中有多个segment组合(index,log)。
11:如何保证kafka消费者消费数据是全局有序的?
伪命题,
如果要全局有序的,必须保证生产有序,存储有序,消费有序。由于生产可以做集群,存储可以分片,消费可以设置为一个consumerGroup,要保证全局有序,就需要保证每个环节都有序。只有一个可能,就是一个生产者,一个partition,一个消费者。这种场景和大数据应用场景相悖。
1:KafKa的官方网址:http://kafka.apache.org/
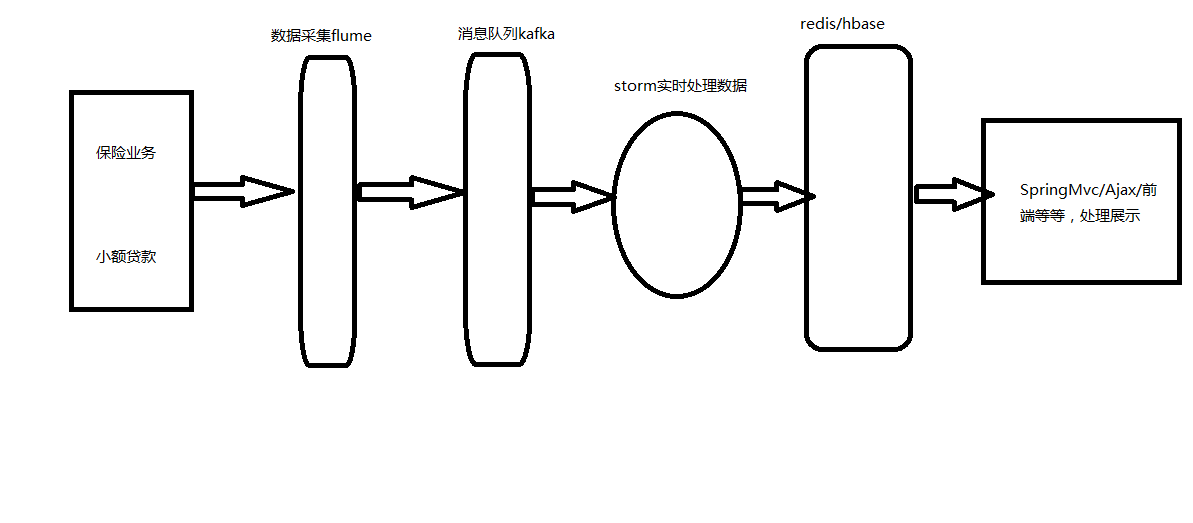
开发流程图,如:
2:KafKa的基础知识:
2.1:kafka是一个分布式的消息缓存系统。
2.2:kafka集群中的服务器都叫做broker。
2.3:kafka有两类客户端,一类叫producer(消息生产者),一类叫做consumer(消息消费者),客户端和broker服务器之间采用tcp协议连接。
2.4:kafka中不同业务系统的消息可以通过topic进行区分,而且每一个消息topic都会被分区,以分担消息读写的负载。
2.5:每一个分区都可以有多个副本,以防止数据的丢失。
2.6:某一个分区中的数据如果需要更新,都必须通过该分区所有副本中的leader来更新。
2.7:消费者可以分组,比如有两个消费者组A和B,共同消费一个topic:order_info,A和B所消费的消息不会重复。
比如 order_info 中有100个消息,每个消息有一个id,编号从0-99,那么,如果A组消费0-49号,B组就消费50-99号。
2.8:消费者在具体消费某个topic中的消息时,可以指定起始偏移量。
3:KafKa集群的安装搭建,注意区分单节点KafKa集群的搭建。
Topic :消息根据Topic进行归类;Producer:发送消息者;Consumer:消息接受者;broker:每个kafka实例(server);Zookeeper:依赖集群保存meta信息。
