前言
一看到贝叶斯网络,马上让人联想到的是5个字,朴素贝叶斯,在所难免,NaiveByes的知名度确实会被贝叶斯网络算法更高一点。其实不管是朴素贝叶斯算法,还是今天我打算讲述的贝叶斯网络算法也罢,归根结底来说都是贝叶斯系列分类算法,他的核心思想就是基于概率学的知识进行分类判断,至于分类得到底准不准,大家尽可以自己用数据集去测试测试。OK,下面进入正题--贝叶斯网络算法。
朴素贝叶斯
一般我在介绍某种算法之前,都事先会学习一下相关的算法,以便于新算法的学习,而与贝叶斯网络算法相关性比较大的在我看来就是朴素贝叶斯算法,而且前段时间也恰好学习过,简单的来说,朴素贝叶斯算法的假设条件是各个事件相互独立,然后利用贝叶斯定理,做概率的计算,于是这个算法的核心就是就是这个贝叶斯定理的运用了喽,不错,贝叶斯定理的确很有用,他是基于条件概率的先验概率和后验概率的转换公式,这么说有点抽象,下面是公式的表达式:
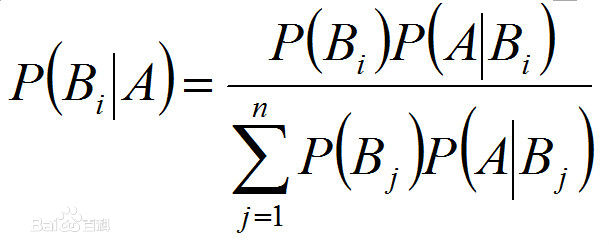
大学里概率学的课本上都有介绍过的,这个公式的好处在于对于一些比较难直接得出的概率通过转换后的概率计算可得,一般是把决策属性值放在先验属性中,当做目标值,然后通过决策属性值的后验概率计算所得。具体请查看我的朴素贝叶斯算法介绍。
贝叶斯网络
下面这个部分就是文章的主题了,贝叶斯网络,里面有2个字非常关键,就是网络,网络代表的潜在意思有2点,第一是有结构的,第二存在关联,我们可以马上联想到DAG有向无环图。不错,存在关联的这个特点就是与朴素贝叶斯算法最大的一个不同点,因为朴素贝叶斯算法在计算概率值上是假设各个事务属性是相互独立的,但是理性的思考一下,其实这个很难做到,任何事务,如果你仔细去想想,其实都还是有点联系的。比如这里有个例子:
在SNS社区中检验账号的真实性
如果用朴素贝叶斯来做的话,就会是这样的假设:
i、真实账号比非真实账号平均具有更大的日志密度、各大的好友密度以及更多的使用真实头像。
ii、日志密度、好友密度和是否使用真实头像在账号真实性给定的条件下是独立的。
但是其实往深入一想,使用真实的头像其实是会提高人家添加你为好友的概率的,所以在这个条件的独立其实是有问题的,所以在贝叶斯网络中是允许关联的存在的,假设就变为如下:
i、真实账号比非真实账号平均具有更大的日志密度、各大的好友密度以及更多的使用真实头像。
ii、日志密度与好友密度、日志密度与是否使用真实头像在账号真实性给定的条件下是独立的。
iii、使用真实头像的用户比使用非真实头像的用户平均有更大的好友密度。
在贝叶斯网络中,会用一张DAG来表示,每个节点代表某个属性事件,每条边代表其中的条件概率,如下:
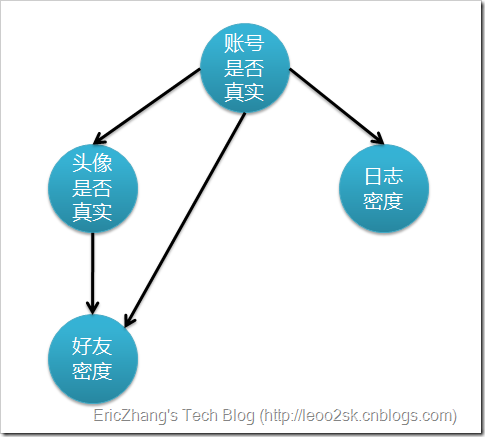
贝叶斯网络概率的计算
贝叶斯网络概率的计算很简单,是从联合概率分布公式中变换所得,下面是联合概率分布公式:
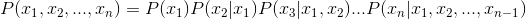
而在贝叶斯网络中,由于存在前述的关系存在,该公式就被简化为了如下:
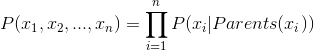
其中Parent(xi),表示的是xi的前驱结点,如果还不理解,可以对照我后面的代码,自行调试分析。
代码实现
需要输入2部分的数据,依赖关系,用于构建贝叶斯网络图,第二个是测试数据集,算法总代码地址:
https://github.com/linyiqun/DataMiningAlgorithm/tree/master/Others/DataMining_BayesNetwork
依赖关系数据如下:
B A
E A
A M
A J测试数据集:
B E A M J P
y y y y y 0.00012
y y y y n 0.000051
y y y n y 0.000013
y y y n n 0.0000057
y y n y y 0.000000005
y y n y n 0.00000049
y y n n y 0.000000095
y y n n n 0.0000094
y n y y y 0.0058
y n y y n 0.0025
y n y n y 0.00065
y n y n n 0.00028
y n n y y 0.00000029
y n n y n 0.000029
y n n n y 0.0000056
y n n n n 0.00055
n y y y y 0.0036
n y y y n 0.0016
n y y n y 0.0004
n y y n n 0.00017
n y n y y 0.000007
n y n y n 0.00069
n y n n y 0.00013
n y n n n 0.013
n n y y y 0.00061
n n y y n 0.00026
n n y n y 0.000068
n n y n n 0.000029
n n n y y 0.00048
n n n y n 0.048
n n n n y 0.0092
n n n n n 0.91节点类Node.java:
package DataMining_BayesNetwork;
import java.util.ArrayList;
/**
* 贝叶斯网络节点类
*
* @author lyq
*
*/
