前言
做过hadoop集群问题排查工作的同学一定用过JobHistory,这是一个很好用的"利器",为什么这么说呢?正如这个工具的名称所叫的那样,这个工具能帮你找到历史Job跑过的信息,而信息的记录非常的详细,从Job到Task再到TaskAttempt.假如这时候,1个Job突然执行失败了,你想查明原因,在JobHistory的web界面上依次点击详情链接,基本上都可以找到原因.但是看似非常完美的Job分析工具,也有许多使用起来不是很方便的地方,于是乎,我们想对此进行一些改进,使其更加易用,同时相信能给同样在使用jobHistory的人提供帮助.
现有JobHistory的不足之处
从开始使用这个分析工具到现在,1个让我一直用着特别不爽的地方是,很难迅速查到历史时间稍稍远一些的Job信息,因为有的时候我要做同时段的Job运行情况对比,包括运行时长,Task失败次数等等指标.所以你需要把昨天,前天的数据拉出来.然后很多人的正常反应就是把Jobhistory页面上默认显示的Job条数加大,以此显示更长时间的Job.这个方法既简单又方便,通过更改下面这个配置项,并重启JobHistory就可以立马做到:
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>20000</value>
<description>Size of the job list cache</description>
</property>这个默认值是显示2w条,大家千万不要以为这个值很大,当你的集群1天能跑上万个job的时候,这个值显然是偏小的,你只能显示到近2,3天的数据,如果突然我想看上周的数据,发现没法看了,这简直就是恶梦.当时我们也遇到了这种情况,然后我们把这个配置项调大到10w,这样就可以保留近一段时间的数据了.但是另外一个问题暴露出来了,页面加载太慢,JobHistory的主页面在1分钟之内是别想显示出来了,大家如果读过jobHistory页面的渲染代码,你可以看到,他的页面是直接全部渲染好之后显示的,并没有说所谓的每页只加载一部分,你要加载10w
条记录,我立即返回10w条记录,构成超级大的html页面,返回到浏览器上,所以我们后来发现很多的时间开销都花在下载页面的时间上,而非后端返回Job列表信息的时间上.但是没有办法,为了能看到更多的历史数据,只能牺牲一下用户体验了.相信博友们当中肯定有一部分人也遇到了这样的问题.描述了这么多,其实我们最终想要达到的1个目标就是,我既想不用显示那么多的Job数据,保留最近1天的即可,使得页面能迅速打开,其次我又能够查到历史数据.显然,这在原本的jobHistory中是无法兼顾的,所以我们可以改造一下他,使得这个工具能够更加"智能化"一些.
JobHistory使用现状
下面来看看,目前一般hadoop开发者是如何使用jobHistory,一般都会用到下面这个按钮:
这个一个非常广的搜索按钮,Job页面信息加载完成之后,你可以输入你想要的目标Job名称,过滤结果马上就会出现,当你把查询字符串进行清除,Job列表记录又会恢复到原样.很显然,这是1个非常简单直接化的搜索功能.我就这么多的信息,有就显示,没有就不显示.所以要想达到上小节中提到的优化目标,我们必须在搜索功能上进行优化改造.当然,我们会保留目前的搜索按钮,保持其不变.
JobHistory搜索优化目标
从上文中我们知道要做到JobHistory"智能化",需要在搜索功能方面进行改造.那么具体什么样的搜索场景是我们比较容易碰到的呢?
第一个,根据Job名称,我们知道失败的Job名称,然后,进行查询.
第二个,根据Jobid,我们从日志中或其他途径得到失败的Job,直接进行Job搜索,跳转至详情页.
而且还有最关键的1个前提,上述搜索功能的实现是不依赖前端页面显示的Job信息列表,比如我Job显示数量配成10条,我依然可以查到1周前某某失败Job的信息.下面是几个要点:
1.这里就需要做到jobHistory前后端cache-job数的配置分离,目前用的都是同一个配置,所以会导致上述这样的问题.
2.完成第二个需求点比第一个容易,因为第二个有jobid,直接进行链接的拼装,直接进行一个重定向就可以解决,所有的Job详情页信息链接都是一个模板,不用实现得过于复杂.
3.第一个需求需要后端通过传进来的Job名称做一些过滤处理,然后再返给前端展示,过滤掉绝大多数无用的Job信息.像类似于这样的需求,如果在普通的业务系统开发中,一定是再简单不过了,那么在hadoop中要如何改造呢,人家的这一套逻辑实现可没这么简单直接.
JobHistory具体代码改造
前面讲述完目标和方法之后,最后需要真正的从代码层面去实现了,所以需要了解一下目前JobHistory主页面是如何得到的,数据哪里来,页面前端代码哪里写的,是直接有现成的.html文件?光凭空猜想是没有用的,只有深入源代码的研究分析才能有答案.其实页面的代码实现在HsJobsBlock.java这个类中.页面渲染的逻辑实现就是在render方法中实现的
/*
* (non-Javadoc)
* @see org.apache.hadoop.yarn.webapp.view.HtmlBlock#render(org.apache.hadoop.yarn.webapp.view.HtmlBlock.Block)
*/
@Override protected void render(Block html) {
TBODY<TABLE<Hamlet>> tbody = html.
h2("Retired Jobs").
table("#jobs").
thead().
tr().
th("Submit Time").
th("Start Time").
th("Finish Time").
th(".id", "Job ID").
th(".name", "Name").
th("User").
th("Queue").
th(".state", "State").
th("Maps Total").
th("Maps Completed").
th("Reduces Total").
th("Reduces Completed").
th("Elapsed Time")._()._().
tbody();
LOG.info("Getting list of all Jobs.");
// Write all the data into a JavaScript array of arrays for JQuery
// DataTables to display
StringBuilder jobsTableData = new StringBuilder("[
");
for (Job j : appContext.getAllJobs().values()) {
JobInfo job = new JobInfo(j);
jobsTableData.append("["")
.append(dateFormat.format(new Date(job.getSubmitTime()))).append("","")
.append(dateFormat.format(new Date(job.getStartTime()))).append("","")
.append(dateFormat.format(new Date(job.getFinishTime()))).append("","")
.append("<a href='").append(url("job", job.getId())).append("'>")
.append(job.getId()).append("</a>","")
.append(StringEscapeUtils.escapeJavaScript(StringEscapeUtils.escapeHtml(
job.getName()))).append("","")
.append(StringEscapeUtils.escapeJavaScript(StringEscapeUtils.escapeHtml(
job.getUserName()))).append("","")
.append(StringEscapeUtils.escapeJavaScript(StringEscapeUtils.escapeHtml(
job.getQueueName()))).append("","")
.append(job.getState()).append("","")
.append(String.valueOf(job.getMapsTotal())).append("","")
.append(String.valueOf(job.getMapsCompleted())).append("","")
.append(String.valueOf(job.getReducesTotal())).append("","")
.append(String.valueOf(job.getReducesCompleted())).append("","")
.append(
StringUtils.formatTimeSortable(Times.elapsed(job.getStartTime(),
job.getFinishTime(), false))).append(""],
");
}
很显然,方法在JobHistory这个类中.会调用到下面的方法:
@Override
public Map<JobId, Job> getAllJobs() {
return storage.getAllPartialJobs();
}@Override
public Map<JobId, Job> getAllPartialJobs() {
LOG.debug("Called getAllPartialJobs()");
SortedMap<JobId, Job> result = new TreeMap<JobId, Job>();
try {
for (HistoryFileInfo mi : hsManager.getAllFileInfo()) {
if (mi != null) {
JobId id = mi.getJobId();
result.put(id, new PartialJob(mi.getJobIndexInfo(), id));
}
}
} catch (IOException e) {
LOG.warn("Error trying to scan for all FileInfos", e);
throw new YarnRuntimeException(e);
}
return result;
}public Collection<HistoryFileInfo> getAllFileInfo() throws IOException {
scanIntermediateDirectory();
return jobListCache.values();
} protected JobListCache createJobListCache() {
return new JobListCache(conf.getInt(
JHAdminConfig.MR_HISTORY_JOBLIST_CACHE_SIZE,
JHAdminConfig.DEFAULT_MR_HISTORY_JOBLIST_CACHE_SIZE), maxHistoryAge);
}Map<JobId, Job> getDisplayedJobs(String filterName); /**
* Get partial displayed of the cached jobs.
* @param filterName the filter job name
* @return all of the cached jobs
*/
Map<JobId, Job> getPartialDisplayedJobs(String filterName);<property>
<name>mapreduce.jobhistory.joblist.cache-displayed.size</name>
<value>1000</value>
<description>The size of job-list cache displayed in the jobHistory web ui.
</description>
</property> @SuppressWarnings("serial")
private void createLoadedJobCache(Configuration conf) {
...
cacheDisplayedSize =
conf.getInt(JHAdminConfig.MR_HISTORY_JOBLIST_CACHE_DISPLAYED_SIZE,
JHAdminConfig.DEFAULT_MR_HISTORY_JOBLIST_CACHE_DISPLAYED_SIZE);
...
}@Override
public Map<JobId, Job> getPartialDisplayedJobs(String filterName) {
LOG.debug("Called getPartialDisplayedJobs()");
String jobName;
int cacheJobSize = 0;
SortedMap<JobId, Job> result = new TreeMap<JobId, Job>();
try {
for (HistoryFileInfo mi : hsManager.getAllFileInfo()) {
if (mi != null) {
cacheJobSize++;
if (cacheJobSize > cacheDisplayedSize) {
LOG.info("GetPartialDisplayedJobs operation ends"
+ ", AllFileInfo size is more than cacheDisplayedSize: "
+ cacheDisplayedSize);
break;
}
JobId id = mi.getJobId();
jobName = mi.getJobIndexInfo().getJobName();
if (filterName == null || filterName.length() == 0) {
result.put(id, new PartialJob(mi.getJobIndexInfo(), id));
} else if (jobName != null && jobName.length() > 0) {
if (jobName.contains(filterName)) {
result.put(id, new PartialJob(mi.getJobIndexInfo(), id));
}
}
}
}
} catch (IOException e) {
LOG.warn("Error trying to scan for all FileInfos", e);
throw new YarnRuntimeException(e);
}
return result;
}新增参数:
/**
* Params constants for the AM webapp and the history webapp.
*/
public interface AMParams {
....
static final String JOBFILTER_NAME = "jobfilter.name";
}route(pajoin("/app", JOBFILTER_NAME), HsController.class);li().a(url("app", ""), "Jobs")._()._();/*
* (non-Javadoc)
* @see org.apache.hadoop.yarn.webapp.view.HtmlBlock#render(org.apache.hadoop.yarn.webapp.view.HtmlBlock.Block)
*/
@Override protected void render(Block html) {
...
String filterName = $(JOBFILTER_NAME);
for (Job j : appContext.getDisplayedJobs(filterName).values()) {
JobInfo job = new JobInfo(j);
jobsTableData.append("["")
.append(dateFormat.format(new Date(job.getSubmitTime()))).append("","")
.append(dateFormat.format(new Date(job.getStartTime()))).append("","")
.append(dateFormat.format(new Date(job.getFinishTime()))).append("","")
.append("<a href='").append(url("job", job.getId())).append("'>")
.append(job.getId()).append("</a>","")
.append(StringEscapeUtils.escapeJavaScript(StringEscapeUtils.escapeHtml(
job.getName()))).append("","")
...String jobIdSearchClickMethod =
"function jobsearch() {
"+
" var jobid = $('.jobid').val()
"+
" window.location ='/jobhistory/job/' + jobid
"+
"}
";@Override protected void render(Block html) {
TBODY<TABLE<Hamlet>> tbody = html.
h2("Retired Jobs").
table("#jobs").
thead().
tr().
th()
.$class("ui-state-default").input("jobid").$type(InputType.text)
.$name("jobid").$value("input jobid")._()._().
th()
.input("search_confirm").$type(InputType.button).$name("search")
.$value("Job Search").$onclick("jobsearch()")._()._()._().
tr().
th()
.$class("ui-state-default").input("jobname").$type(InputType.text)
.$name("jobname").$value("input filetername")._()._().
th()
.input("search_confirm").$type(InputType.button).$name("search")
.$value("Name Search").$onclick("jobnamesearch()")._()._()._().
tr().
........
String jobIdSearchClickMethod =
"function jobsearch() {
"+
" var jobid = $('.jobid').val()
"+
" window.location ='/jobhistory/job/' + jobid
"+
"}
";
String jobNameSearchClickMethod =
"function jobnamesearch() {
"+
" var filtername = $('.jobname').val()
"+
" window.location ='/jobhistory/app/' + filtername
"+
"}
";
html.script().$type("text/javascript").
_("var jobsTableData=" + jobsTableData + "
" + jobIdSearchClickMethod
+ jobNameSearchClickMethod)._();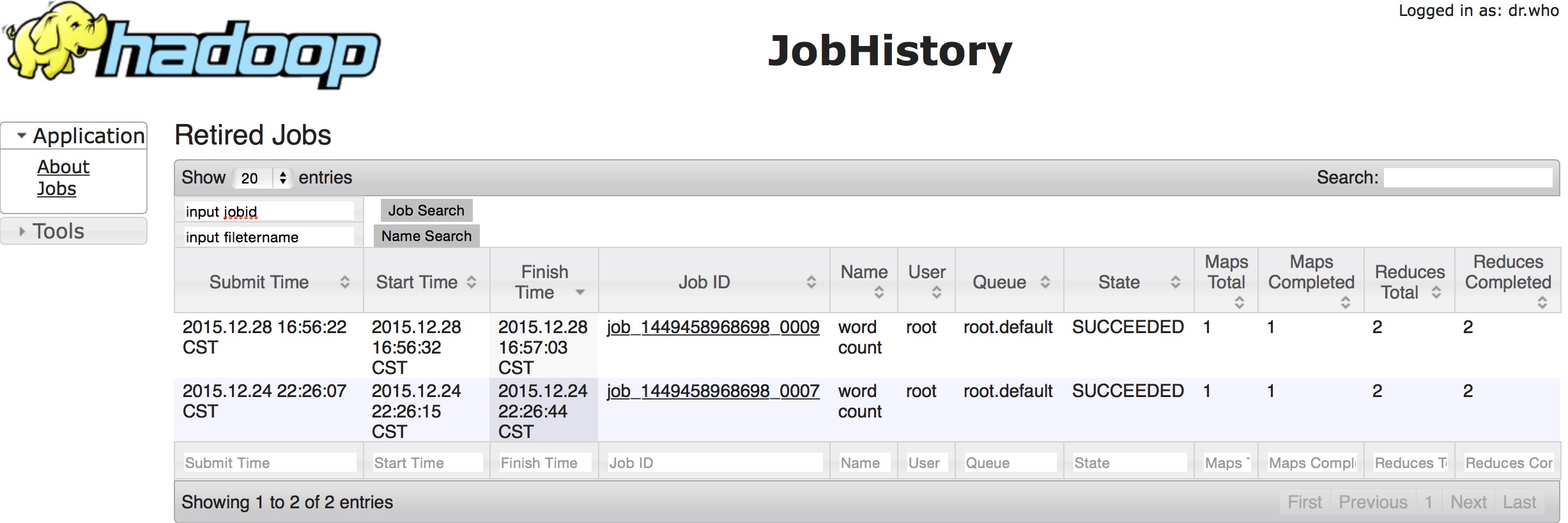
搜索功能测试
第一.指定jobid搜索测试

搜索确定后进入相应详情页:
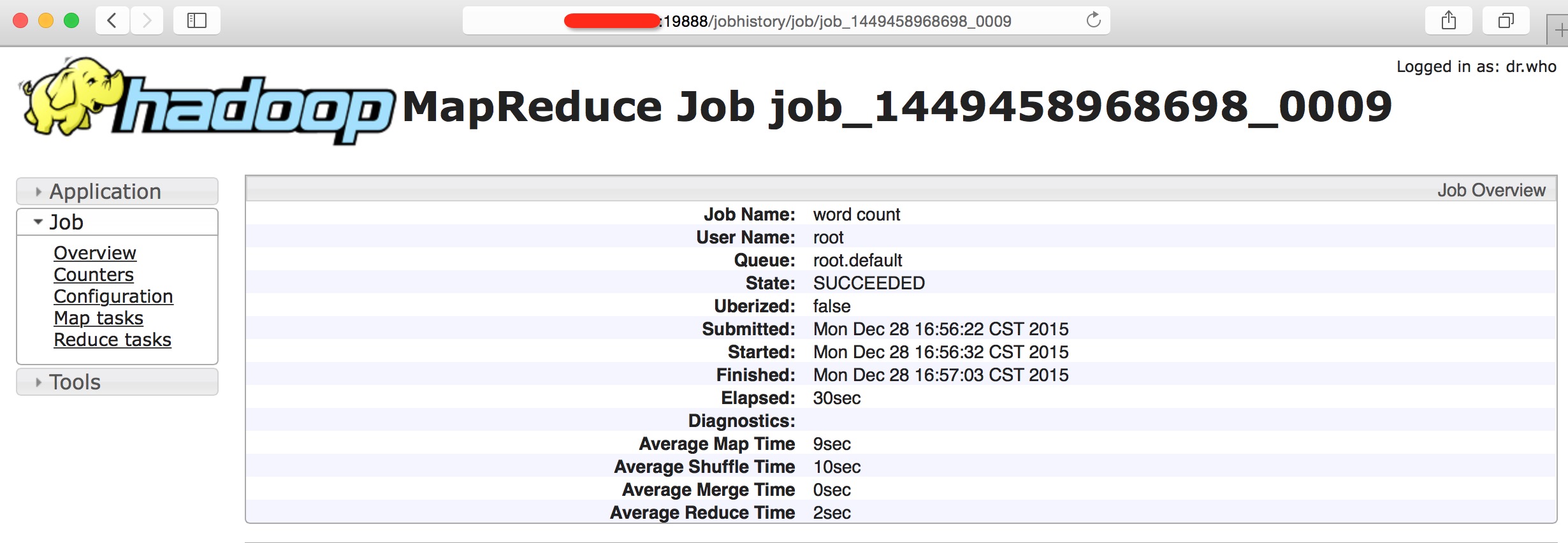
这个链接就是我们用js代码拼装出来的.
第二.指定Job名称搜索
比如我这里已经运行了几个word count测试job.首先随意输入1个无关过滤条件hello(见浏览器链接):
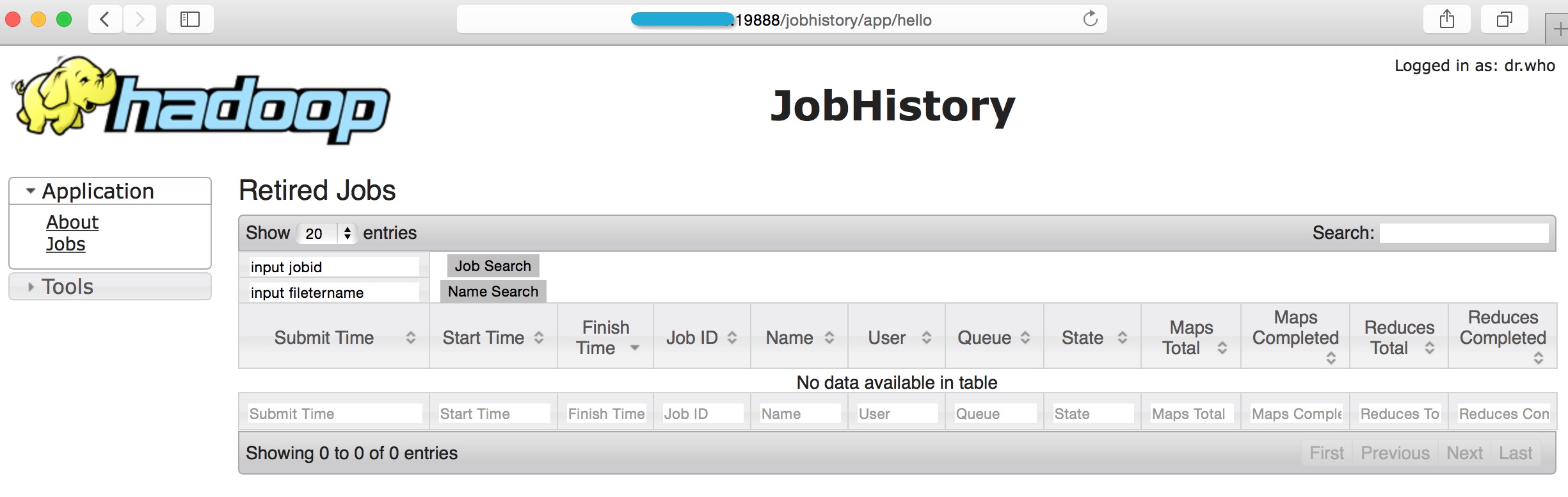
得不到结果,正确.
然后输入word进行匹配:
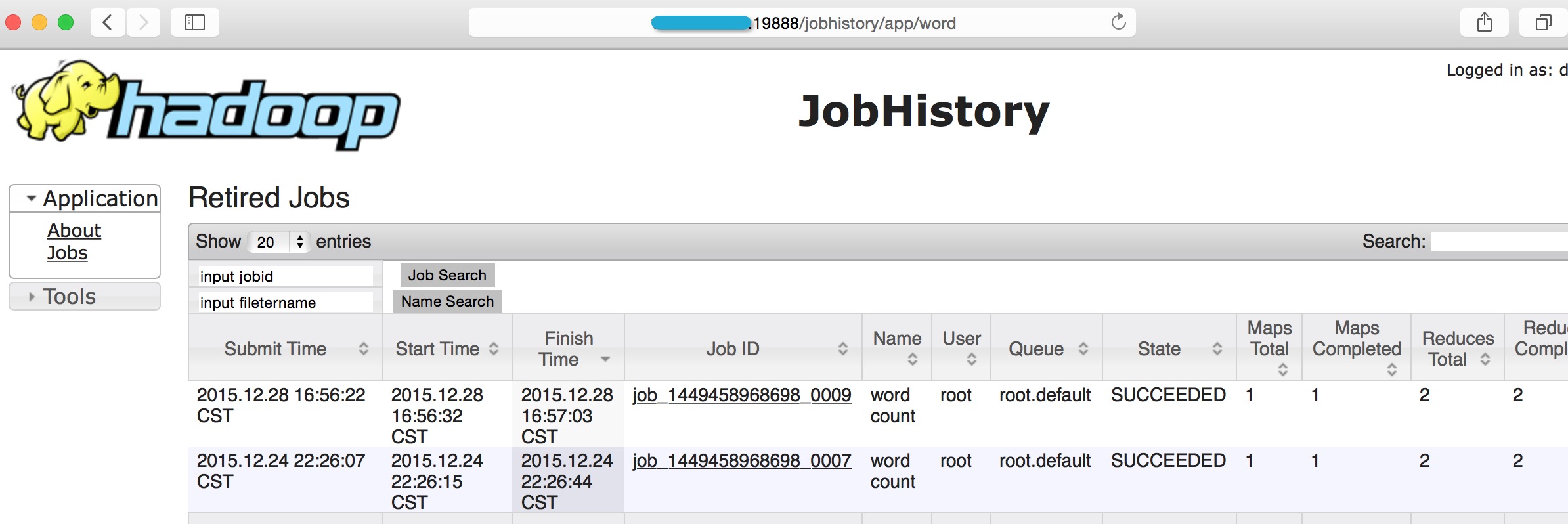
得到2项记录,满足我们的要求.
前端页面Job个数的数量控制功能,我也测试过了,能够通过,在这里就不截图显示了,大家感兴趣的可以自行把这部分的代码改到自己的hadoop代码中,patch代码链接在下方显示.
相关链接
Github patch链接:https://github.com/linyiqun/open-source-patch/tree/master/mapreduce/MAPREDUCE-hsSearch