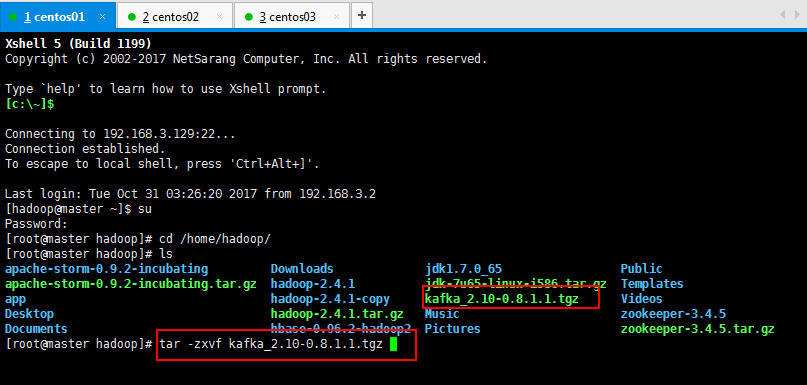
3.1:kafka集群安装,第一步上传kafka_2.10-0.8.1.1.tgz到虚拟机上面,过程省略,然后进行解压缩操作:
3.2:修改kafka配置文件,修改server.properties
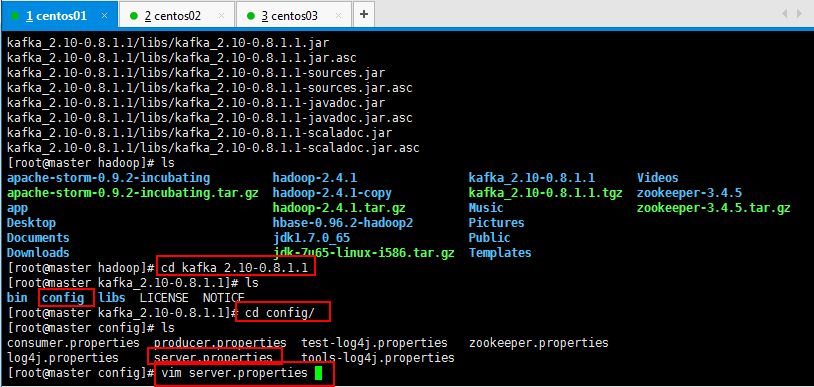
修改如下所示,具体情况可以根据手册修改,详细修改可以参考Kafka的文档:
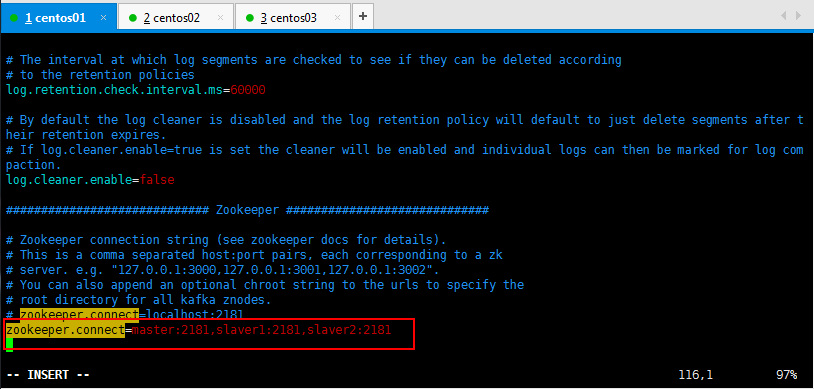
1 #broker的全局唯一的编号,不可以重复 2 broker.id=0 3 4 #用来监听链接的端口,producer或者consumer将在此端口建立连接 5 port=9092 6 7 #处理网络请求的线程数量 8 num.network.threads=3 9 10 #用来处理磁盘Io的线程数量 11 num.io.threads=8 12 13 #发送套接字的缓冲区大小 14 socket.send.buffer.bytes=102400 15 16 #接受套接字的缓冲区的大小 17 socket.receive.buffer.bytes=102400 18 19 #请求套接字的缓冲区大小 20 socket.request.max.bytes=104857600 21 22 #kafka运行日志存放的路径 23 log.dirs=/tmp/kafka-logs 24 25 #topic在当前broker上的分片个数 26 num.partitions=2 27 28 #用来恢复和清理data下数据的线程数量 29 num.recovery.threads.per.data.dir=1 30 31 #segment文件保留的最长时间,超时将被删除 32 log.retention.hours=168 33 34 #滚动生成新的segment文件的最大时间 35 log.roll.hours=168 36 37 #topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖 38 log.segment.bytes=536870912 39 40 #文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略 41 log.retention.check.interval.ms=60000 42 43 #是否开启日志清理 44 log.cleaner.enable=false 45 46 #zookeeper集群的地址,可以是多个,多个之间用逗号分割 hostname1:port1,hostname2:port2,hostname3:port3 47 zookeeper.connect=localhost:2181 48 49 #ZooKeeper的连接超时时间 50 zookeeper.connection.timeout.ms=1000000
具体操作修改如下所示:
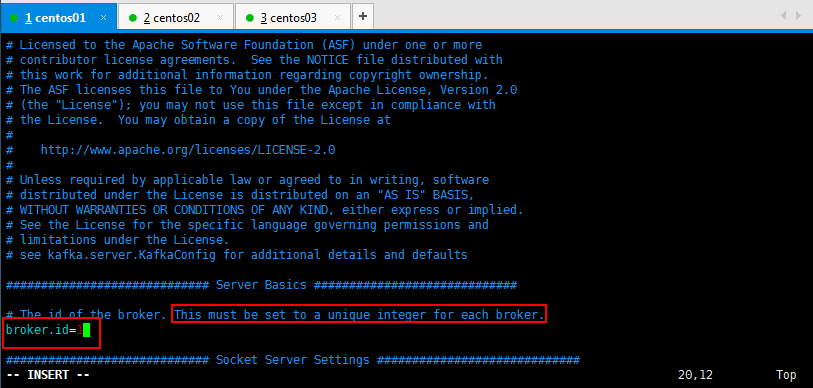
使用自己部署的Zookeeper集群,修改如下所示:
可以直接搜索:/zookeeper.connect找到所要修改的内容:
将配置好的Kafka复制到另外两个节点上面:
[root@master hadoop]# scp -r kafka_2.10-0.8.1.1/ slaver1:/home/hadoop/
[root@master hadoop]# scp -r kafka_2.10-0.8.1.1/ slaver2:/home/hadoop/