public class Node {
// 节点的属性名称
String name;
// 节点的父亲节点,也就是上游节点,可能多个
ArrayList<Node> parentNodes;
// 节点的子节点,也就是下游节点,可能多个
ArrayList<Node> childNodes;
public Node(String name) {
this.name = name;
// 初始化变量
this.parentNodes = new ArrayList<>();
this.childNodes = new ArrayList<>();
}
/**
* 将自身节点连接到目标给定的节点
*
* @param node
* 下游节点
*/
public void connectNode(Node node) {
// 将下游节点加入自身节点的孩子节点中
this.childNodes.add(node);
// 将自身节点加入到下游节点的父节点中
node.parentNodes.add(this);
}
/**
* 判断与目标节点是否相同,主要比较名称是否相同即可
*
* @param node
* 目标结点
* @return
*/
public boolean isEqual(Node node) {
boolean isEqual;
isEqual = false;
// 节点名称相同则视为相等
if (this.name.equals(node.name)) {
isEqual = true;
}
return isEqual;
}
}
算法类BayesNetworkTool.java:
package DataMining_BayesNetwork;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
/**
* 贝叶斯网络算法工具类
*
* @author lyq
*
*/
public class BayesNetWorkTool {
// 联合概率分布数据文件地址
private String dataFilePath;
// 事件关联数据文件地址
private String attachFilePath;
// 属性列列数
private int columns;
// 概率分布数据
private String[][] totalData;
// 关联数据对
private ArrayList<String[]> attachData;
// 节点存放列表
private ArrayList<Node> nodes;
// 属性名与列数之间的对应关系
private HashMap<String, Integer> attr2Column;
public BayesNetWorkTool(String dataFilePath, String attachFilePath) {
this.dataFilePath = dataFilePath;
this.attachFilePath = attachFilePath;
initDatas();
}
/**
* 初始化关联数据和概率分布数据
*/
private void initDatas() {
String[] columnValues;
String[] array;
ArrayList<String> datas;
ArrayList<String> adatas;
// 从文件中读取数据
datas = readDataFile(dataFilePath);
adatas = readDataFile(attachFilePath);
columnValues = datas.get(0).split(" ");
// 属性割名称代表事件B(盗窃),E(地震),A(警铃响).M(接到M的电话),J同M的意思,
// 属性值都是y,n代表yes发生和no不发生
this.attr2Column = new HashMap<>();
for (int i = 0; i < columnValues.length; i++) {
// 从数据中取出属性名称行,列数值存入图中
this.attr2Column.put(columnValues[i], i);
}
this.columns = columnValues.length;
this.totalData = new String[datas.size()][columns];
for (int i = 0; i < datas.size(); i++) {
this.totalData[i] = datas.get(i).split(" ");
}
this.attachData = new ArrayList<>();
// 解析关联数据对
for (String str : adatas) {
array = str.split(" ");
this.attachData.add(array);
}
// 构造贝叶斯网络结构图
constructDAG();
}
/**
* 从文件中读取数据
*/
private ArrayList<String> readDataFile(String filePath) {
File file = new File(filePath);
