
1. 前言
想学好前端,先练好内功,内功不行,就算招式练的再花哨,终究成不了高手。
非线性表(树、堆),可以说是前端程序员的内功,要知其然,知其所以然。
笔者写的 JavaScript 数据结构与算法之美 系列用的语言是 JavaScript ,旨在入门数据结构与算法和方便以后复习。
非线性表中的树、堆是干嘛用的 ?其数据结构是怎样的 ?
希望大家带着这两个问题阅读下文。
2. 树
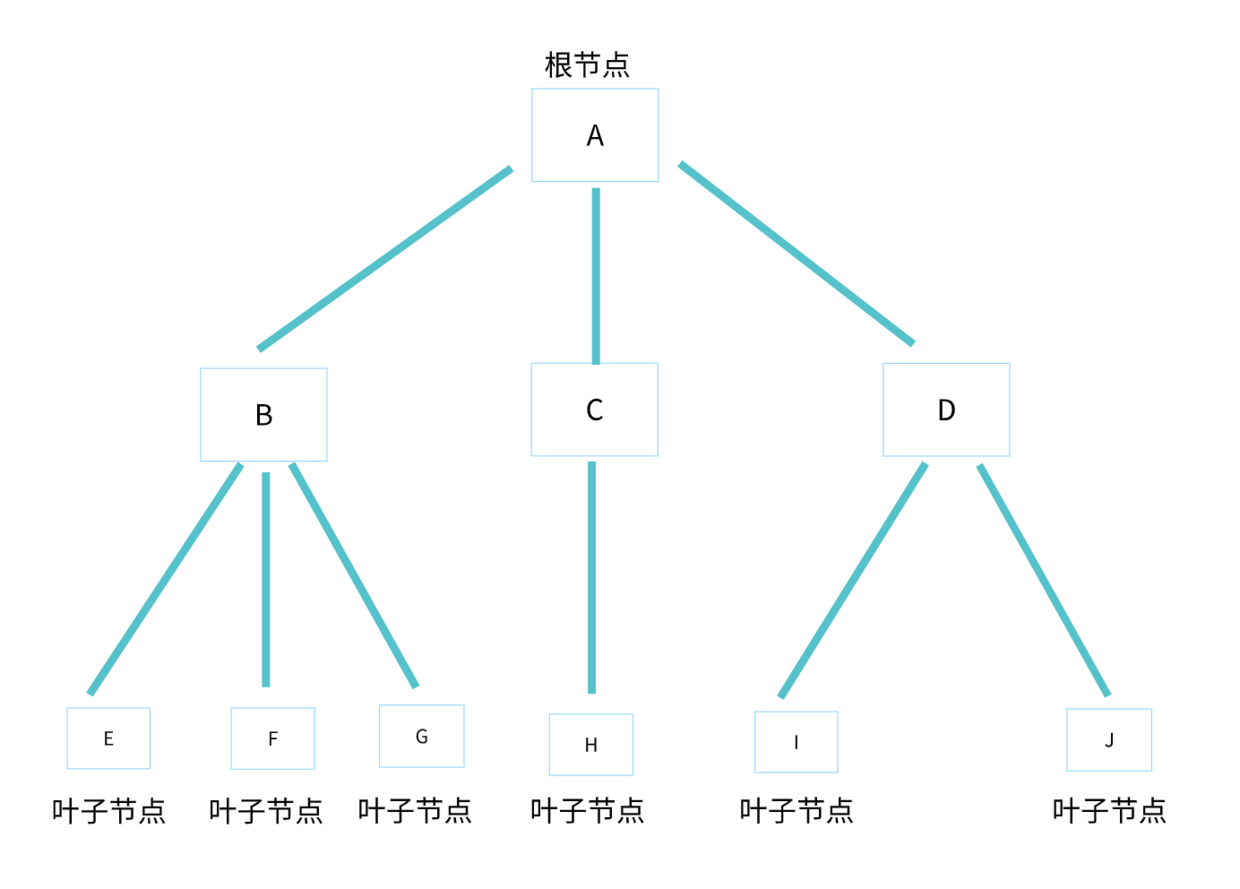
树的数据结构就像我们生活中的真实的树,只不过是倒过来的形状。
术语定义
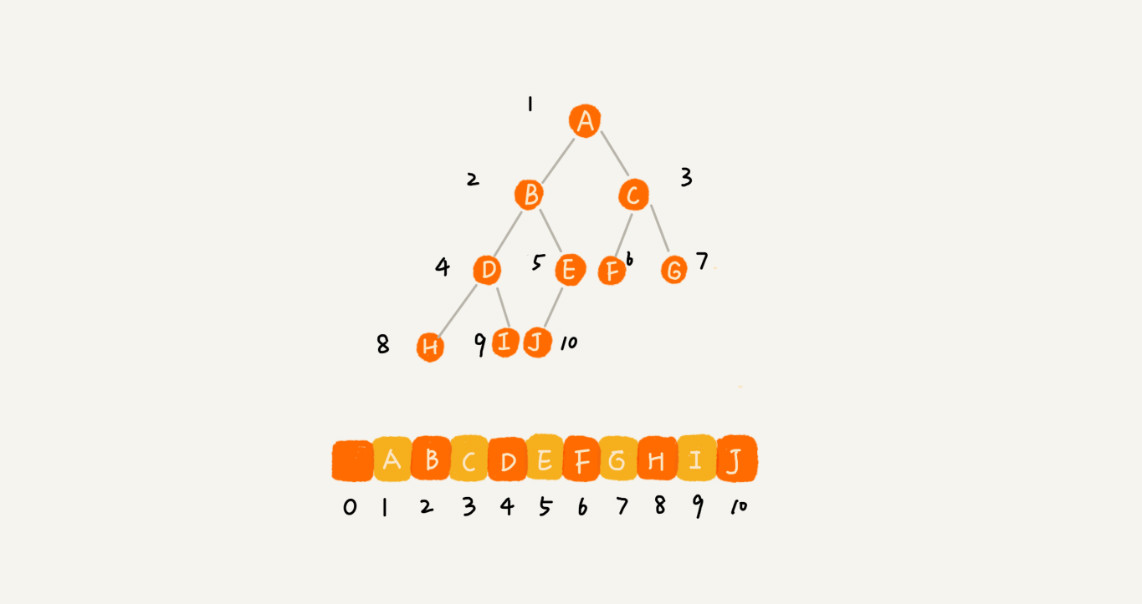
- 节点:树中的每个元素称为节点,如 A、B、C、D、E、F、G、H、I、J。
- 父节点:指向子节点的节点,如 A。
- 子节点:被父节点指向的节点,如 A 的孩子 B、C、D。
- 父子关系:相邻两节点的连线,称为父子关系,如 A 与 B,C 与 H,D 与 J。
- 根节点:没有父节点的节点,如 A。
- 叶子节点:没有子节点的节点,如 E、F、G、H、I、J。
- 兄弟节点:具有相同父节点的多个节点称为兄弟节点,如 B、C、D。
- 节点的高度:节点到叶子节点的
最长路径所包含的边数。 - 节点的深度:根节点到节点的路径所包含的边数。
- 节点层数:节点的深度 +1(根节点的层数是 1 )。
- 树的高度:等于根节点的高度。
- 森林: n 棵互不相交的树的集合。

高度是从下往上度量,比如一个人的身高 180cm ,起点就是从 0 开始的。
