1.了解正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就易如反掌了。
正则表达式的大致匹配过程是:
1.依次拿出表达式和文本中的字符比较,
2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
3.如果表达式中有量词或边界,这个过程会稍微有一些不同。
2.正则表达式的语法规则
请自行百度,有更详细的讲解。
3.Python Re模块
(1)re.match(pattern, string[, flags])
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
1.string: 匹配时使用的文本。
2.re: 匹配时使用的Pattern对象。
3.pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
4.endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
5.lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
6.lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。方法:
1.group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
2.groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
3.groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
4.start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
5.end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
6.span([group]):
返回(start(group), end(group))。
7.expand(template):
将匹配到的分组代入template中然后返回。template中可以使用id或g、g引用分组,但不能使用编号0。id与g是等价的;但10将被认为是第10个分组,如果你想表达1之后是字符’0’,只能使用g0。
下面我们用一个例子来体会一下

(2)re.search(pattern, string[, flags])
search方法与match方法极其类似,区别在于match()函数只检测re是不是在string的开始位置匹配,search()会扫描整个string查找匹配,match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回None。同样,search方法的返回对象同样match()返回对象的方法和属性。

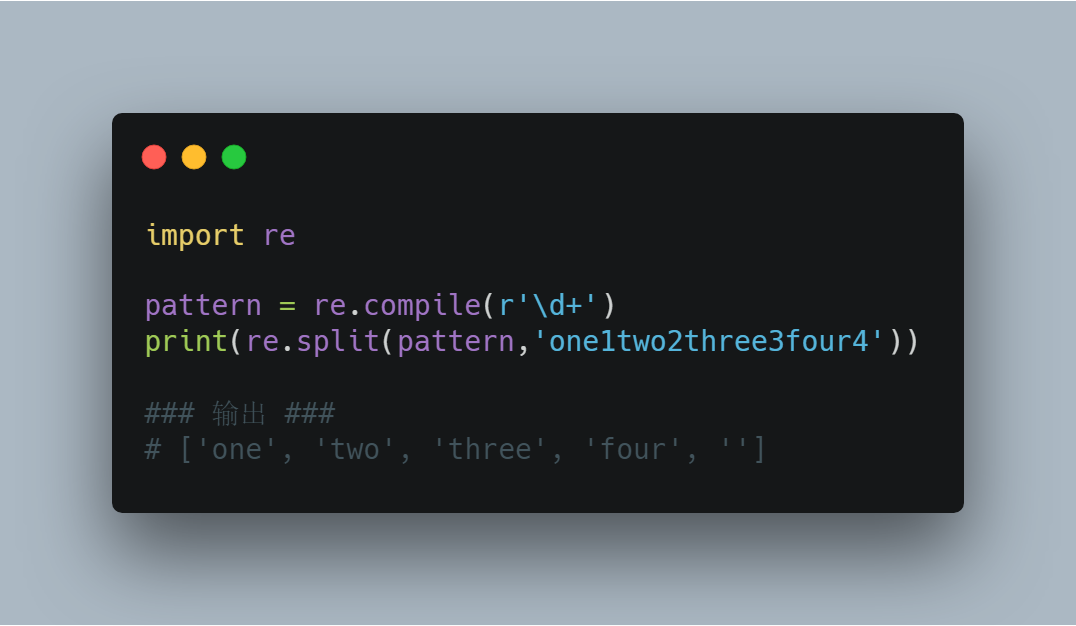
(3)re.split(pattern, string[, maxsplit])
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
(4)re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。

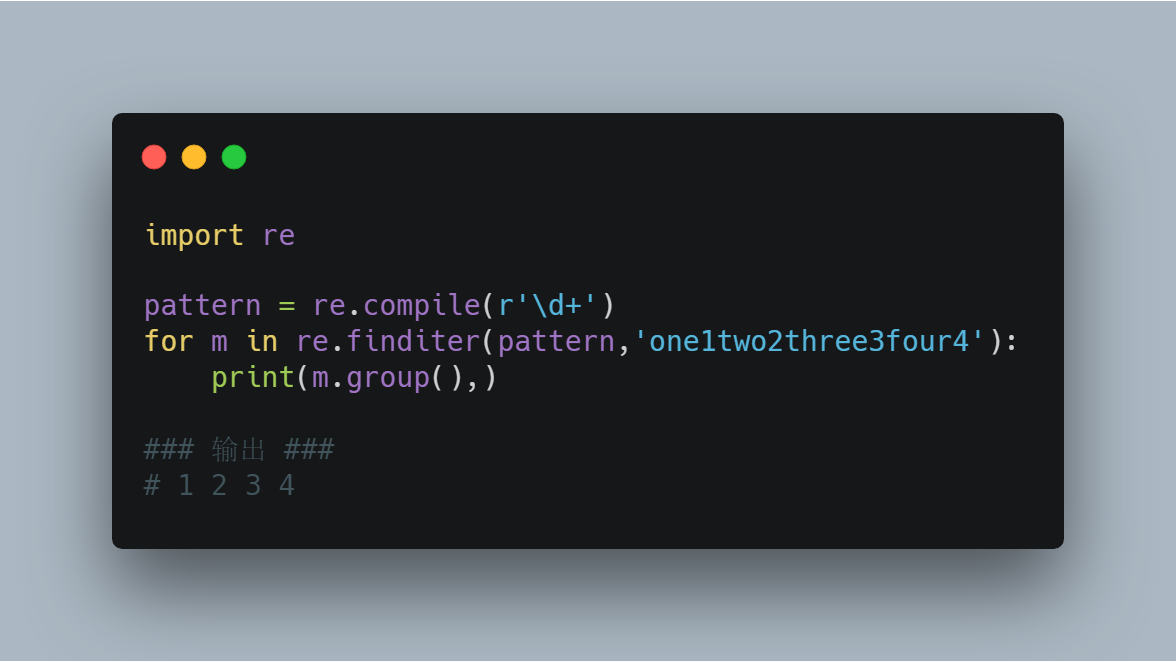
(5)re.finditer(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。
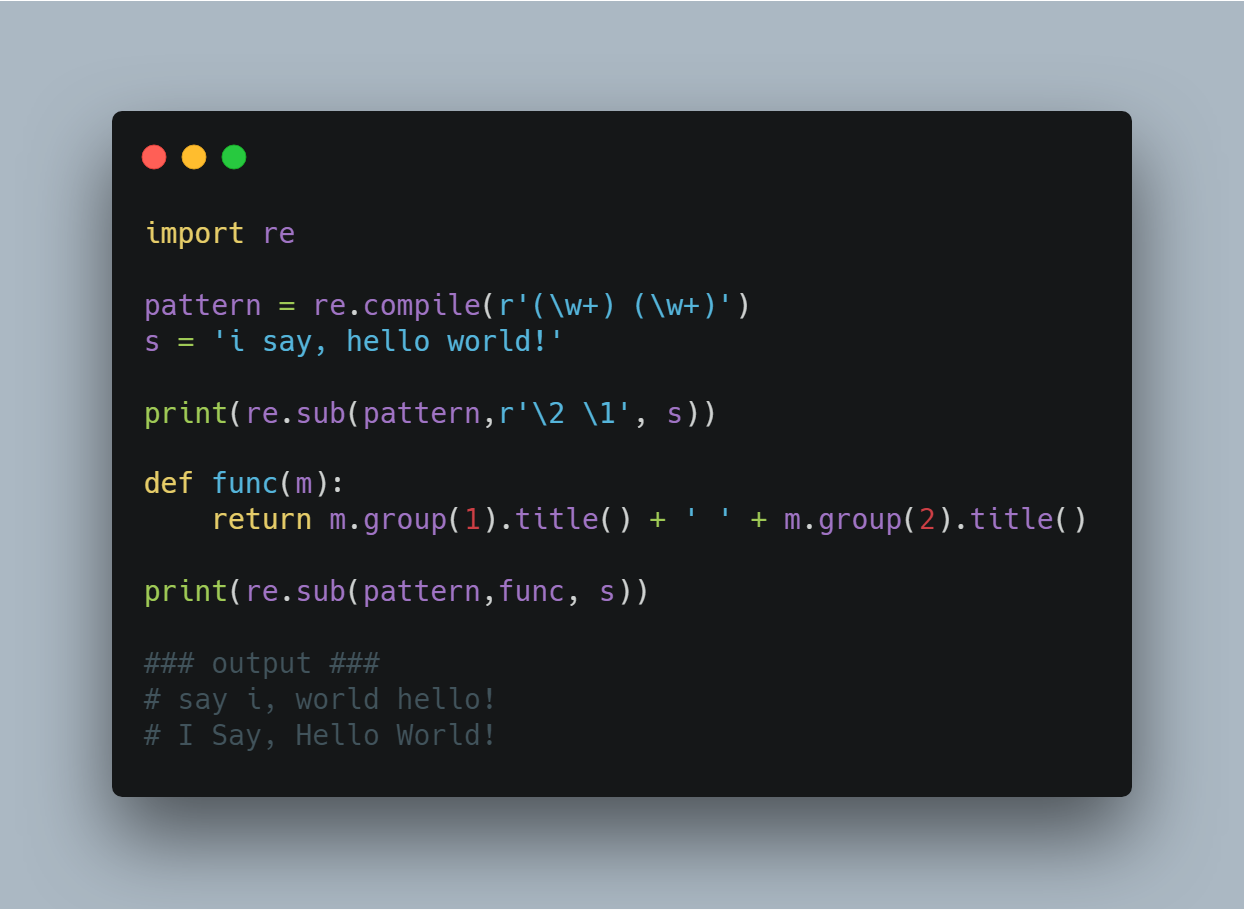
(6)re.sub(pattern, repl, string[, count])
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用id或g、g引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
(7)re.subn(pattern, repl, string[, count])
返回 (sub(repl, string[, count]), 替换次数)。
5.Python Re模块的另一种使用方式
