从今天开始,开始研究学习Hadoop Common相关的源码结构。Hadoop Common在Hadoop1.0中是在core包下面的。此包下面的内容供HDFS和MapReduce公用,所以作用还是非常大的。Hadoop Common模块下的内容是比较多的。本人打算在后面的学习中挑选部分模块进行分析学习,比如他的序列化框架的实现,RPC的实现等等。我对此模块截出了一些图:
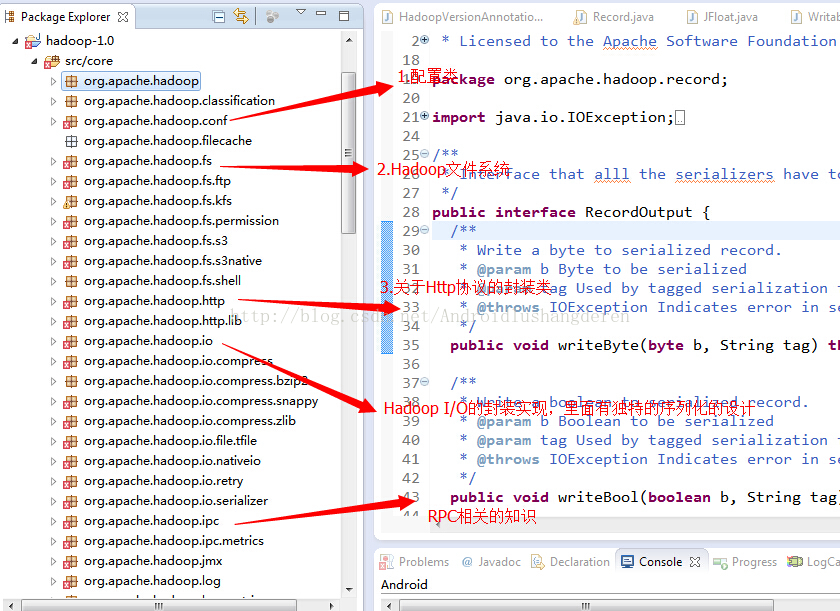
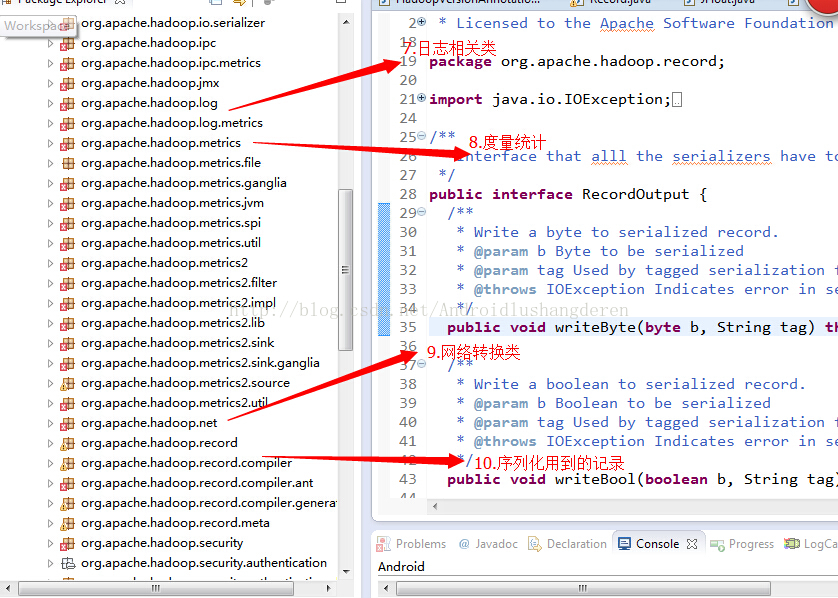

程序包下的主要模块关系图:

下面分模块,做一下简短的概述
1.org.apache.hadoop.conf,配置相关类,配置类在Hadoop中一直都是一个比较基本类,很多配置设置的数据都需要从配置文件中去读取。Hadoop中配置文件还挺多的,HDFS和MapReduce各一个,还会用用户自定义的配置文件。系统开放了许多的get/set方法来获取和设置其中的属性。
2.org.apache.hadoop.fs,Hadoop文件系统,从Hadoop的文件系统中,也许你会看到Linux文件系统的影子,里面包括了很多文件File的各种基本操作,还有很多在文件中特殊的操作实现,比如权限控制,目录,文件通过什么来组织,Hadoop文件系统搞了一个和VFS虚拟文件系统非常像的一个抽象文件系统,基于这个Hadoop抽象文件系统,派生了很多具体拥有各个功能的文件子系统,比如内存文件系统,校验和系统。
3.org.apache.hadoop.io,Hadoop I/O系统,输入输出系统在任何一个系统都是非常重要的设计,同样在Hadoop中,在此上面实现了一个特有的序列化系统,不同于java自带的序列化实现,Hadoop的序列化机制具有快速,紧凑的特点,非常适合于Hadoop的使用场景。还有1个就是Hadoop的在I/O中的解压缩的设计,里面还可以通过JNI的形式调用第三方的比较优秀的压缩算法,比如Google的Snappy框架。
4.org.apache.hadoop.ipc,Hadoop远程过程调用的实现,这个模块的设计是有很多值得学习的好地方,java的RPC最直接的体现就是RMI的实现,RMI的实现就是一个简陋版本的远程过程调用,但是由于JMI的不可定制性,所以Hadoop根据自己系统特点,重新设计了一套独有的RPC体系,在java NIO的基础上,用了java动态代理的思想,RPC的服务端和客户端都是通过代理获得方式取得。
其他包的一些内容我简单的描述,org.apache.hadoop.log,日志帮助类,实现估值的检测和恢复,org.apache.hadoop.metrics,用于度量统计用的,主要用于分析的,至于具体怎么做的,本人也不是特别了解,org.apache.hadoop.http和org.apache.hadoop.net是Hadoop对网络层次相关的封装,最后要提到的就是org.apache.hadoop.util就是在Common中的公共方法类,checkSum校验和的验证方法就包含于此。