深度是从上往下度量,比如泳池的深度 180cm ,起点也是从 0 开始的。
高度和深度是带有度字的,都是从 0 开始计数的。
而层数的计算,是和我们平时的楼层的计算是一样的,最底下那层是第 1 层,是从 1 开始计数的,所以根节点位于第 1 层,其他子节点依次加 1。
二叉树分类
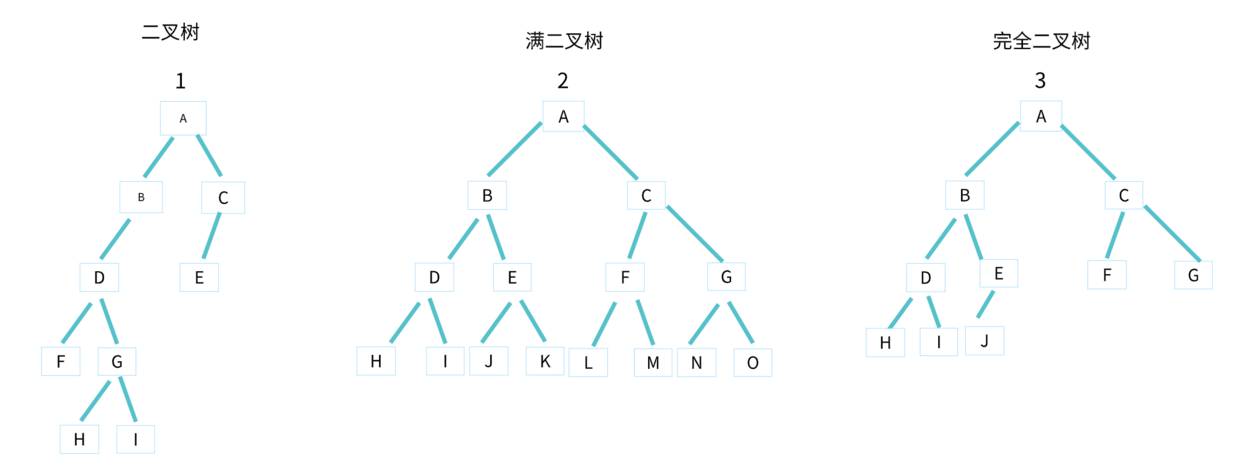
二叉树
- 每个节点
最多只有2 个子节点的树,这两个节点分别是左子节点和右子节点。如上图中的 1、 2、3。
不过,二叉树并不要求每个节点都有两个子节点,有的节点只有左子节点,有的节点只有右子节点。以此类推,自己想四叉树、八叉树的结构图。
满二叉树
- 一种特殊的二叉树,除了叶子节点外,每个节点
都有左右两个子节点,这种二叉树叫做满二叉树。如上图中的 2。
完全二叉树
- 一种特殊的二叉树,叶子节点都在最底下两层,最后一层叶子节都靠
左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫做完全二叉树。如上图的 3。
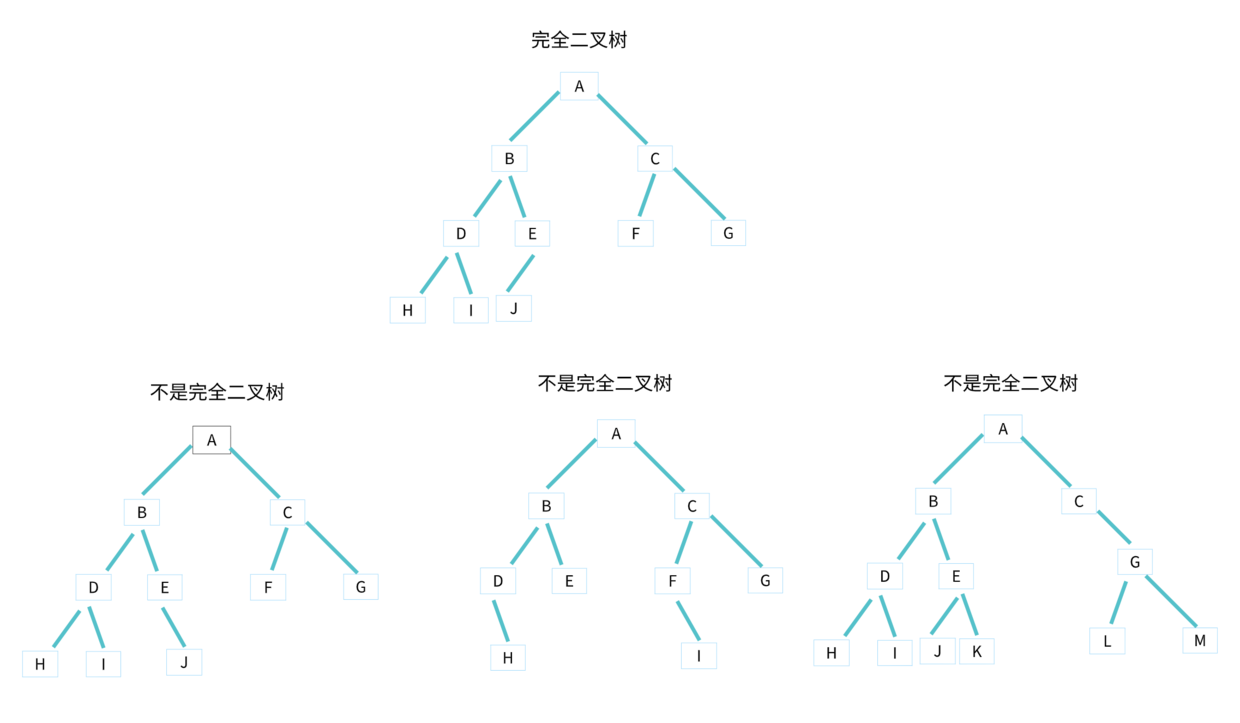
完全二叉树与不是完全二叉树的区分比较难,所以对比下图看看。
堆
之前的文章 栈内存与堆内存 、浅拷贝与深拷贝 中有说到:JavaScript 中的引用类型(如对象、数组、函数等)是保存在堆内存中的对象,值大小不固定,栈内存中存放的该对象的访问地址指向堆内存中的对象,JavaScript 不允许直接访问堆内存中的位置,因此操作对象时,实际操作对象的引用。
那么堆到底是什么呢 ?其数据结构又是怎样的呢 ?