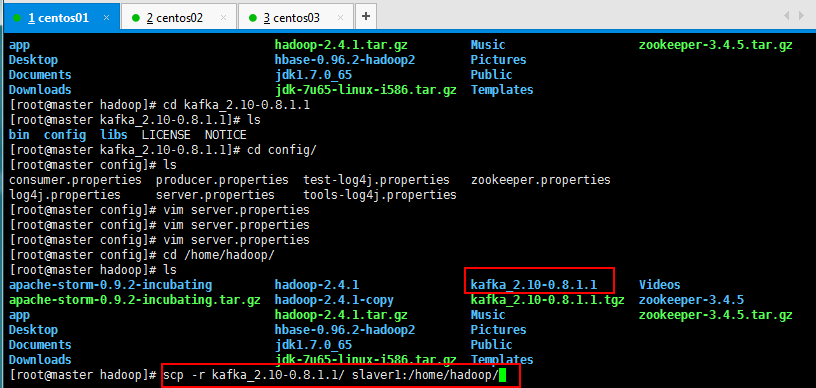
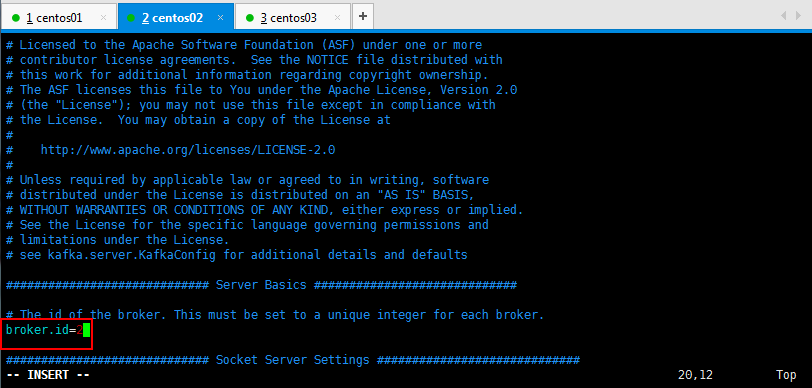
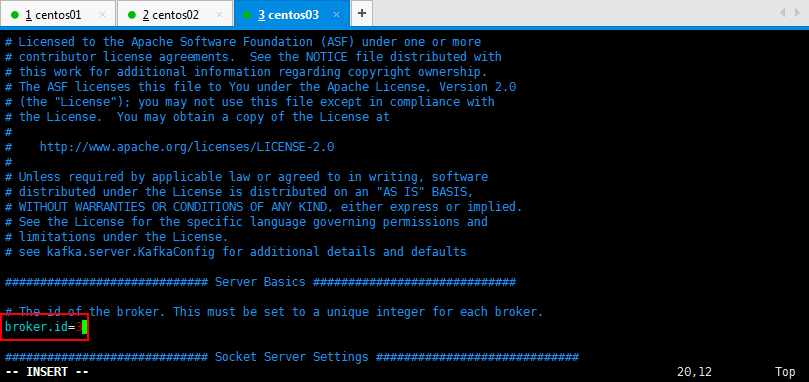
然后修改一下另外两台的broker.id=2和broker.id=3:
这里插一个slf4j的配置,将 [hadoop@slaver1 slf4j-1.7.6]$ unzip slf4j-1.7.6.zip进行解压缩操作。
然后将[hadoop@slaver1 slf4j-1.7.6]$ cp slf4j-nop-1.7.6.jar /home/hadoop/soft/kafka_2.9.2-0.8.1/libs/目录下面。
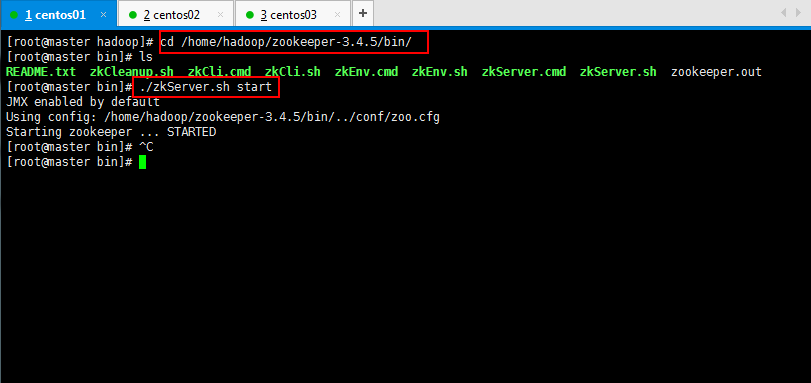
3.3:将zookeeper集群启动:
[root@master hadoop]# cd /home/hadoop/zookeeper-3.4.5/bin/
[root@master bin]# ./zkServer.sh start
[root@slaver2 bin]# ./zkServer.sh status
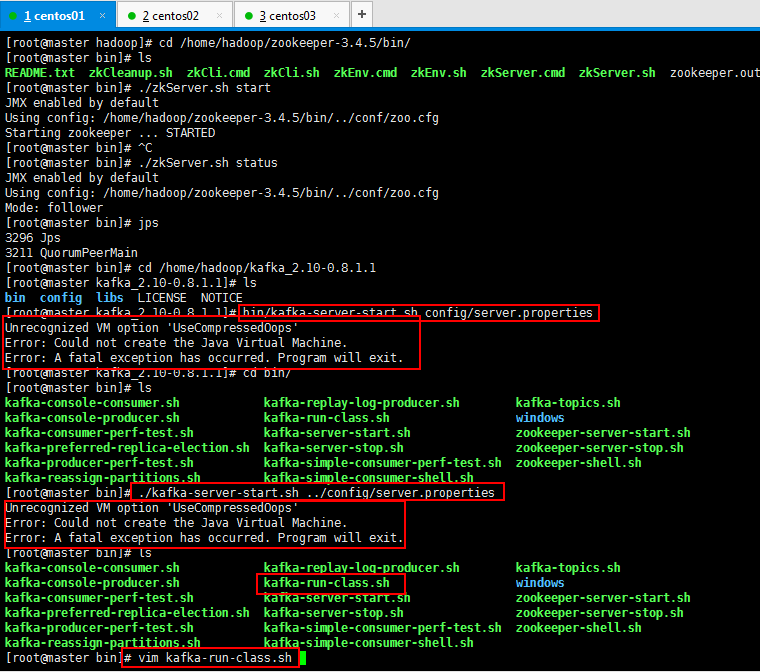
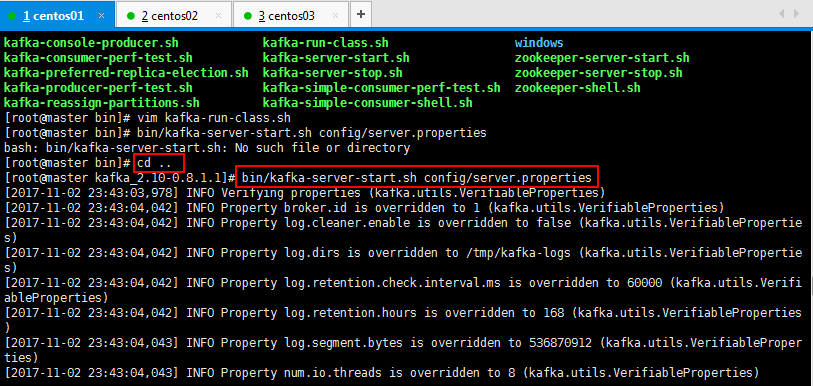
3.4:在每一台节点上启动broker:
bin/kafka-server-start.sh config/server.properties
Unrecognized VM option 'UseCompressedOops' Error: Could not create the Java Virtual Machine. Error: A fatal exception has occurred. Program will exit.
