豆瓣里可以搜到评分前250的电影。https://movie.douban.com/top250 ,可是分成了25页,我只能一页一页的看。想要一次看完250条,因此有了下面使用xpath的爬虫,把250条电影数据放进csv文件:


1 import requests 2 import lxml.html 3 import csv 4 5 doubanUrl = 'https://movie.douban.com/top250?start={}&filter=' #{}用于匹配参数 6 7 def getSource(url): 8 ''' 9 获取网页源代码。 10 :param url: 11 :return: String 12 ''' 13 content = requests.get(url) 14 content.encoding = 'utf-8' #万能编码 15 #强制修改编码,防止Windows下出现乱码 16 return content.content 17 18 19 def getEveryItem(source): 20 ''' 21 获取每一个电影的相关信息。movie_dict字典用于保存电影的信息。 22 :param source: 23 :return: [movie1_dict, movie2_dict, movie3_dict,...] 24 ''' 25 selector = lxml.html.document_fromstring(source) 26 movieItemList= selector.xpath('//div[@class="info"]') #如果不从html开始都需要// 此处使用到了先抓大再抓小的技巧 27 movieList = [] 28 29 30 for eachMoive in movieItemList: 31 movieDict = {} 32 title = eachMoive.xpath('div[@class="hd"]/a/span[@class="title"]/text()') 33 print(title) 34 otherTitle = eachMoive.xpath('div[@class="hd"]/a/span[@class="other"]/text()') 35 36 link = eachMoive.xpath('div[@class="hd"]/a/@href')[0] 37 print('看看多少a标签') 38 print(eachMoive.xpath('div[@class="hd"]/a/@href')[:]) 39 40 41 42 directorAndActor = eachMoive.xpath('div[@class="bd"]/p[@class=""]/text()') 43 star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0] 44 quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()') 45 if quote: 46 quote = quote[0] 47 else: 48 quote = '' 49 50 movieDict['title'] = ''.join(title + otherTitle) 51 movieDict['url'] = link 52 #你可以试一试直接打印''.join(directorAndActor),看看他的格式是多么的混乱 53 movieDict['directorAndActor'] = ''.join(directorAndActor).replace(' ', '').replace(' ', '').replace(' ', '') #可以同时多个替换 54 movieDict['star'] = star 55 movieDict['quote'] = quote 56 57 movieList.append(movieDict) #把抓到的每个电影房进集合里 58 return movieList 59 60 def writeData(movieList): 61 with open('doubanMovie_example2.csv', 'w', encoding='UTF-8', newline='') as f: #需要新建个doubanMovie_example2.csv文件 62 writer = csv.DictWriter(f, fieldnames=['title', 'directorAndActor', 'star', 'quote', 'url']) 63 writer.writeheader() 64 for each in movieList: 65 print(each) 66 writer.writerow(each) 67 68 if __name__ == '__main__': 69 movieList = [] 70 for i in range(10): 71 pageLink = doubanUrl.format(i * 25) #给url格式化 每次拿25条 从第一页开始即i为0开始 ,世事无绝对还得看爬虫网址的规律。 72 print(pageLink) 73 source = getSource(pageLink) 74 movieList += getEveryItem(source) 75 print(movieList[:10]) #把十页数据即250条拿来看看 76 movieList = sorted(movieList, key=lambda k: k['star'], reverse=True) #根据字典中的key=star这一项的value来排序,倒序。 77 writeData(movieList)
显示结果:
1、控制台显示
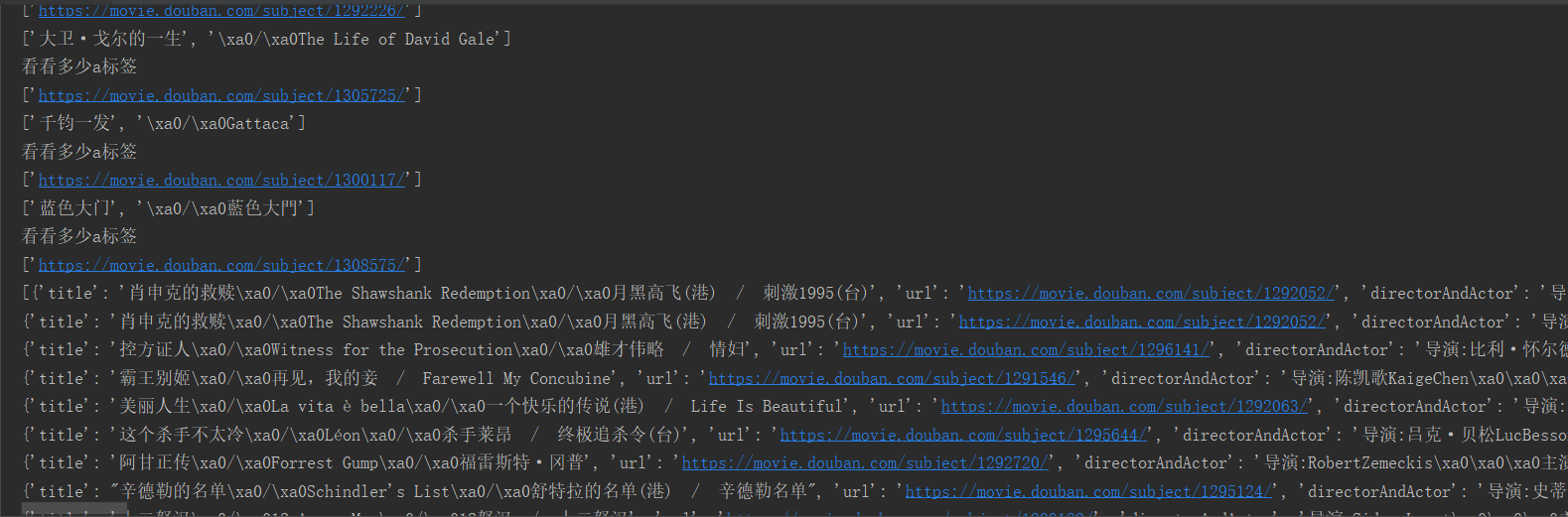
2、csv文件,用excel打开,可能中文出现乱码,这时用记事本打开并且另存为utf-8文件,再打开就好了。