前言
在当今每日信息量巨大的社会中,源源不断的数据需要被安全的存储.等到数据的规模越来越大的时候,也许瓶颈就来了,没有存储空间了.这时候怎么办,你也许会说,加机器解决,显然这是一个很简单直接但是又显得有些欠缺思考的办法.无谓的加机器只会带来无限上升的成本消耗,更好的办法应该是做到更加精细化的数据存储与管理,比如说非常典型的冷热数据的存储.对于巨大的长期无用的冷数据而言,应该用性能偏弱,但是磁盘空间富余的机器存,热数据则反之.数据的分类存储一定会带来数据的同步问题,假若我有2套集群,1个是线上的正在使用的集群,另外1个则是冷数据集群,我如何做定期的数据同步并且同时对业务方的使用影响完全透明呢?本文就给大家阐述一下本人的一个解决方案,供大家参考.
数据迁移使用场景
上小节中说到的冷热数据的同步只是数据迁移的一个表现场景,那么数据迁移还有其他哪些使用场景呢,如下:
- 冷热集群数据分类存储,详见上述描述.
- 集群数据整体搬迁.当公司的业务迅速的发展,导致当前的服务器数量资源出现临时紧张的时候,为了更高效的利用资源,会将原A机房数据整体迁移到B机房的,原因可能是B机房机器多,而且B机房本身开销较A机房成本低些等.
- 数据的准实时同步.数据的准实时同步与上一点的不同在于第二点可以一次性操作解决,而准实时同步需要定期同步,而且要做到周期内数据基本完全一致.数据准实时同步的目的在于数据的双备份可用,比如某天A集群突然宣告不允许再使用了,此时可以将线上使用集群直接切向B的同步集群,因为B集群实时同步A集群数据,拥有完全一致的真实数据和元数据信息,所以对于业务方使用而言是不会受到任何影响的.
上述3个使用场景中,其中第一点相比较于第二,三点来说可能稍微容易一些,但是想要完全做好也不简单.第三点数据的实时同步想比较第二点来说更加实际一些.因为如果公司要准备集群数据迁移了,一般都会提前通知,然后做逐步迁移,而且也肯定不会让原集群停止服务,所以采用数据慢慢同步的方式,等到数据彻底同步完了,才最终实现切换,达到最终的迁移目标.
数据迁移要素考量
当要做大规模的数据迁移的时候,需要做很多的前期准备工作,而且需要对很多因素,指标进行考量.以下是几个主要指标:
1.Bandwidth-带宽
在做大规模数据量的同步过程中,如何控制同步数据过程中所占用的网络带宽就显得非常的重要.带宽用的多了,会影响到线上业务的任务运行,带宽用的少了又会导致数据同步过慢的问题.所以这里会引发出另外一个问题,对于带宽的限流.也就是说,我要保证我的数据同步程序能保证限定在指定的网络传输速率下,如果你不做任何处理的话,那结果基本上就是网络有多少带宽我就用多少带宽的局面.
2.Performance-性能
性能问题同样也是一个很关键的问题,是采用简单的单机程序?还是多线程的性能更佳的分布式程序?显然后者是我们更想要的.
3.Data-Increment-增量同步
当TB,PB级别的数据需要同步的时候,如果每次以全量的方式去同步数据,结果一定是非常糟糕.增量方式的同步会是不错的选择,那么哪些情况下会导致数据发生增量变动呢
- 原始数据文件进行了Append追加写
- 原始数据文件被delete删除或rename重命名
可能会有人好奇这里为什么没有对原始数据进行改动的情况,这种case也会造成数据的变动啊,因为一般在海量数据存储系统中,例如HDFS,一般不会在原文件内容上做修改,要么继续追加写,要么删除文件,不会有类似RandomAccessFile的随机写的功能,所以做增量数据同步,只要考虑上述2个条件即可.上述条件中的第二点是非常容易判断出的,通过定期的快照文件或元信息文件一比就出来了,但是对于文件是否被进行了追加写或是其他的外界主动的修改操作的时候,我们如何进行判断呢,下面给出2个步骤:
- 第一步: 先比较文件大小,如果2个阶段文件大小发生改变,截取对应原始长度部分进行checksum比较,如果此checksum不变,则此文件必定发生过改变.
- 第二步: 如果文件大小一致,则计算相应的checksum,然后比较2者的checksum.
这种方式算得上是最保险的.
4.Syncable-数据迁移的同步性
数据迁移的过程中需要保证周期内数据是一定能够同步完的,不能差距太大.比如A集群7天内的增量数据,我只要花半天就可以完全同步到B集群,然后我又可以等到下周再次进行同步.最可怕的事情在于A集群的7天内的数据,我的程序花了7天还同步不完,然后下一个周期又来了,这样就无法做到准实时的一致性.其实7天还是一个比较大的时间,最好是能达到按天同步.
HDFS数据迁移解决方案: DistCp的使用
上面分析了很多数据迁移中的很多使用场景和可能出现的问题.但是从这里开始,是一个分水岭了,下部分的文章主要阐述HDFS中的数据迁移解决方案,面对上文中提到的诸多问题,HDFS中到底应该如何解决.如果你不是HDFS,Hadoop的专家,可能问题看起来有点棘手,但是没有关系,Hadoop内部专门开发了相应的工具,DistCp.在DistCp工具在HDFS中的定位就是来干这件事情的,从source filesystem到target filesystem的数据拷贝.DistCp在hadoop-tools工程下,作为独立子工程存在.在官方注释中,对于DistCp的解释如下:
DistCp is the main driver-class for DistCpV2.
For command-line use, DistCp::main() orchestrates the parsing of command-line
parameters and the launch of the DistCp job.
For programmatic use, a DistCp object can be constructed by specifying
options (in a DistCpOptions object), and DistCp::execute() may be used to
launch the copy-job. DistCp may alternatively be sub-classed to fine-tune
behaviour. 大意是通过命令行附带参数的形式,构造出DistCp的job,然后执行此Job.所以从这里可以知道,拷贝任务本身是一个MR的Job,已经把Hadoop本身的分布式执行的特性用上了.
DistCp优势特性
鉴于DistCp的特殊使用场景,程序设计者在此工具代码中添加了很多的独到的设计.下面针对上文提到的一些要素进行相应的阐述:
1.带宽限流
DistCp是支持带宽限流的,使用者可以通过命令参数bandwidth来为程序进行限流,原理类似于HDFS中数据Balance程序的限流.但是个人感觉做的比Balance稍微简化了一些.DistCp中相关类是ThrottledInputStream,在每次读操作的时候,做一些限流判断:
/** {@inheritDoc} */
@Override
public int read() throws IOException {
throttle();
int data = rawStream.read();
if (data != -1) {
bytesRead++;
}
return data;
}然后在throttle的方法中进行当前传输速率的判断,如果过快会进行一段时间的睡眠来降低总平均速率
private void throttle() throws IOException {
while (getBytesPerSec() > maxBytesPerSec) {
try {
Thread.sleep(SLEEP_DURATION_MS);
totalSleepTime += SLEEP_DURATION_MS;
} catch (InterruptedException e) {
throw new IOException("Thread aborted", e);
}
}
}相关的带宽限流,可以看我的另外一篇文章Hadoop内部的限流机制.
2.增量数据同步
对于增量数据同步的需求,在DistCp中也得到了很好的实现.通过update,append和*diff*2个参数能很好的解决.官方的参数使用说明:
- Update: Update target, copying only missing files or directories
- Append: Reuse existing data in target files and append new data to them if possible.
- Diff: Use snapshot diff report to identify the difference between source and target.
第一个参数,解决了新增文件目录的同步,第二参数,解决已存在文件的增量更新同步,第三个参数解决删除或重命名文件的同步.这里需要额外解释一下diff的使用需要设置2个不同时间的snapshot进行对比,产生相应的DiffInfo.在获取快照文件的变化时,只会选择出DELETE和RENAME这2种类型的变化信息.
static DiffInfo[] getDiffs(SnapshotDiffReport report, Path targetDir) {
List<DiffInfo> diffs = new ArrayList<>();
for (SnapshotDiffReport.DiffReportEntry entry : report.getDiffList()) {
// 只判断删除和重命名的类型
if (entry.getType() == SnapshotDiffReport.DiffType.DELETE) {
final Path source = new Path(targetDir,
DFSUtil.bytes2String(entry.getSourcePath()));
diffs.add(new DiffInfo(source, null));
} else if (entry.getType() == SnapshotDiffReport.DiffType.RENAME) {
final Path source = new Path(targetDir,
DFSUtil.bytes2String(entry.getSourcePath()));
final Path target = new Path(targetDir,
DFSUtil.bytes2String(entry.getTargetPath()));
diffs.add(new DiffInfo(source, target));
}
}
return diffs.toArray(new DiffInfo[diffs.size()]);
}在文件数据追加写的判断逻辑上,DistCp中还是做了很精细的判断的.首先是判断是否可以跳过文件当大小不变的情况
private boolean canSkip(FileSystem sourceFS, FileStatus source,
FileStatus target) throws IOException {
if (!syncFolders) {
return true;
}
boolean sameLength = target.getLen() == source.getLen();
boolean sameBlockSize = source.getBlockSize() == target.getBlockSize()
|| !preserve.contains(FileAttribute.BLOCKSIZE);
// 如果是同大小并且blockSize的大小也一样,则继续进行checksum的判断
if (sameLength && sameBlockSize) {
return skipCrc ||
DistCpUtils.checksumsAreEqual(sourceFS, source.getPath(), null,
targetFS, target.getPath());
} else {
return false;
}
}其次是判断是否可以进行追加写
...
// 判断是否可以跳过此文件
if (canSkip(sourceFS, source, targetFileStatus)) {
return FileAction.SKIP;
} else if (append) {
// 如果是设置了追加写的方式,首先获取原目标文件的大小
long targetLen = targetFileStatus.getLen();
// 如果原目标文件大小小于现在的源文件大小,说明源文件进行了新的写操作
if (targetLen < source.getLen()) {
// 计算源文件对应目标文件大小的文件checksum
FileChecksum sourceChecksum = sourceFS.getFileChecksum(
source.getPath(), targetLen);
// 如果源文件对应长度的数据的checksum与目标文件checksum完全一致,
// 表明源文件多出的数据完全是新写入的,前面的数据没有变动,支持追加写
if (sourceChecksum != null
&& sourceChecksum.equals(targetFS.getFileChecksum(target))) {
// We require that the checksum is not null. Thus currently only
// DistributedFileSystem is supported
return FileAction.APPEND;
}
// 如果checksum发生了变化,说明源文件前面部分的数据发生了变动,则将会进行
// OVERWRITE覆盖的动作
}
}
}
return FileAction.OVERWRITE;
...并没有直接根据大小的变化作为根本依据,大小发生变化了,还要再对之前的对应长度的数据做checksum的验证.
3.高效的性能
第三点关于DistCp的性能问题我想主要分析一下.因为前2点的特性通过普通的程序优化优化也能够实现,但是在第三点的性能特性上,我想DistCp一定具有他独到的优势的.
(1).执行的分布式特性
之前在上文中已经提到过,DistCp本身会构造成一个MR的Job.他是一个纯由Map Task构成的Job,注意是没有Reduce过程的.所以他能够把集群资源利用起来,集群闲下来的资源越多,他跑的越快.下面是Job的构造过程:
/**
* Create Job object for submitting it, with all the configuration
*
* @return Reference to job object.
* @throws IOException - Exception if any
*/
private Job createJob() throws IOException {
String jobName = "distcp";
String userChosenName = getConf().get(JobContext.JOB_NAME);
if (userChosenName != null)
jobName += ": " + userChosenName;
Job job = Job.getInstance(getConf());
job.setJobName(jobName);
job.setInputFormatClass(DistCpUtils.getStrategy(getConf(), inputOptions));
job.setJarByClass(CopyMapper.class);
configureOutputFormat(job);
// 设置特殊定制的CopyMapper的map类型
job.setMapperClass(CopyMapper.class);
// 无Reduce Task
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputFormatClass(CopyOutputFormat.class);
job.getConfiguration().set(JobContext.MAP_SPECULATIVE, "false");
job.getConfiguration().set(JobContext.NUM_MAPS,
String.valueOf(inputOptions.getMaxMaps()));
if (inputOptions.getSslConfigurationFile() != null) {
setupSSLConfig(job);
}
inputOptions.appendToConf(job.getConfiguration());
return job;
}(2).高效的MR组件
高效的MR组件的意思DistCp在相应的Job时,提供了针对此类型任务的Map Class,InputFormat和OutputFormat,分别是CopyMapper, DynamicInputFormat, CopyOutputFormat.这三者MR设置类型与普通的MR类型有什么区别呢,答案在下面:
DynamicInputFormat implements the "Worker pattern" for DistCp.
Rather than to split up the copy-list into a set of static splits, the DynamicInputFormat does the following:
1. Splits the copy-list into small chunks on the DFS.
2. Creates a set of empty "dynamic" splits, that each consume as many chunks as it can.
This arrangement ensures that a single slow mapper won't slow down the entire job (since the slack will be picked up by other mappers, who consume more chunks.)
By varying the split-ratio, one can vary chunk sizes to achieve different performance characteristics. 以上注释强调了2点,DynamicInputFormat类会将input-file输入文件分成很多的小的chunk,然后由这些chunk构成动态的”dynamic”的splits,然后尽可能的让map task消费掉,而不是传统的将输入文件分割成固定的spilts.而且前者不会造成任何慢的map拖累整个Job的运行.保证了哪个map消费的块,那就消费更多spilt的原则.其中具体的原理读者可自行到org.apache.hadoop.tools.mapred.lib包下的代码中进行分析.下面是本人做的一张DistCp Job结构图:
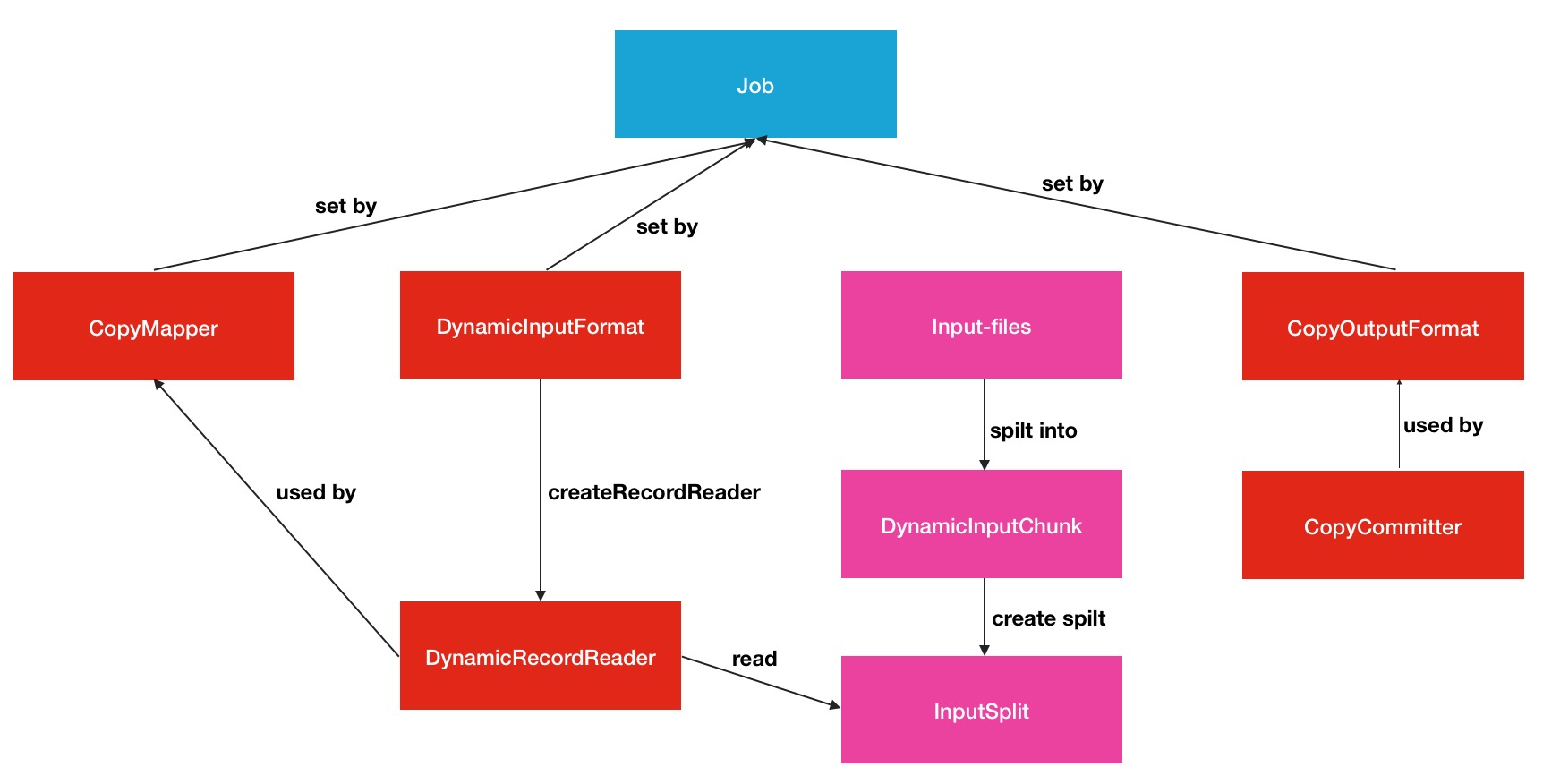
Hadoop DistCp命令的使用
前面花了大量的篇幅阐述了DistCp工具的强大用处,最后给出使用帮助信息,输入hadoop distcp命令即可获取帮助信息:
$ hadoop distcp
usage: distcp OPTIONS [source_path...] <target_path>
OPTIONS
-append Reuse existing data in target files and append new
data to them if possible
-async Should distcp execution be blocking
-atomic Commit all changes or none
-bandwidth <arg> Specify bandwidth per map in MB
-delete Delete from target, files missing in source
-diff <arg> Use snapshot diff report to identify the
difference between source and target
-f <arg> List of files that need to be copied
-filelimit <arg> (Deprecated!) Limit number of files copied to <= n
-i Ignore failures during copy
-log <arg> Folder on DFS where distcp execution logs are
saved
-m <arg> Max number of concurrent maps to use for copy
-mapredSslConf <arg> Configuration for ssl config file, to use with
hftps://
-overwrite Choose to overwrite target files unconditionally,
even if they exist.
-p <arg> preserve status (rbugpcaxt)(replication,
block-size, user, group, permission,
checksum-type, ACL, XATTR, timestamps). If -p is
specified with no <arg>, then preserves
replication, block size, user, group, permission,
checksum type and timestamps. raw.* xattrs are
preserved when both the source and destination
paths are in the /.reserved/raw hierarchy (HDFS
only). raw.* xattrpreservation is independent of
the -p flag. Refer to the DistCp documentation for
more details.
-sizelimit <arg> (Deprecated!) Limit number of files copied to <= n
bytes
-skipcrccheck Whether to skip CRC checks between source and
target paths.
-strategy <arg> Copy strategy to use. Default is dividing work
based on file sizes
-tmp <arg> Intermediate work path to be used for atomic
commit
-update Update target, copying only missingfiles or
directories其中source_path,taget_path需要带上地址前缀以区分不同的集群.例如
hadoop distcp hdfs://nn1:8020/foo/a hdfs://nn2:8020/bar/foo这表示从nn1集群拷贝数据到nn2集群.总体而言,distCp的可选参数还是做到了相当细粒度的控制,比如skipcrccheck的选项,可以跳过crc checksum的校验,checksum的跳过可能会影响到distCp数据完整性的判断,但同时此配置的关闭会使拷贝过程更加高效一些.
当然说了这么多,跨机房数据迁移的工作所一定还会出现没有预见到的问题,其中的难度和困难绝对是非常具有挑战性的,可能我们还要利用DistCp的功能然后搭配上自己的解决方案才能做出更棒的方案.希望本文能够大家带来收获.