在上面我们介绍了7个工具方法,例如match,search等等,不过调用方式都是 re.match,re.search的方式,其实还有另外一种调用方式,可以通过pattern.match,pattern.search调用,这样调用便不用将pattern作为第一个参数传入了,大家想怎样调用皆可。
函数API列表


1 match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]) 2 search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]) 3 split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]) 4 findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]) 5 finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]) 6 sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]) 7 subn(repl, string[, count]) |re.sub(pattern, repl, string[, count])
下面放出本文源代码
1 import re 2 3 pattern = re.compile(r'(w+) (w+)') 4 s = 'i say, hello world!' 5 6 print(re.subn(pattern,r'2 1', s)) 7 8 def func(m): 9 return m.group(1).title() + ' ' + m.group(2).title() 10 11 print(re.subn(pattern,func, s)) 12 13 ### output ### 14 # ('say i, world hello!', 2) 15 # ('I Say, Hello World!', 2) 16 17 ''' 18 import re 19 20 pattern = re.compile(r'(w+) (w+)') 21 s = 'i say, hello world!' 22 23 print(re.sub(pattern,r'2 1', s)) 24 25 def func(m): 26 return m.group(1).title() + ' ' + m.group(2).title() 27 28 print(re.sub(pattern,func, s)) 29 30 ### output ### 31 # say i, world hello! 32 # I Say, Hello World! 33 ''' 34 ''' 35 import re 36 37 pattern = re.compile(r'd+') 38 for m in re.finditer(pattern,'one1two2three3four4'): 39 print(m.group(),) 40 41 ### 输出 ### 42 # 1 2 3 4 43 ''' 44 45 ''' 46 import re 47 48 pattern = re.compile(r'd+') 49 print(re.findall(pattern,'one1two2three3four4')) 50 51 ### 输出 ### 52 # ['1', '2', '3', '4'] 53 54 ''' 55 ''' 56 import re 57 58 pattern = re.compile(r'd+') 59 print(re.split(pattern,'one1two2three3four4')) 60 61 ### 输出 ### 62 # ['one', 'two', 'three', 'four', ''] 63 ''' 64 ''' 65 # -*- coding: utf-8 -*- 66 #导入re模块 67 import re 68 69 # 将正则表达式编译成Pattern对象 70 pattern = re.compile(r'world') 71 # 使用search()查找匹配的子串,不存在能匹配的子串时将返回None 72 # 这个例子中使用match()无法成功匹配 73 match = re.search(pattern,'hello world!') 74 if match: 75 # 使用Match获得分组信息 76 print(match.group()) 77 ### 输出 ### 78 # world 79 ''' 80 81 ''' 82 # -*- coding: utf-8 -*- 83 #一个简单的match实例 84 85 import re 86 # 匹配如下内容:单词+空格+单词+任意字符 87 m = re.match(r'(w+) (w+)(?P<sign>.*)', 'hello world!') 88 89 print("m.string:", m.string) 90 print("m.re:", m.re) 91 print("m.pos:", m.pos) 92 print("m.endpos:", m.endpos) 93 print("m.lastindex:", m.lastindex) 94 print("m.lastgroup:", m.lastgroup) 95 print("m.group():", m.group()) 96 print("m.group(1,2):", m.group(1, 2)) 97 print("m.groups():", m.groups()) 98 print("m.groupdict():", m.groupdict()) 99 print("m.start(2):", m.start(2)) 100 print("m.end(2):", m.end(2)) 101 print("m.span(2):", m.span(2)) 102 print(r"m.expand(r'g gg'):", m.expand(r'2 13')) 103 104 ### output ### 105 # m.string: hello world! 106 # m.re: 107 # m.pos: 0 108 # m.endpos: 12 109 # m.lastindex: 3 110 # m.lastgroup: sign 111 # m.group(1,2): ('hello', 'world') 112 # m.groups(): ('hello', 'world', '!') 113 # m.groupdict(): {'sign': '!'} 114 # m.start(2): 6 115 # m.end(2): 11 116 # m.span(2): (6, 11) 117 # m.expand(r'2 13'): world hello! 118 ''' 119 ''' 120 # -*- coding: utf-8 -*- 121 122 #导入re模块 123 import re 124 125 # 将正则表达式编译成Pattern对象,注意hello前面的r的意思是“原生字符串” 126 pattern = re.compile(r'hello') 127 128 # 使用re.match匹配文本,获得匹配结果,无法匹配时将返回None 129 result1 = re.match(pattern,'hello') 130 result2 = re.match(pattern,'helloo 113!') 131 result3 = re.match(pattern,'helo 222!') 132 result4 = re.match(pattern,'hello wer!') 133 134 #如果1匹配成功 135 if result1: 136 # 使用Match获得分组信息 137 print(result1.group()) 138 else: 139 print('1匹配失败!') 140 141 142 #如果2匹配成功 143 if result2: 144 # 使用Match获得分组信息 145 print(result2.group()) 146 else: 147 print('2匹配失败!') 148 149 150 #如果3匹配成功 151 if result3: 152 # 使用Match获得分组信息 153 print(result3.group()) 154 else: 155 print('3匹配失败!') 156 157 #如果4匹配成功 158 if result4: 159 # 使用Match获得分组信息 160 print(result4.group()) 161 else: 162 print('4匹配失败!') 163 '''