启动的时候报错了,问题的根本是UseCompressedOops是jdk8的,而我的jdk是7,所以解决一下问题:
原因是jdk的版本不匹配,需要修改一下配置文件
修改文件:
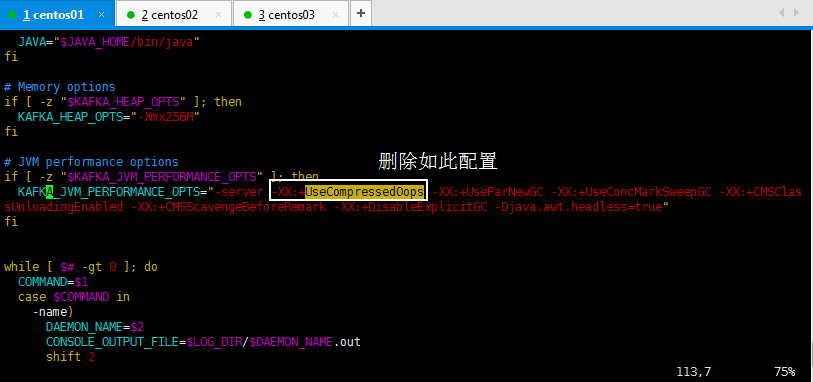
去掉这个配置
-XX:+UseCompressedOops
进去以后,搜索一下比较快:/UseCompressedOops,然后看到如下,删除如此配置:
[root@master bin]# vim kafka-run-class.sh
其他两个节点的都按照如此删除掉即可:
修改好以后开始跑:
在每一台节点上启动broker:
bin/kafka-server-start.sh config/server.properties
1、首先安装nohup: [hadoop@slaver1 ~]$ yum install coreutils 2、后台启动kafka服务:
[hadoop@slaver1 kafka_2.9.2-0.8.1]$ nohup bin/kafka-server-start.sh config/server.properties &
然后按照如此将其他两个节点都启动起来,然后复制xshell的连接看一下jps进程启动情况:
三个都启动起来,可以看一下,broker 1,broker 2,broker 3都启动起来了:

可以使用复制的xshell窗口查看jps进程启动情况:

3.5:在kafka集群中创建一个topic:
常用命令如下所示:
1:Kafka常用操作命令 1.1:查看当前服务器中的所有topic。--zookeeper master:2181指定zookeeper。 bin/kafka-topics.sh --list --zookeeper master:2181 1.2:创建topic。--partitions 3,指定三个分区。--replication-factor 1指定备份的副本数量。--topic topicTest,指定topic的名称。 ./kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 3 --topic topicTest 1.3:删除topic bin/kafka-topics.sh --delete --zookeeper master:2181 --topic topicTest 注意:需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。 1.4:通过shell命令发送消息。生产者。--broker-list master:9092 bin/kafka-console-producer.sh --broker-list master:9092 --topic topicTest 1.5:通过shell消费消息。消费者。--from-beginning从最开始消费。 bin/kafka-console-consumer.sh --zookeeper master:2181 --from-beginning --topic topicTest 1.6:查看消费位置 bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper master:2181 --group testGroup 1.7:查看某个Topic的详情 bin/kafka-topics.sh --topic topicTest --describe --zookeeper master:2181
[root@master kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 3 --partitions 1 --topic order
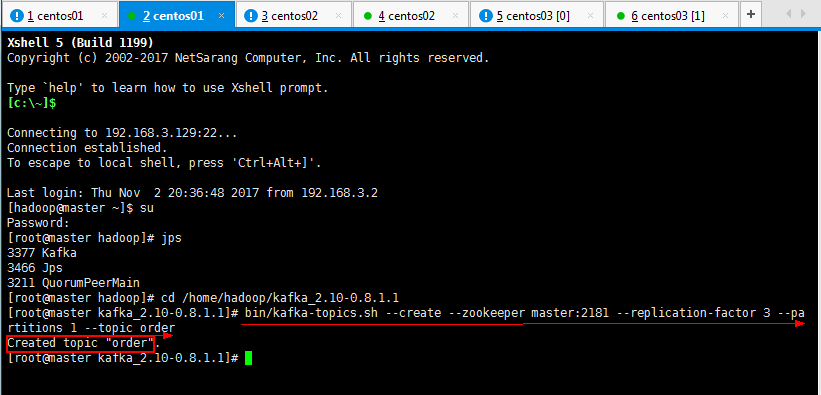
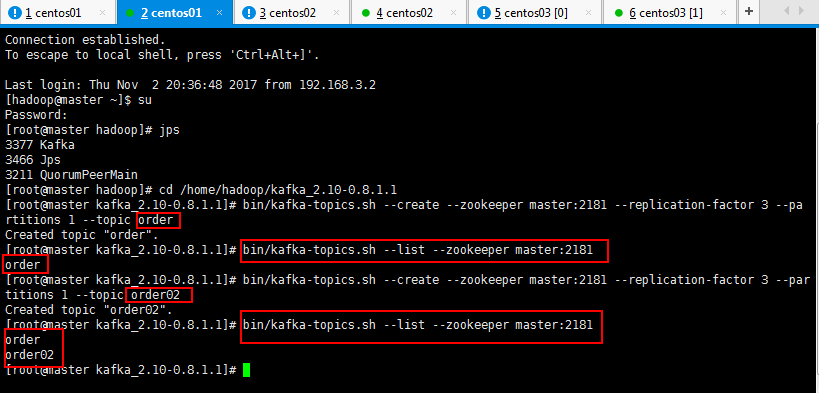
可以查看一下自己创建的topic:
[root@master kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --list --zookeeper master:2181