ArrayList<String> dataArray = new ArrayList<String>();
try {
BufferedReader in = new BufferedReader(new FileReader(file));
String str;
while ((str = in.readLine()) != null) {
dataArray.add(str);
}
in.close();
} catch (IOException e) {
e.getStackTrace();
}
return dataArray;
}
/**
* 根据关联数据构造贝叶斯网络无环有向图
*/
private void constructDAG() {
// 节点存在标识
boolean srcExist;
boolean desExist;
String name1;
String name2;
Node srcNode;
Node desNode;
this.nodes = new ArrayList<>();
for (String[] array : this.attachData) {
srcExist = false;
desExist = false;
name1 = array[0];
name2 = array[1];
// 新建节点
srcNode = new Node(name1);
desNode = new Node(name2);
for (Node temp : this.nodes) {
// 如果找到相同节点,则取出
if (srcNode.isEqual(temp)) {
srcExist = true;
srcNode = temp;
} else if (desNode.isEqual(temp)) {
desExist = true;
desNode = temp;
}
// 如果2个节点都已找到,则跳出循环
if (srcExist && desExist) {
break;
}
}
// 将2个节点进行连接
srcNode.connectNode(desNode);
// 根据标识判断是否需要加入列表容器中
if (!srcExist) {
this.nodes.add(srcNode);
}
if (!desExist) {
this.nodes.add(desNode);
}
}
}
/**
* 查询条件概率
*
* @param attrValues
* 条件属性值
* @return
*/
private double queryConditionPro(ArrayList<String[]> attrValues) {
// 判断是否满足先验属性值条件
boolean hasPrior;
// 判断是否满足后验属性值条件
boolean hasBack;
int priorIndex;
int attrIndex;
double backPro;
double totalPro;
double pro;
double currentPro;
// 先验属性
String[] priorValue;
String[] tempData;
pro = 0;
totalPro = 0;
backPro = 0;
attrValues.get(0);
priorValue = attrValues.get(0);
// 得到后验概率
attrValues.remove(0);
// 取出先验属性的列数
priorIndex = this.attr2Column.get(priorValue[0]);
// 跳过第一行的属性名称行
for (int i = 1; i < this.totalData.length; i++) {
tempData = this.totalData[i];
hasPrior = false;
hasBack = true;
// 当前行的概率
currentPro = Double.parseDouble(tempData[this.columns - 1]);
// 判断是否满足先验条件
if (tempData[priorIndex].equals(priorValue[1])) {
hasPrior = true;
}
for (String[] array : attrValues) {
attrIndex = this.attr2Column.get(array[0]);
// 判断值是否满足条件
if (!tempData[attrIndex].equals(array[1])) {
hasBack = false;
break;
}
}
// 进行计数统计,分别计算满足后验属性的值和同时满足条件的个数
if (hasBack) {
backPro += currentPro;
if (hasPrior) {
totalPro += currentPro;
}
} else if (hasPrior && attrValues.size() == 0) {
// 如果只有先验概率则为纯概率的计算
totalPro += currentPro;
backPro = 1.0;
}
}
// 计算总的概率=都发生概率/只发生后验条件的时间概率
pro = totalPro / backPro;
return pro;
}
/**
* 根据贝叶斯网络计算概率
*
* @param queryStr
* 查询条件串
* @return
*/
public double calProByNetWork(String queryStr) {
double temp;
double pro;
String[] array;
// 先验条件值
String[] preValue;
// 后验条件值
String[] backValue;
// 所有先验条件和后验条件值的属性值的汇总
ArrayList<String[]> attrValues;
// 判断是否满足网络结构
if (!satisfiedNewWork(queryStr)) {
return -1;
}
pro = 1;
// 首先做查询条件的分解
array = queryStr.split(",");
// 概率的初值等于第一个事件发生的随机概率
attrValues = new ArrayList<>();
attrValues.add(array[0].split("="));
pro = queryConditionPro(attrValues);
for (int i = 0; i < array.length - 1; i++) {
attrValues.clear();
// 下标小的在前面的属于后验属性
backValue = array[i].split("=");
preValue = array[i + 1].split("=");
attrValues.add(preValue);
attrValues.add(backValue);
// 算出此种情况的概率值
temp = queryConditionPro(attrValues);
// 进行积的相乘
pro *= temp;
}
return pro;
}
/**
* 验证事件的查询因果关系是否满足贝叶斯网络
*
* @param queryStr
* 查询字符串
* @return
*/
private boolean satisfiedNewWork(String queryStr) {
String attrName;
String[] array;
boolean isExist;
boolean isSatisfied;
// 当前节点
Node currentNode;
// 候选节点列表
ArrayList<Node> nodeList;
isSatisfied = true;
currentNode = null;
// 做查询字符串的分解
array = queryStr.split(",");
nodeList = this.nodes;
for (String s : array) {
// 开始时默认属性对应的节点不存在
isExist = false;
// 得到属性事件名
attrName = s.split("=")[0];
for (Node n : nodeList) {
if (n.name.equals(attrName)) {
isExist = true;
currentNode = n;
// 下一轮的候选节点为当前节点的孩子节点
nodeList = currentNode.childNodes;
break;
}
}
// 如果存在未找到的节点,则说明不满足依赖结构跳出循环
if (!isExist) {
isSatisfied = false;
break;
}
}
return isSatisfied;
}
}
package DataMining_BayesNetwork;
import java.text.MessageFormat;
/**
* 贝叶斯网络场景测试类
*
* @author lyq
*
*/
public class Client {
public static void main(String[] args) {
String dataFilePath = "C:\Users\lyq\Desktop\icon\input.txt";
String attachFilePath = "C:\Users\lyq\Desktop\icon\attach.txt";
// 查询串语句
String queryStr;
// 结果概率
double result;
// 查询语句的描述的事件是地震发生了,导致响铃响了,导致接到Mary的电话
queryStr = "E=y,A=y,M=y";
BayesNetWorkTool tool = new BayesNetWorkTool(dataFilePath,
attachFilePath);
result = tool.calProByNetWork(queryStr);
if (result == -1) {
System.out.println("所描述的事件不满足贝叶斯网络的结构,无法求其概率");
} else {
System.out.println(String.format("事件%s发生的概率为%s", queryStr, result));
}
}
}
事件E=y,A=y,M=y发生的概率为0.005373075715453122
参考文献
百度百科
http://www.cnblogs.com/leoo2sk/archive/2010/09/18/bayes-network.html
更多数据挖掘算法