堆其实是一种特殊的树。只要满足这两点,它就是一个堆。
- 堆是一个完全二叉树。
完全二叉树:除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。 - 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
也可以说:堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。这两种表述是等价的。
对于每个节点的值都大于等于子树中每个节点值的堆,我们叫作大顶堆。对于每个节点的值都小于等于子树中每个节点值的堆,我们叫作小顶堆。
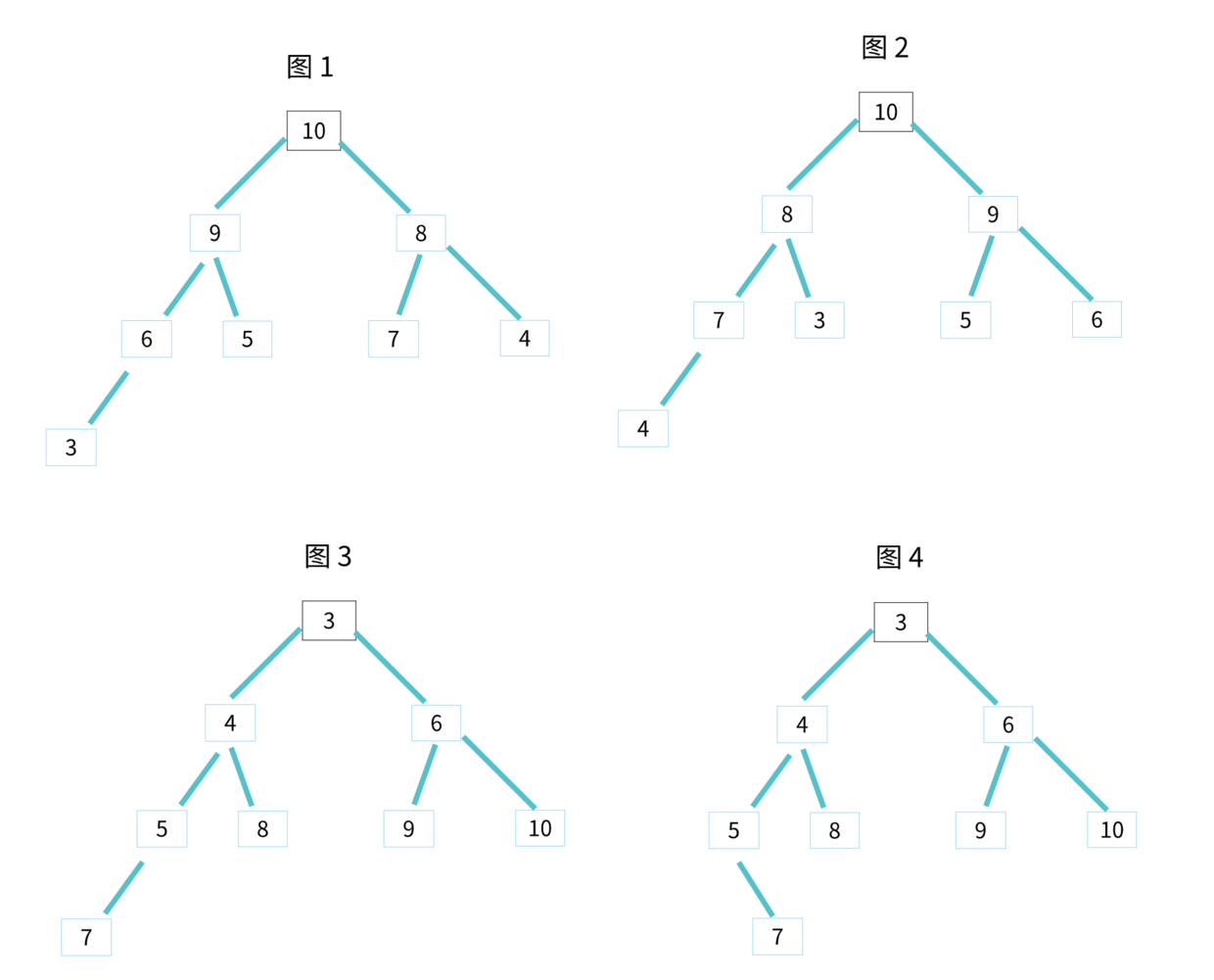
其中图 1 和 图 2 是大顶堆,图 3 是小顶堆,图 4 不是堆。除此之外,从图中还可以看出来,对于同一组数据,我们可以构建多种不同形态的堆。
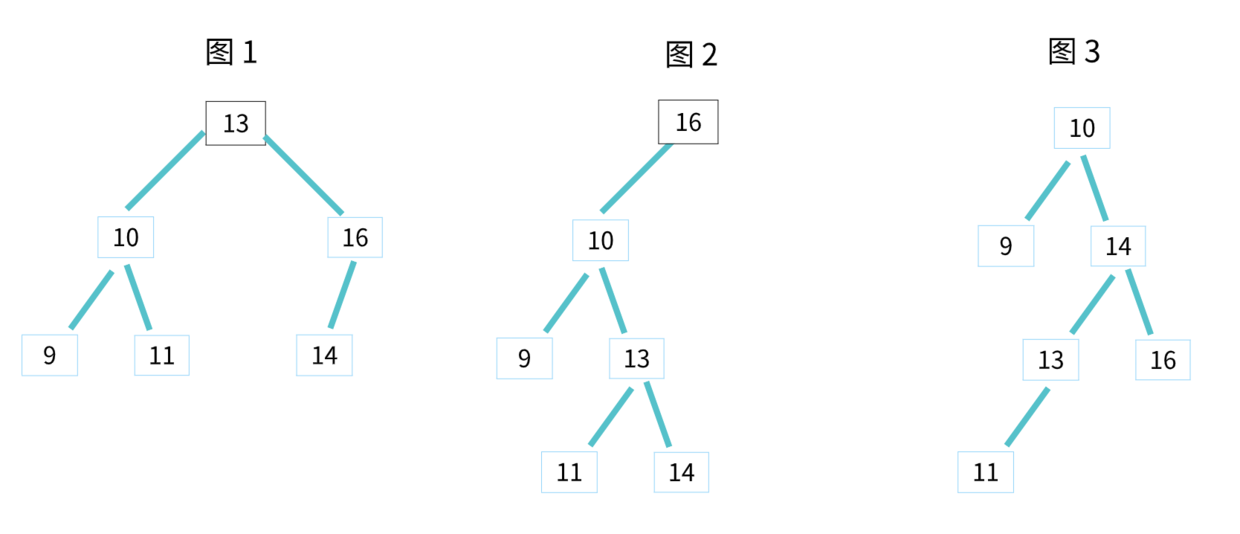
二叉查找树(Binary Search Tree)
- 一种特殊的二叉树,相对
较小的值保存在左节点中,较大的值保存在右节点中,叫二叉查找树,也叫二叉搜索树。
二叉查找树是一种有序的树,所以支持快速查找、快速插入、删除一个数据。
下图中, 3 个都是二叉查找树,
平衡二叉查找树
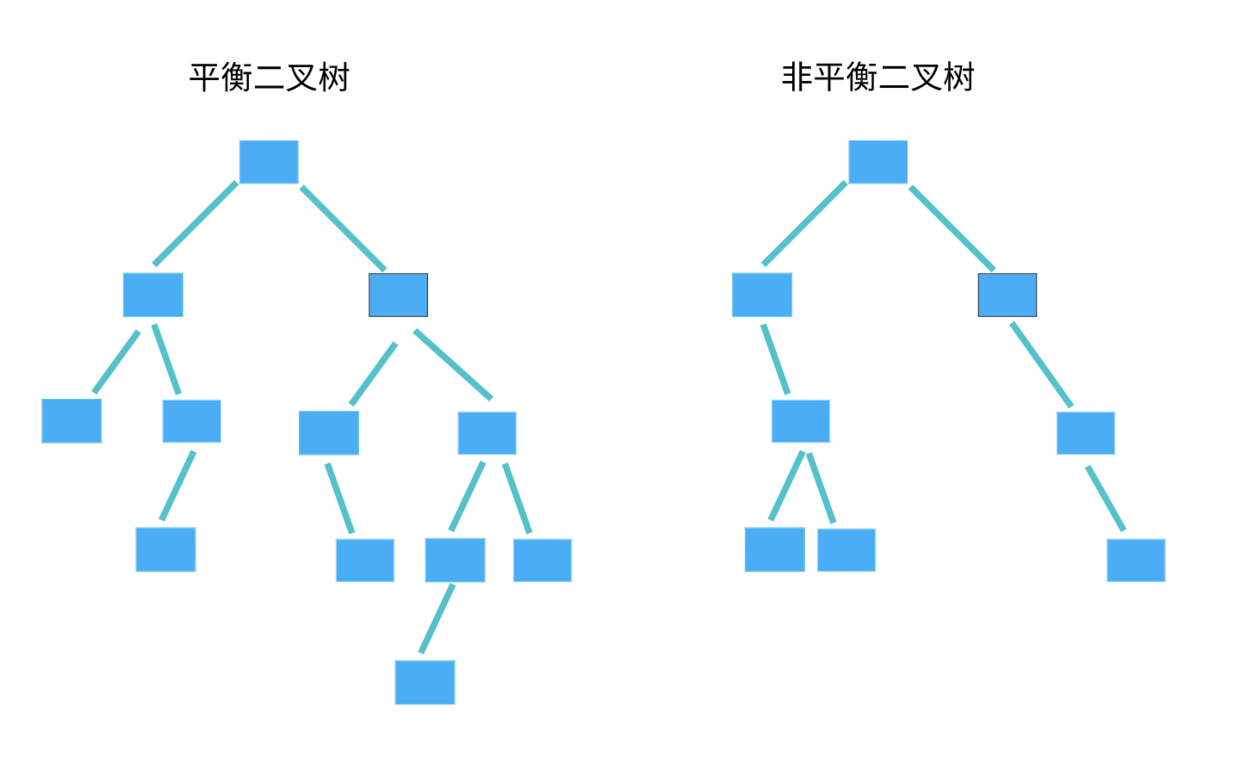
- 平衡二叉查找树:二叉树中任意一个节点的左右子树的高度相差不能大于 1。
从这个定义来看,完全二叉树、满二叉树其实都是平衡二叉树,但是非完全二叉树也有可能是平衡二叉树。
平衡二叉查找树中平衡的意思,其实就是让整棵树左右看起来比较对称、比较平衡,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些。
平衡二叉查找树其实有很多,比如,Splay Tree(伸展树)、Treap(树堆)等,但是我们提到平衡二叉查找树,听到的基本都是红黑树。
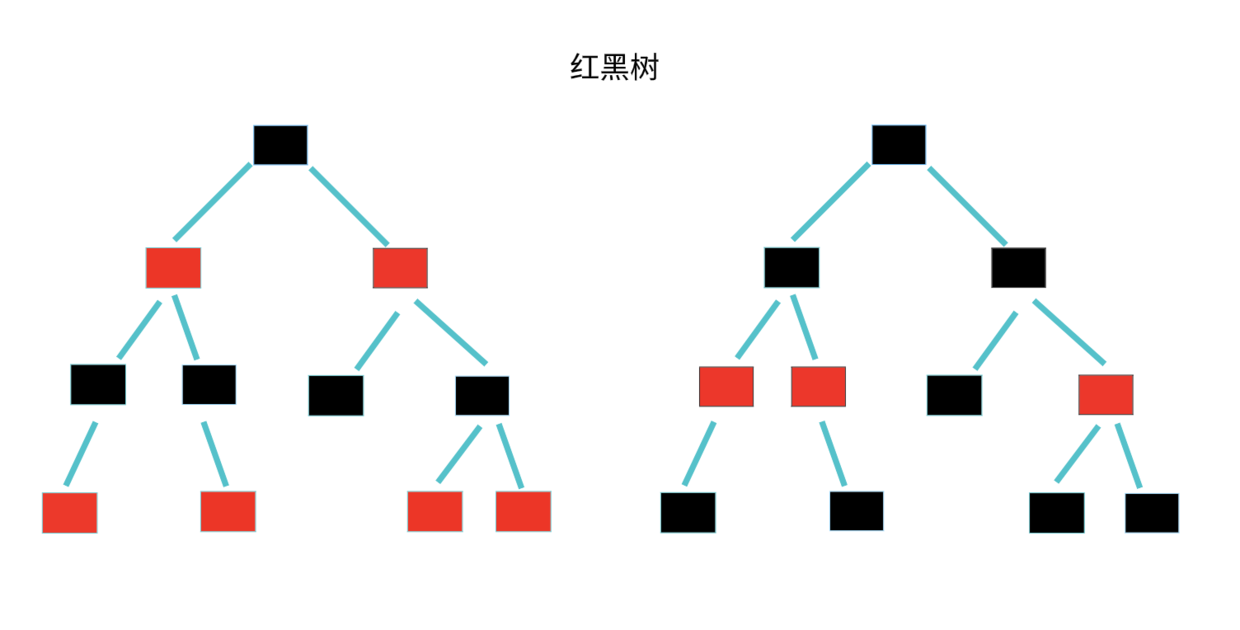
红黑树(Red-Black Tree)
红黑树中的节点,一类被标记为黑色,一类被标记为红色。除此之外,一棵红黑树还需要满足这样几个要求:
- 根节点是黑色的。
- 每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据。
- 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的。
- 每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点。
下面两个都是红黑树。
存储
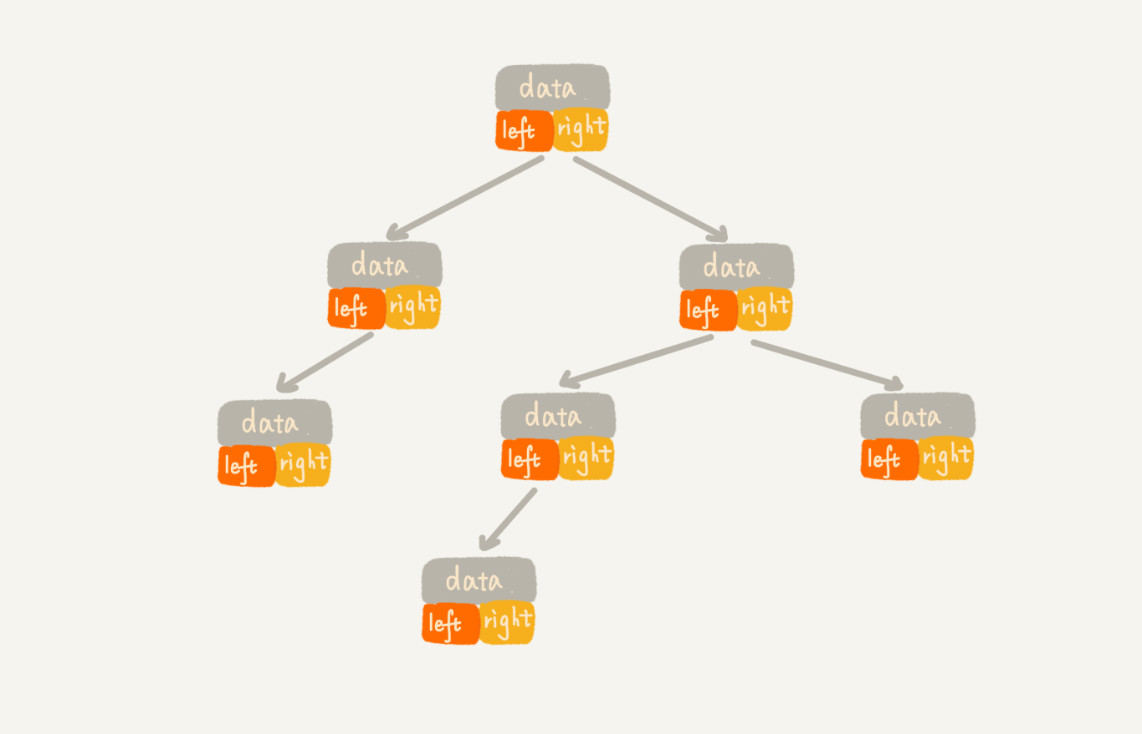
完全二叉树的存储
- 链式存储
每个节点由 3 个字段,其中一个存储数据,另外两个是指向左右子节点的指针。
我们只要拎住根节点,就可以通过左右子节点的指针,把整棵树都串起来。
这种存储方式比较常用,大部分二叉树代码都是通过这种方式实现的。
- 顺序存储