可以创建多个多个topic,也可以查看一下自己创建的topic:
3.6:用一个producer向某一个topic中写入消息,生产者产生消息,消费者消费消息,如下生产者可以生产:
如下先启动一下生产者,先不生产消息,然后一个消费者,看看是否有输出,然后再生产消息,再去消费者看看消费消息:
#生产者 [root@master kafka_2.10-0.8.1.1]# bin/kafka-console-producer.sh --broker-list master:9092 --topic order #消费者 [root@master kafka_2.10-0.8.1.1]# bin/kafka-console-consumer.sh --zookeeper master:2181 --from-beginning --topic order
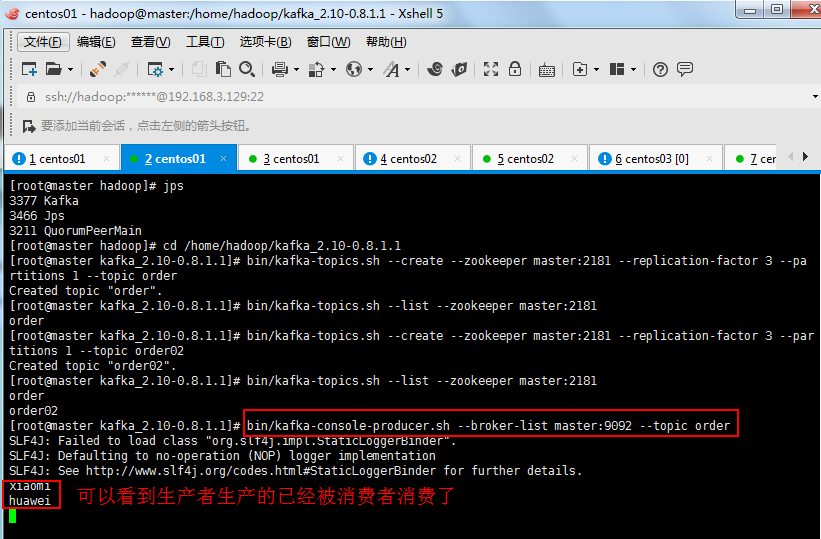
上面是生产者:
下面是消费者:
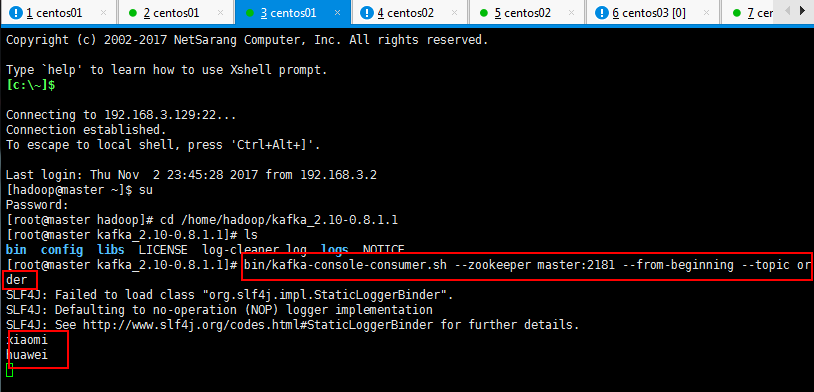
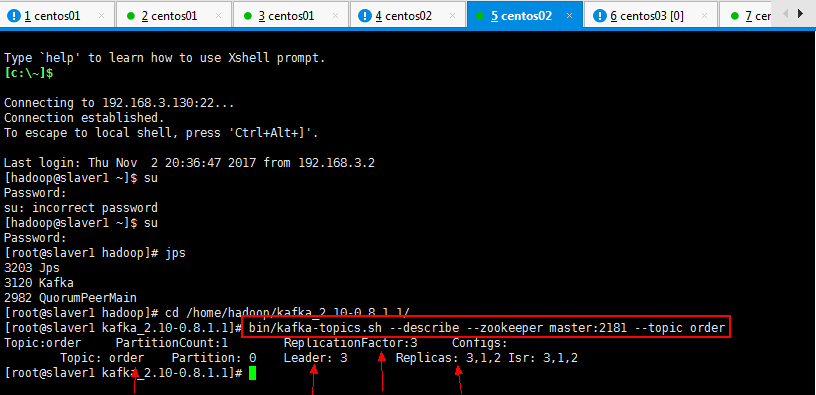
3.7:查看一个topic的分区及副本状态信息:
自己可以找任意一个xshell复制连接进程查看:
[root@slaver1 kafka_2.10-0.8.1.1]# bin/kafka-topics.sh --describe --zookeeper master:2181 --topic order
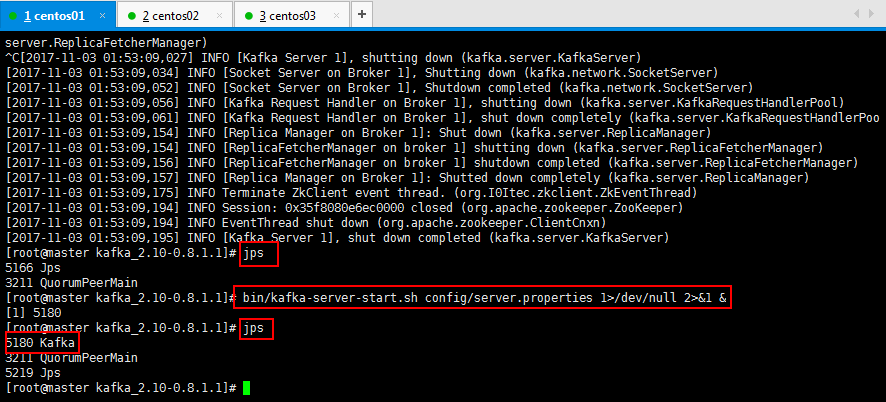
4:kafka运行在后台如何操作,如下所示:
1>/dev/null:代表标准输入到这个目录;
2>&1:代表标准输出也到这个目录下面;
&:代表这个是后台运行;
[root@master kafka_2.10-0.8.1.1]# bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &