awk用法
awk [ -F ':'] '{pattern+action}' 以:为分隔符(默认是空格)
cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7"} END {print "blue,/bin/nosh"}' 显示passwd文件的用户名和shell,并给它们起列名name,shell,并且在后面添加blue,/bin/nosh,如果不需要列名,就直接cat /etc/passwd | awk -F ':' '{print $1","$7}'
awk -F : '/root/' /etc/passwd 搜索有root的所有行
awk -F : '/root/{print $7}' /etc/passwd打印出$7的shell值
awk '{count++;print $0;}END{print "user count is " count}' 根据passwd文件统计用多少用户,END代表最后执行的,如果去掉的话会没打印一个用户就打印一条统计语句
类似:ls -l |awk 'BEGIN {size=0;} {size=size+$5} END {print "[end]size is ",size}'统计该文件夹内的文件总共占用多少内存,$5是文件占用大小
常用选项
awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v] 大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
' ' 引用代码块
BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以是字符串或正则表达式
{} 命令代码块,包含一条或多条命令
; 多条命令使用分号分隔
END 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
特殊要点:
$0 表示整个当前行
$1 每行第一个字段
NF 字段数量变量
NR 每行的记录号,多文件记录递增
FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
制表符
换行符
FS BEGIN时定义分隔符
RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
~ 匹配,与==相比不是精确比较
!~ 不匹配,不精确比较
== 等于,必须全部相等,精确比较
!= 不等于,精确比较
&& 逻辑与
|| 逻辑或
+ 匹配时表示1个或1个以上
/[0-9][0-9]+/ 两个或两个以上数字
/[0-9][0-9]*/ 一个或一个以上数字
FILENAME 文件名
OFS 输出字段分隔符, 默认也是空格,可以改为制表符等
ORS 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
-F'[:#/]' 定义三个分隔符
例子:
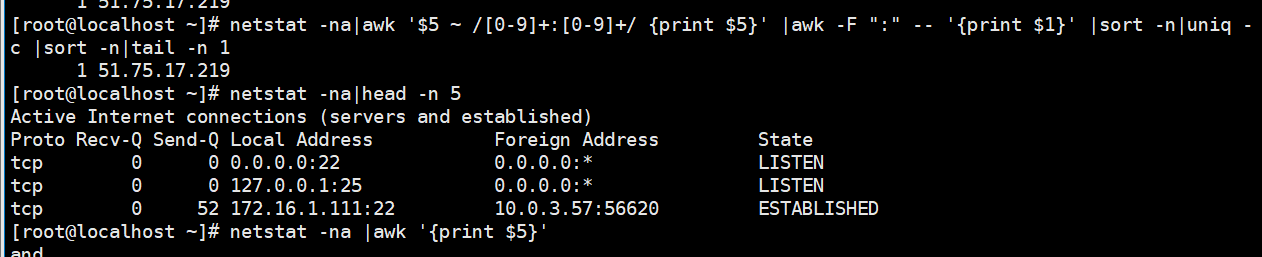
1.匹配字符串中的ip 解释:awk默认已空格作为分隔符,$5为第五列,~为匹配内容,//里面的为匹配内容,[0-9]+:[0-9]+为匹配数字:数字,然后将筛选后的结果的第一列按照大小排列,接着计算重复的ip,根据重复ip的次数再次排列
netstat -na|awk '$5 ~ /[0-9]+:[0-9]+/ {print $5}' |awk -F ":" -- '{print $1}' |sort -n|uniq -c |sort -n|tail -n 1
效果