1:Hdfs分布式文件系统存的文件,文件存储。 2:Hbase是存储的数据,海量数据存储,作用是缓存的数据,将缓存的数据满后写入到Hdfs中。 3:hbase集群中的角色: (1)、一个或者多个主节点,Hmaster; (2)、多个从节点,HregionServer;
4、hbase集群的配置是一主多从或者多主多从(一定注意区分和hive之间的关系,切记),一主多从可以动态添加主节点,配置成多主多从。
5、如何配置HMaster主备:
a、添加主节点:
在任意的安装了hbase的机器上启动hmaster。命令如下所示:
[hadoop@slaver1 ~]$ local-master-backup.sh start 2
b、添加HBase的从节点regionserver节点:复制原子节点到新节点上,hbase-daemon.sh start regionserver 即添加regionserver节点。
1)、使用[hadoop@slaver1 ~]$ zkCli.sh 可以查看管理的节点。
2)、[zk: localhost:2181(CONNECTED) 0] ls /
3)、[zk: localhost:2181(CONNECTED) 1] ls /hbase 可以查看zookeeper管理的hbase的节点个数,然后进行kill和启动新节点操作。
1:由于HBase依赖hdfs,所以下载的时候注意HBase的版本:
注:我使用的是hadoop2.4版本的,所以HBase选择支持2版本的:hbase-0.96.2-hadoop2-bin.tar.gz
2:上传hbase安装包,上传到一台机器即可:
建议:自己规划一下自己的机器,最好是独立的,再搞两台机器最好,
如果不想搞更多的机器,这里放到启动yarn进程的机器上:
如我的slaver5,slaver6(master节点,slaver1节点,slaver2节点安装Region Server,slaver5,slaver6安装Master ),
这样负载比较好点,自己电脑吃得消;
过程省略,上传结果如下所示;

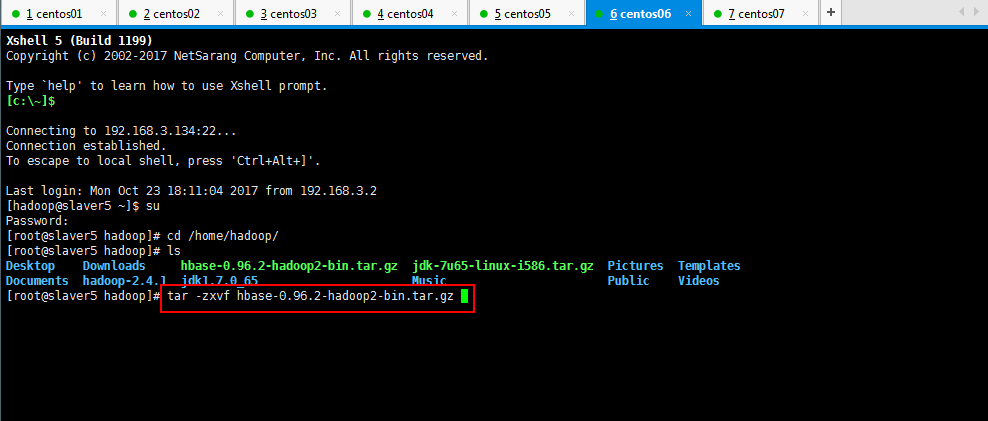
2:解压缩刚才上传的hbase-0.96.2-hadoop2-bin.tar.gz:
[root@slaver5 hadoop]# tar -zxvf hbase-0.96.2-hadoop2-bin.tar.gz
3:配置HBase集群,要修改3个文件(首先Zookeeper集群已经安装好了哟):
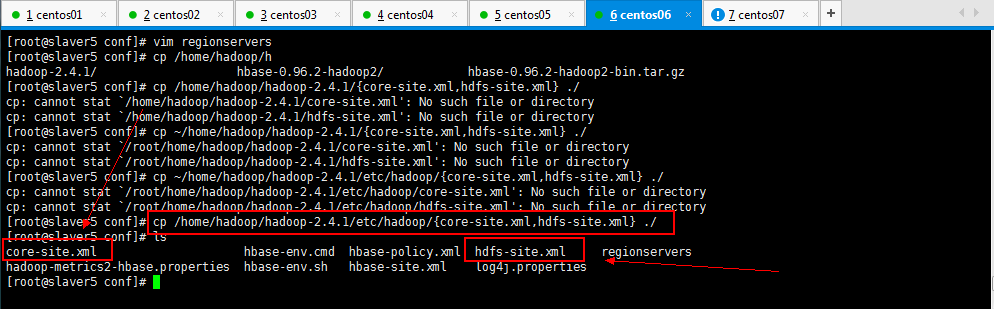
注意:要把hadoop的hdfs-site.xml和core-site.xml 放到HBase/conf下;
[root@slaver5 conf]# cp /home/hadoop/hadoop-2.4.1/etc/hadoop/{core-site.xml,hdfs-site.xml} ./
开始修改配置文件:
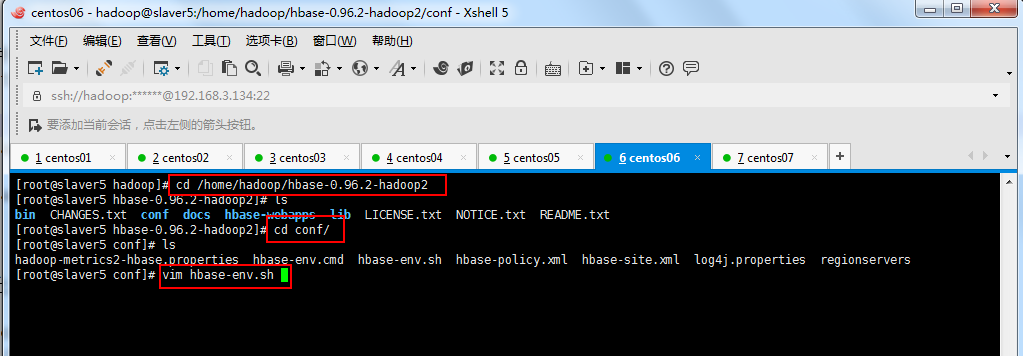
3.1:修改hbase-env.sh:
修改如下所示:
//自己的jdk路径 export JAVA_HOME=/usr/java/jdk1.7.0_55
//hadoop配置文件的位置
export HBASE_CLASSPATH=/home/hadoop/hadoop-2.4.1/conf
//更准确的应该配置下面这个路径信息
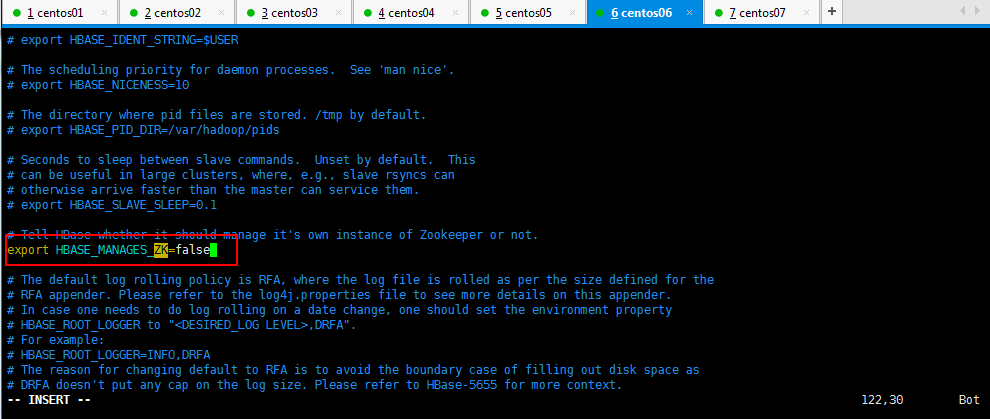
export HBASE_CLASSPATH=/home/hadoop/soft/hadoop-2.5.0-cdh5.3.6/etc/hadoop //告诉hbase使用外部的zk,export HBASE_MANAGES_ZK=true #如果使用独立安装的zookeeper这个地方就是false export HBASE_MANAGES_ZK=false
演示操作如下所示:
可以使用命令查看jdk的路径:
[root@slaver6 hadoop]# echo $JAVA_HOME
/home/hadoop/jdk1.7.0_65
[root@slaver6 hadoop]# 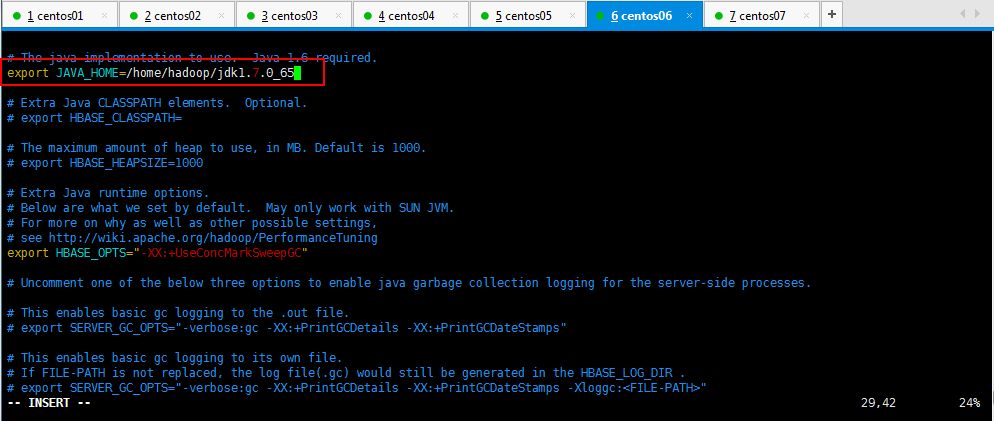
按ESC进入命令行模式:
搜索内容如下所示:
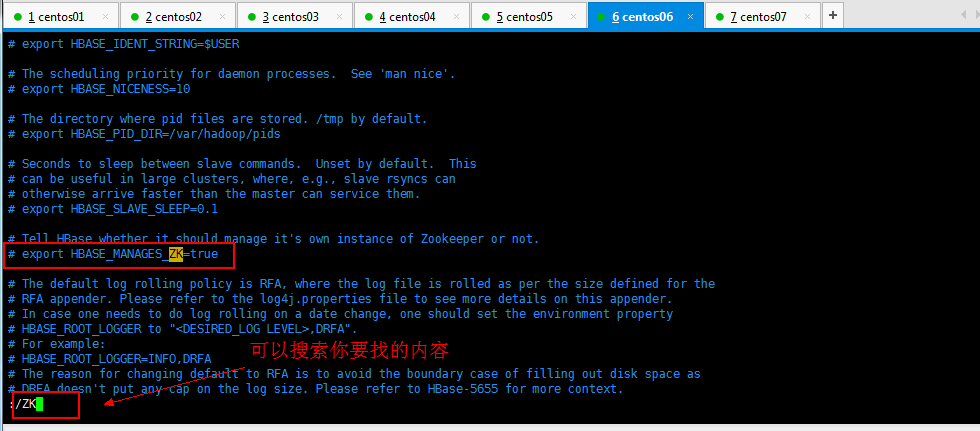
改成如下内容,使用外部的Zookeeper管理HBase:
3.2:修改hbase-site.xml,vim hbase-site.xml:
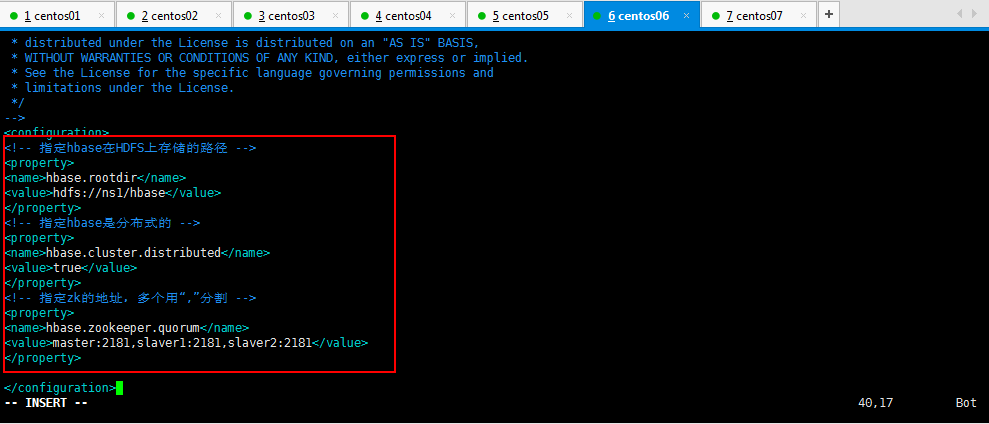
修改内容如下所示:
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<!--如果是三台机器,注意这个路径,比如hdfs://slaver1/hbase-->
<value>hdfs://ns1/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slaver1:2181,slaver2:2181</value>
</property>
</configuration>
配置或如下所示,下面的配置仅仅做一下参考,不是此篇博客配置的:
1 <configuration> 2 <property> 3 <!--hbasemaster的主机和端口--> 4 <name>hbase.master</name> 5 <value>master1:60000</value> 6 </property> 7 <property> 8 <!--时间同步允许的时间差--> 9 <name>hbase.master.maxclockskew</name> 10 <value>180000</value> 11 </property> 12 <property> 13 <name>hbase.rootdir</name> 14 <!--hbase共享目录,持久化hbase数据--> 15 <value>hdfs://hadoop-cluster1/hbase</value> 16 </property> 17 <property> 18 <!--是否分布式运行,false即为单机--> 19 <name>hbase.cluster.distributed</name> 20 <value>true</value> 21 </property> 22 <property> 23 <!--zookeeper地址--> 24 <name>hbase.zookeeper.quorum</name> 25 <value>slave1, slave2,slave3</value> 26 </property> 27 <property> 28 <!--zookeeper配置信息快照的位置--> 29 <name>hbase.zookeeper.property.dataDir</name> 30 <value>/home/hadoop/hbase/tmp/zookeeper</value> 31 </property> 32 </configuration>
修改操作如下所示:
[root@slaver5 conf]# vim hbase-site.xml
演示操作如下所示:
3.3:修改regionservers,vim regionservers:
因为master节点,slaver1节点,slaver2节点安装Region Server,所以这里配置一下,slaver5,slaver6安装Master就可以找到Region Server了;
4:然后将部署好的HBase传到其他几个节点上面(拷贝里面有html文档,拷贝起来有点慢,可以删除doc文档):
注:将配置好的HBase拷贝到每一个节点并同步时间。
[root@slaver5 hadoop]# scp -r hbase-0.96.2-hadoop2/ master:/home/hadoop/
[root@slaver5 hadoop]# scp -r hbase-0.96.2-hadoop2/ slaver1:/home/hadoop/
[root@slaver5 hadoop]# scp -r hbase-0.96.2-hadoop2/ slaver2:/home/hadoop/
[root@slaver5 hadoop]# scp -r hbase-0.96.2-hadoop2/ slaver6:/home/hadoop/

5:现在可以启动HBase了,不过启动HBase之前需要将HDFS启动起来(hdfs启动过程省略,之前启动好多次了),因为HBase在hdfs下面创建一个目录叫做hbase,自己配置的:
注:如果浏览器访问不了,记得关防火墙:service iptables stop,service iptables status;
启动所有的hbase
1:分别启动zk
./zkServer.sh start
2:启动hbase集群
start-dfs.sh
3:启动hbase,在主节点上运行:
start-hbase.sh
启动完hdfs之后启动HBase:
注意:hbase依赖hdfs,所以yarn可以暂时不启动的。

可以查看这几个节点的进程的启动情况:

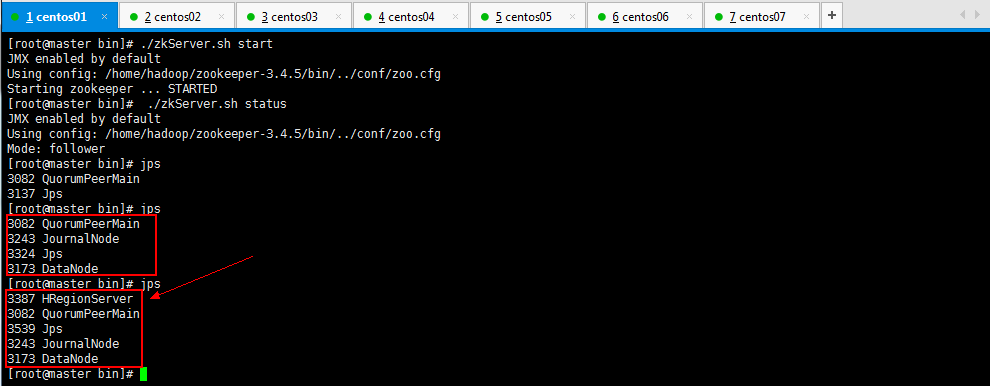

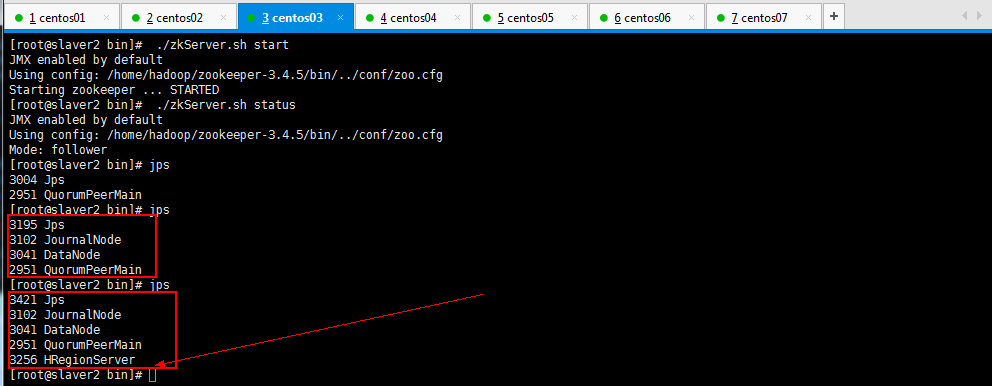
现在呢,一个HBase已经启动起来了,如果想启动两个HBase,第一个HBase启动不会自动启动第二个HBase,所以现在手动启动第二个HBase,操作如下所示:
注:为保证集群的可靠性,要启动多个HMaster

6:通过浏览器访问hbase管理页面
192.168.3.134:60010
可以看到三台master节点,slaver1节点,slaver2节点安装Region Server;slaver6是安装的备份的Master;

7:自己可以测试一下,杀死一个HMaster(slaver5节点的),另一个HMaster立马顶上去了,很强悍,依赖着Zookeeper,爽到爆啊。(kill -9 进程号,-9是强制杀死):
1 添加Hbase节点,删除的话直接kill: 2 [root@slaver6 hadoop]# hbase-daemon.sh start regionserver
8:使用HBase的命令行客户端操作一下HBase(测试使用,真实环境使用Java操作):
1 进入hbase的shell:hbase shell 2 退出hbase的shell:quit 3 页面:http://ip地址:60010/
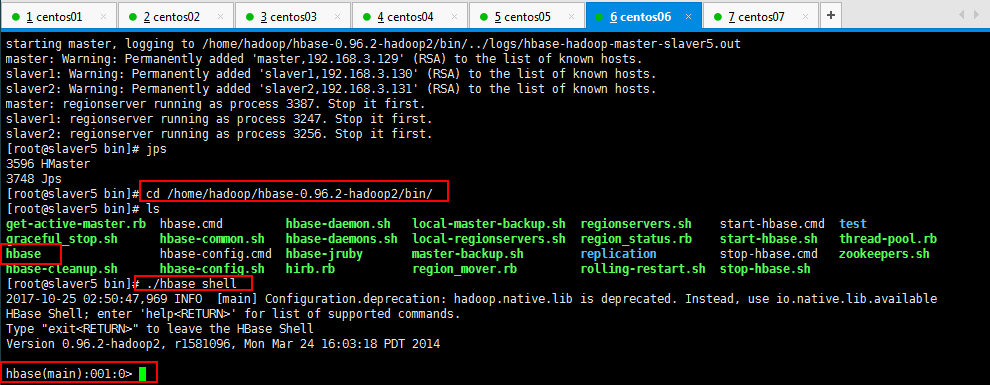
由于HBase是非关系型数据库,可以查看一下help看看都有啥命令,然后再操作:

可以查看一些基本的命令:

HBase的一些基本命令(如果在hbase shell客户端,打错了,可按ctrl+BackSpace进行删除):
1、#创建HBase数据表,如果不给定namespace的名称,默认创建在default命名空间中。 hbase(main):032:0> create 'myTables',{NAME => 'base_info',VERSIONS => 3},{NAME => 'extra_info'} hbase(main):016:0> create 'user','info01','info02' #创建带有命名空间的hbase数据表,20180408是命名空间,user是表名称,col1是列簇。
hbase(main):033:0> create '20180408:user','col1'
hbase(main):034:0> list
2、#查看有什么表,显示hbase表名称,类似mysql中的show tables;可以通过指定命名空间来查看对应命名空间中的表,默认是显示所有用户表,也支持模糊查询。类似命名list_namespace_table查看对命名空间内有那些表。 hbase(main):032:0> list 3、#查看表结构 describe 'myTables'
hbase(main):016:0> describe '20180408:user' 4、#禁用表 disable 'myTables' 5、#删除表,删除之前要先禁用表。删除用户表之前需要将表设置为disable,然后删除。其实在hbase中如果需要对已有表进行ddl操作,均需要将其disable,在ddl操作完成后,再进行enable操作即可。 drop 'myTables' hbase(main):040:0> disable '20180408:test'
hbase(main):041:0> drop '20180408:test'
hbase(main):042:0> list
5.1 #delete命令是删除指定table的指定rowkey的指定列,也就是说delete命令适合删除列的情况。如果需要删除当然rowkey的所有列数据,那么可以使用deleteall命令。
hbase(main):010:0> delete '20180408:user','row1','col1:sex'
hbase(main):012:0> deleteall '20180408:user','row1'
5.2 #清空数据表,truncate命令的作用是清空数据库,当我们数据库中的数据比较多的时候,我们可以选择该命令将数据库清空。底层原理是禁用表,删除表,创建表。
hbase(main):015:0> truncate '20180408:user'
6、#插入数据,插入一个表的一行的一列的一个值,最后一个字段不带。hbase的put命令是进行数据添加的命令。 #不带分号 #put '表名称','行','base_info/extra_info:列名称','列值' put 'myTables','0001','base_info:name','张三' put 'myTables','0001','base_info:age','22' put 'myTables','0001','base_info:sex','男' put 'myTables','0001','extra_info:addr','河南省' #带有命名空间的hbase数据表插入操作:
hbase(main):001:0> put '20180408:user','row1','col1:name','zhangsan'
hbase(main):004:0> put '20180408:user','row1','col1:sex','nan'
hbase(main):005:0> put '20180408:user','row1','col1:age','20'
7、#查询数据,查询某一行。get命名的作用是获取对应表中对应rowkey的数据。默认获取最新版本的全部列数据,可以通过时间戳指定版本信息,也可以指定获取的列。 get 'myTables','0001'
#row1是自己创建的行,注意,col1是列簇,都是自己创建的。 hbase(main):008:0> get '20180408:user','row1'
#查看指定行的指定列信息。
hbase(main):009:0> get '20180408:user','row1','col1:name'
get 'myTables','0001',{COLUMN => 'base_info:name',VERSION => 10}
#scan命令是hbase的另一种检索方式,是通过范围查找hbase中的数据。默认情况下是获取table的全部数据,可以通过指定column和filter等相关信息进行数据的过滤。
scan 'myTables' #可以查看插入的数据信息
hbase(main):006:0> scan '20180408:user'
#scan提供多种filter命令,常用的filter命令如下所示:ColumnPrefixFilter过滤列名是某前缀的,MultipleColumnValueExcludeFilter过滤多列的前缀只要满足其中一个的前缀,RowFilter满足那种类型的过滤,SingleColumnValueFilter某列的value值过滤,SingleColumnValueExcludeFilter过滤某列不符合给定的value值等等。需要注意的是,在指定的value之前需要加'binary';
hbase(main):012:0> scan '20180408:user',{FILTER=>"MultipleColumnPrefixFilter('n')"}
hbase(main):013:0> scan '20180408:user',{FILTER=>"MultipleColumnPrefixFilter('n','a')"}
hbase(main):001:0> scan '20180408:user',{FILTER=>"ColumnPrefixFilter('n')"}
hbase(main):002:0> scan '20180408:user',{FILTER=>"RowFilter(=,'binary:row1')"},注意,rowfilter需要给定两个参数,第一个参数:=,>,<,>=,<=。第二个参数是二进制的字符串数组。
hbase(main):001:0> scan '20180408:user',{FILTER=>"SingleColumnValueFilter('col1','name',=,'binary:zhangsan')"}
8、#修改值操作,默认不显示历史值 put 'myTables','0001','base_info:name','李四'
9、namespace的相关命令:
#创建命名空间,create_namespace命令
hbase(main):019:0> create_namespace '20180408',{'comment'=>'this is my namespace'}
#显示命名空间,显示所有存在的命名空间,可以使用正则,可以验证自己创建的命名空间是否创建成功,也可以去hdfs上面查看。
hbase(main):020:0> list_namespace
hbase(main):020:0> list_namespace '20180408.*'
#删除命名空间,删除指定的命名空间,注意删除的命名空间内不能有table存在,也就是说只能删除空的namespace。
hbase(main):021:0> drop_namespace '20180408'
#显示命名空间的相关信息。describe_namespace命令。
hbase(main):026:0> describe_namespace '20180408'
#查看这个命名空间下面的hbase数据表。
hbase(main):035:0> list_namespace_table '20180408'
10、count命令是统计hbase表行数的一个命令,由于相当于一个内置的mapreduce程序,所以当数据量比较大的时候可以选择使用协处理器方式计算行数。默认情况下INTERVAL是1000间隔数,CACHE是10。
hbase(main):001:0> count '20180408:user'
hbase(main):002:0> count '20180408:user',INTERVAL=2
可以去Zookeeper查看hbase的一些信息:
1 [root@master sbin]# cd /home/hadoop/zookeeper-3.4.5/ 2 [root@master zookeeper-3.4.5]# ls 3 bin conf dist-maven ivy.xml NOTICE.txt recipes zookeeper-3.4.5.jar.asc 4 build.xml contrib docs lib README_packaging.txt src zookeeper-3.4.5.jar.md5 5 CHANGES.txt data ivysettings.xml LICENSE.txt README.txt zookeeper-3.4.5.jar zookeeper-3.4.5.jar.sha1 6 [root@master zookeeper-3.4.5]# cd bin/ 7 [root@master bin]# ls 8 README.txt zkCleanup.sh zkCli.cmd zkCli.sh zkEnv.cmd zkEnv.sh zkServer.cmd zkServer.sh zookeeper.out 9 [root@master bin]# ./zkCli.sh 10 Connecting to localhost:2181 11 2017-12-18 17:08:22,357 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.5-1392090, built on 09/30/2012 17:52 GMT 12 2017-12-18 17:08:22,383 [myid:] - INFO [main:Environment@100] - Client environment:host.name=master 13 2017-12-18 17:08:22,383 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.7.0_65 14 2017-12-18 17:08:22,383 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation 15 2017-12-18 17:08:22,385 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/home/hadoop/jdk1.7.0_65/jre 16 2017-12-18 17:08:22,385 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/home/hadoop/zookeeper-3.4.5/bin/../build/classes:/home/hadoop/zookeeper-3.4.5/bin/../build/lib/*.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/slf4j-log4j12-1.6.1.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/slf4j-api-1.6.1.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/netty-3.2.2.Final.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/log4j-1.2.15.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/jline-0.9.94.jar:/home/hadoop/zookeeper-3.4.5/bin/../zookeeper-3.4.5.jar:/home/hadoop/zookeeper-3.4.5/bin/../src/java/lib/*.jar:/home/hadoop/zookeeper-3.4.5/bin/../conf: 17 2017-12-18 17:08:22,385 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/i386:/lib:/usr/lib 18 2017-12-18 17:08:22,386 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp 19 2017-12-18 17:08:22,387 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA> 20 2017-12-18 17:08:22,396 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux 21 2017-12-18 17:08:22,397 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=i386 22 2017-12-18 17:08:22,397 [myid:] - INFO [main:Environment@100] - Client environment:os.version=2.6.32-358.el6.i686 23 2017-12-18 17:08:22,398 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root 24 2017-12-18 17:08:22,428 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root 25 2017-12-18 17:08:22,470 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/home/hadoop/zookeeper-3.4.5/bin 26 2017-12-18 17:08:22,472 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@1238fa5 27 Welcome to ZooKeeper! 28 2017-12-18 17:08:22,994 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@966] - Opening socket connection to server localhost/0:0:0:0:0:0:0:1:2181. Will not attempt to authenticate using SASL (unknown error) 29 JLine support is enabled 30 2017-12-18 17:08:23,281 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@849] - Socket connection established to localhost/0:0:0:0:0:0:0:1:2181, initiating session 31 2017-12-18 17:08:24,145 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1207] - Session establishment complete on server localhost/0:0:0:0:0:0:0:1:2181, sessionid = 0x16068706a9b0008, negotiated timeout = 30000 32 33 WATCHER:: 34 35 WatchedEvent state:SyncConnected type:None path:null 36 [zk: localhost:2181(CONNECTED) 0] ls / 37 [hadoop-ha, hbase, admin, zookeeper, consumers, config, 20171011, storm, yarn-leader-election, brokers, controller_epoch] 38 [zk: localhost:2181(CONNECTED) 3] get /hbase 39 40 cZxid = 0xc00000007 41 ctime = Wed Oct 25 17:29:19 CST 2017 42 mZxid = 0xc00000007 43 mtime = Wed Oct 25 17:29:19 CST 2017 44 pZxid = 0xf0000004a 45 cversion = 23 46 dataVersion = 0 47 aclVersion = 0 48 ephemeralOwner = 0x0 49 dataLength = 0 50 numChildren = 15 51 [zk: localhost:2181(CONNECTED) 4] ls / 52 [hadoop-ha, hbase, admin, zookeeper, consumers, config, 20171011, storm, yarn-leader-election, brokers, controller_epoch] 53 [zk: localhost:2181(CONNECTED) 5] ls /hbase 54 [meta-region-server, backup-masters, region-in-transition, draining, table, table-lock, running, master, namespace, hbaseid, online-snapshot, replication, recovering-regions, splitWAL, rs] 55 [zk: localhost:2181(CONNECTED) 6] ls /hbase/table 56 [hbase:meta, hbase:namespace, user] 57 [zk: localhost:2181(CONNECTED) 7]
待续......