用数组来存储,对于完全二叉树,如果节点 X 存储在数组中的下标为 i ,那么它的左子节点的存储下标为 2 * i ,右子节点的下标为 2 * i + 1,反过来,下标 i / 2 位置存储的就是该节点的父节点。
注意,根节点存储在下标为 1 的位置。完全二叉树用数组来存储是最省内存的方式。
二叉树的遍历
经典的方法有三种:前序遍历、中序遍历、后序遍历。其中,前、中、后序,表示的是节点与它的左右子树节点遍历访问的先后顺序。
前序遍历(根 => 左 => 右)
- 对于树中的任意节点来说,先访问这个节点,然后再访问它的左子树,最后访问它的右子树。
中序遍历(左 => 根 => 右)
- 对于树中的任意节点来说,先访问它的左子树,然后再访问它的本身,最后访问它的右子树。
后序遍历(左 => 右 => 根)
- 对于树中的任意节点来说,先访问它的左子树,然后再访问它的右子树,最后访问它本身。
实际上,二叉树的前、中、后序遍历就是一个递归的过程。
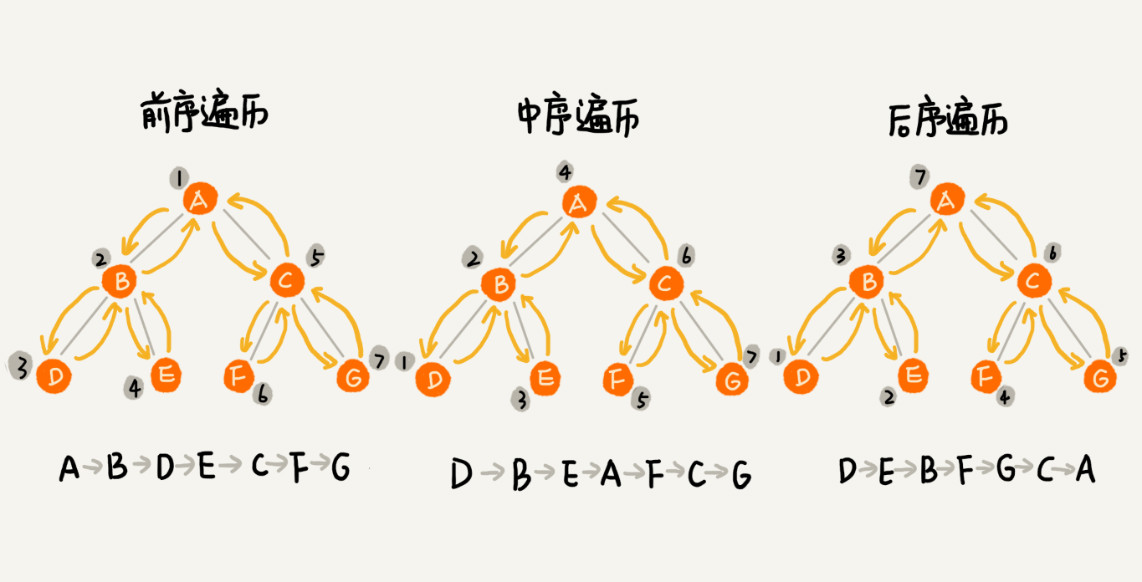
时间复杂度:3 种遍历方式中,每个节点最多会被访问 2 次,跟节点的个数 n 成正比,所以时间复杂度是 O(n)。
实现二叉查找树
二叉查找树的特点是:相对较小的值保存在左节点中,较大的值保存在右节点中。
代码实现二叉查找树,方法有以下这些。
方法
- insert(key):向树中插入一个新的键。
- search(key):在树中查找一个键,如果节点存在,则返回 true;如果不存在,则返回 false。
- min:返回树中最小的值/键。
- max:返回树中最大的值/键。
- remove(key):从树中移除某个键。
遍历
- preOrderTraverse:通过
先序遍历方式遍历所有节点。 - inOrderTraverse:通过
中序遍历方式遍历所有节点。 - postOrderTraverse:通过
后序遍历方式遍历所有节点。
具体代码
- 首先实现二叉查找树类的类
// 二叉查找树类
function BinarySearchTree() {
// 用于实例化节点的类
var Node = function(key){
this.key = key; // 节点的健值
this.left = null; // 指向左节点的指针
this.right = null; // 指向右节点的指针
};
var root = null; // 将根节点置为null
}
- insert 方法,向树中插入一个新的键。
遍历树,将插入节点的键值与遍历到的节点键值比较,如果前者大于后者,继续递归遍历右子节点,反之,继续遍历左子节点,直到找到一个空的节点,在该位置插入。
this.insert = function(key){
var newNode = new Node(key); // 实例化一个节点
if (root === null){
root = newNode; // 如果树为空,直接将该节点作为根节点
} else {
insertNode(root,newNode); // 插入节点(传入根节点作为参数)
}
};
// 插入节点的函数
var insertNode = function(node, newNode){
// 如果插入节点的键值小于当前节点的键值
// (第一次执行insertNode函数时,当前节点就是根节点)
if (newNode.key < node.key){
if (node.left === null){
// 如果当前节点的左子节点为空,就直接在该左子节点处插入
node.left = newNode;
} else {
// 如果左子节点不为空,需要继续执行insertNode函数,
// 将要插入的节点与左子节点的后代继续比较,直到找到能够插入的位置
insertNode(node.left, newNode);
}
} else {
// 如果插入节点的键值大于当前节点的键值
// 处理过程类似,只是insertNode函数继续比较的是右子节点
if (node.right === null){
node.right = newNode;
} else {
insertNode(node.right, newNode);
}
}
}
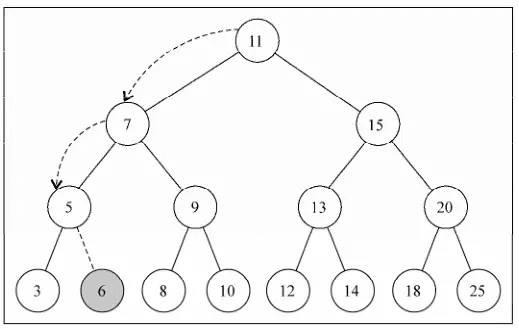
在下图的树中插入健值为 6 的节点,过程如下:
- 搜索最小值
在二叉搜索树里,不管是整个树还是其子树,最小值一定在树最左侧的最底层。
因此给定一颗树或其子树,只需要一直向左节点遍历到底就行了。
this.min = function(node) {
// min方法允许传入子树
node = node || root;
// 一直遍历左侧子节点,直到底部
while (node && node.left !== null) {
node = node.left;
}
return node;
};
- 搜索最大值
搜索最大值与搜索最小值类似,只是沿着树的右侧遍历。
this.max = function(node) {
// min方法允许传入子树
node = node || root;
// 一直遍历左侧子节点,直到底部
while (node && node.right !== null) {
node = node.right;
}
return node;
};
- 搜索特定值
搜索特定值的处理与插入值的处理类似。遍历树,将要搜索的值与遍历到的节点比较,如果前者大于后者,则递归遍历右侧子节点,反之,则递归遍历左侧子节点。
this.search = function(key, node){
// 同样的,search方法允许在子树中查找值
node = node || root;
return searchNode(key, node);
};
var searchNode = function(key, node){
// 如果node是null,说明树中没有要查找的值,返回false
if (node === null){
return false;
}
if (key < node.key){
// 如果要查找的值小于该节点,继续递归遍历其左侧节点
return searchNode(node.left, key);
} else if (key > node.key){
// 如果要查找的值大于该节点,继续递归遍历其右侧节点
return searchNode(node.right, key);
} else {
// 如果要查找的值等于该节点,说明查找成功,返回改节点
return node;
}
};
- 移除节点
移除节点,首先要在树中查找到要移除的节点,再判断该节点是否有子节点、有一个子节点或者有两个子节点,最后分别处理。
this.remove = function(key, node) {
// 同样的,允许仅在子树中删除节点
node = node || root;
return removeNode(key, node);
};
var self = this;
var removeNode = function(key, node) {
// 如果 node 不存在,直接返回
if (node === false) {
return null;
}
// 找到要删除的节点
node = self.search(key, node);
// 第一种情况,该节点没有子节点
if (node.left === null && node.right === null) {
node = null;
return node;
}
// 第二种情况,该节点只有一个子节点的节点
if (node.left === null) {
// 只有右节点
node = node.right;
return node;
} else if (node.right === null) {
// 只有左节点
node = node.left;
return node;
}
// 第三种情况,有有两个子节点的节点
// 将右侧子树中的最小值,替换到要删除的位置
// 找到最小值
var aux = self.min(node.right);
// 替换
node.key = aux.key;
// 删除最小值
node.right = removeNode(aux.key, node.right);
return node;
};
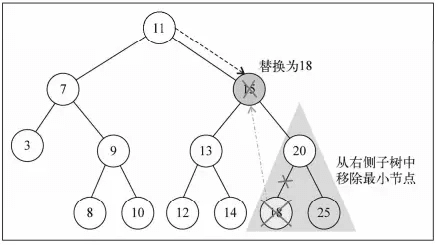
第三种情况的处理过程,如下图所示。
当要删除的节点有两个子节点时,为了不破坏树的结构,删除后要替补上来的节点的键值大小必须在已删除节点的左、右子节点的键值之间,且替补上来的节点不应该有子节点,否则会产生一个节点有多个字节点的情况,因此,找右侧子树的最小值替换上来。
同理,找左侧子树的最大值替换上来也可以。
- 先序遍历
this.preOrderTraverse = function(callback){
// 同样的,callback用于对遍历到的节点做操作
preOrderTraverseNode(root, callback);
};
var preOrderTraverseNode = function (node, callback) {
// 遍历到node为null为止
if (node !== null) {
callback(node.key); // 先处理当前节点
preOrderTraverseNode(node.left, callback); // 再继续遍历左子节点
preOrderTraverseNode(node.right, callback); // 最后遍历右子节点
}
};
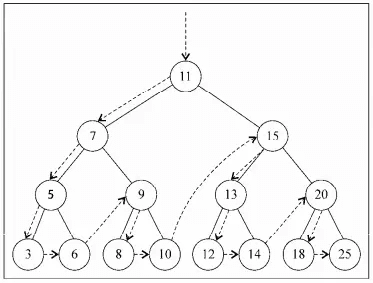
用先序遍历遍历下图所示的树,并打印节点键值。
输出结果:11 7 5 3 6 9 8 10 15 13 12 14 20 18 25。
遍历过程如图:

- 中序遍历
this.inOrderTraverse = function(callback){
// callback用于对遍历到的节点做操作
inOrderTraverseNode(root, callback);
};
var inOrderTraverseNode = function (node, callback) {
// 遍历到node为null为止
if (node !== null) {
// 优先遍历左边节点,保证从小到大遍历
inOrderTraverseNode(node.left, callback);
// 处理当前的节点
callback(node.key);
// 遍历右侧节点
inOrderTraverseNode(node.right, callback);
}
};
对下图的树做中序遍历,并输出各个节点的键值。
依次输出:3 5 6 7 8 9 10 11 12 13 14 15 18 20 25。
遍历过程如图:
- 后序遍历
this.postOrderTraverse = function(callback){
postOrderTraverseNode(root, callback);
};
var postOrderTraverseNode = function (node, callback) {
if (node !== null) {
postOrderTraverseNode(node.left, callback); //{1}
postOrderTraverseNode(node.right, callback); //{2}
callback(node.key); //{3}
}
};
可以看到,中序、先序、后序遍历的实现方式几乎一模一样,只是 {1}、{2}、{3} 行代码的执行顺序不同。
对下图的树进行后序遍历,并打印键值:3 6 5 8 10 9 7 12 14 13 18 25 20 15 11。
遍历过程如图:

- 添加打印的方法 print。
this.print = function() {
console.log('root :', root);
return root;
};
完整代码请看文件 binary-search-tree.html
测试过程:
// 测试
var binarySearchTree = new BinarySearchTree();
var arr = [11, 7, 5, 3, 6, 9, 8, 10, 15, 13, 12, 14, 20, 18, 25];
for (var i = 0; i < arr.length; i++) {
var value = arr[i];
binarySearchTree.insert(value);
}
console.log('先序遍历:');
var arr = [];
binarySearchTree.preOrderTraverse(function(value) {
// console.log(value);
arr.push(value);
});
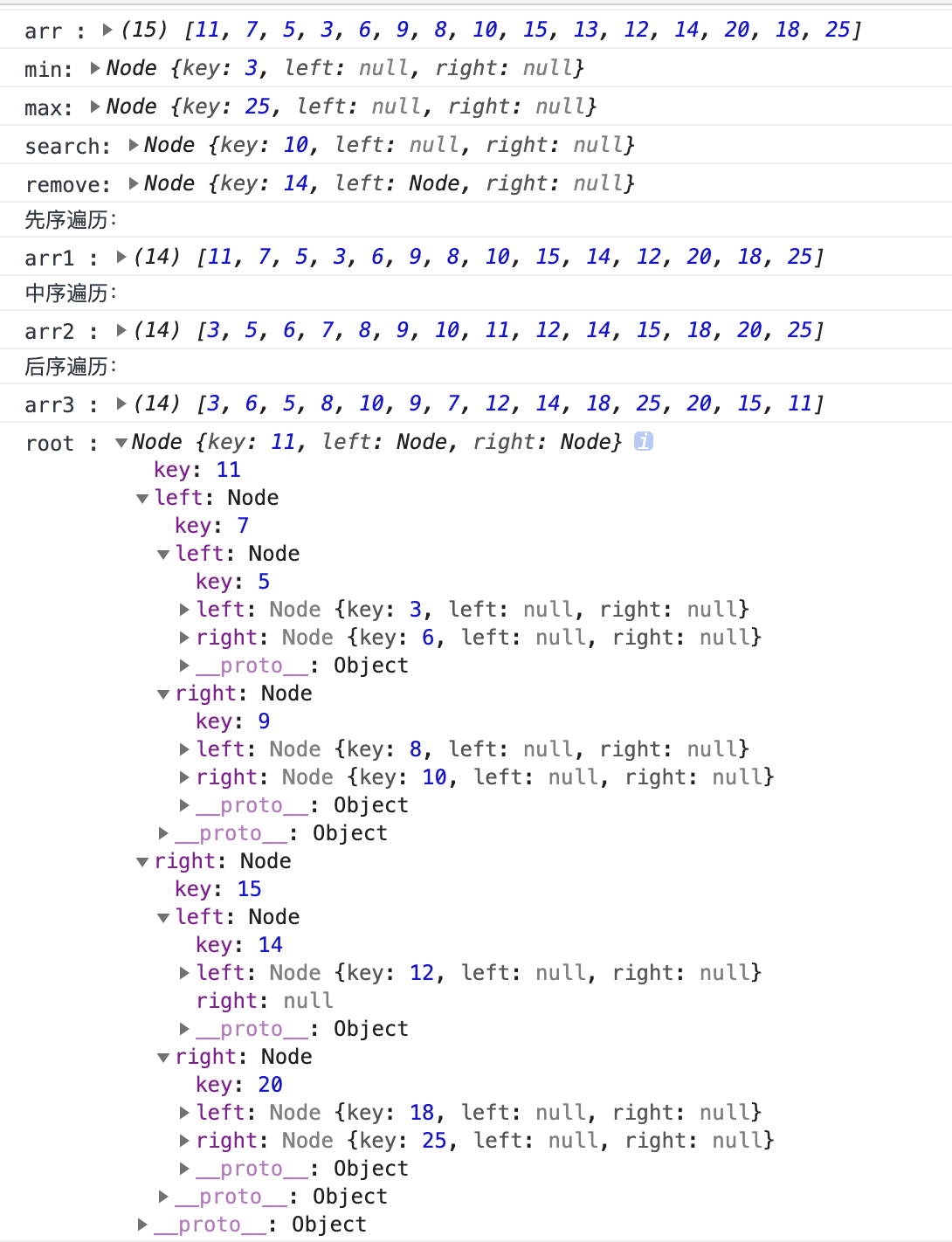
console.log('arr :', arr); // [11, 7, 5, 3, 6, 9, 8, 10, 15, 13, 12, 14, 20, 18, 25]
var min = binarySearchTree.min();
console.log('min:', min); // 3
var max = binarySearchTree.max();
console.log('max:', max); // 25
var search = binarySearchTree.search(10);
console.log('search:', search); // 10
var remove = binarySearchTree.remove(13);
console.log('remove:', remove); // 13
console.log('先序遍历:');
var arr1 = [];
binarySearchTree.preOrderTraverse(function(value) {
// console.log(value);
arr1.push(value);
});
console.log('arr1 :', arr1); // [11, 7, 5, 3, 6, 9, 8, 10, 15, 14, 12, 20, 18, 25]
console.log('中序遍历:');
var arr2 = [];
binarySearchTree.inOrderTraverse(function(value) {
// console.log(value);
arr2.push(value);
});
console.log('arr2 :', arr2); // [3, 5, 6, 7, 8, 9, 10, 11, 12, 14, 15, 18, 20, 25]
console.log('后序遍历:');
var arr3 = [];
binarySearchTree.postOrderTraverse(function(value) {
// console.log(value);
arr3.push(value);
});
console.log('arr3 :', arr3); // [3, 6, 5, 8, 10, 9, 7, 12, 14, 18, 25, 20, 15, 11]
binarySearchTree.print(); // 看控制台
结果如下:
看到这里,你能解答文章的题目 非线性表中的树、堆是干嘛用的 ?其数据结构是怎样的 ?
如果不能,建议再回头仔细看看哦。
3. 最后
如果觉得本文还不错,记得给个 star , 你的 star 是我持续更新的动力。
笔者 GitHub。
参考文章: