前言
前一篇文章中刚刚分析完HDFS的异构存储以及相关的存储类型选择策略,浏览量还是不少的,说明大家对于HDFS的异构存储方面的功能还是很感兴趣的.但是其实一个文件Block块从最初的产生到最后的落盘,存储类型选择策略只是其中1步,因为存储类型选择策略只是帮你先筛选了一些符合存储类型要求的存储节点目录位置列表,通过这些候选列表,你还需要做进一步的筛选,这就是本文所准备阐述的另外一个主题,HDFS的副本放置策略.在写本文之前,我搜过网上关于此方面的资料与文章,还是有许多文章写的非常不错的,所以我会在本文中涉及到其他相关方面的个人感觉有用的知识点与大家分享,不至于文章显得太千篇一律了.
何为副本放置策略
首先这里要花一些篇幅来介绍什么是副本放置策略, 有人也会叫他为副本选择策略,这源于此策略的名称, BlockPlacementPolicy.所以这个策略类重在block placement.先来看下这个策略类的功能说明:
This interface is used for choosing the desired number of targets for placing block replicas.大意就是说选择期望的目标节点供副本block存放.
现有副本放置策略
目前在HDFS中现有的副本防止策略类有2大继承子类,分别为BlockPlacementPolicyDefault, BlockPlacementPolicyWithNodeGroup,其中继承关系如下所示:

我们日常生活中提到最经典的3副本策略用的就是BlockPlacementPolicyDefault策略类.3副本如何存放在这个策略中得到了非常完美的实现.在BlockPlacementPolicyDefault类中的注释具体解释了3个副本的存放位置:
The class is responsible for choosing the desired number of targets
for placing block replicas.
The replica placement strategy is that if the writer is on a datanode,
the 1st replica is placed on the local machine,
otherwise a random datanode. The 2nd replica is placed on a datanode
that is on a different rack. The 3rd replica is placed on a datanode
which is on a different node of the rack as the second replica.简要概况起来3点:
- 1st replica. 如果写请求方所在机器是其中一个datanode,则直接存放在本地,否则随机在集群中选择一个datanode.
- 2nd replica. 第二个副本存放于不同第一个副本的所在的机架.
- 3rd replica.第三个副本存放于第二个副本所在的机架,但是属于不同的节点.
所以总的存放效果图如下所示
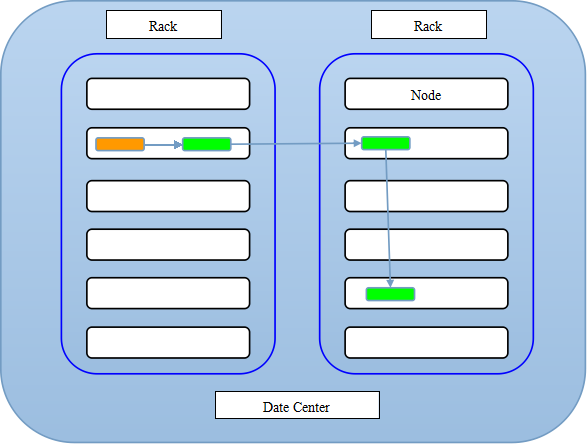
这里橙色区域表示的就是writer写请求者,绿色区域就是1个副本.从这里可以看出,HDFS在容错性的设计上还是做了很多的思考的.从下文开始主要分析的就是BlockPlacementPolicyDefault默认放置策略,至于BlockPlacementPolicyWithNodeGroup也会稍微提一提,但是二者主要区别其实不大.
BlockPlacementPolicyDefault默认副本放置策略的分析
BlockPlacementPolicyDefault这个类中的选择目标节点的处理逻辑还是有些复杂的,我会尽量讲的简单化,如有不理解之处,读者可以自己对照源码进行进一步的学习.
策略核心方法chooseTargets
在默认放置策略方法类中,核心方法就是chooseTargets,但是在这里有2种同名实现方法,唯一的区别是有无favoredNodes参数.favoredNodes的意思是偏爱,喜爱的节点.这2个方法的介绍如下
/**
* choose <i>numOfReplicas</i> data nodes for <i>writer</i>
* to re-replicate a block with size <i>blocksize</i>
* If not, return as many as we can.
*
* @param srcPath the file to which this chooseTargets is being invoked.
* @param numOfReplicas additional number of replicas wanted.
* @param writer the writer's machine, null if not in the cluster.
* @param chosen datanodes that have been chosen as targets.
* @param returnChosenNodes decide if the chosenNodes are returned.
* @param excludedNodes datanodes that should not be considered as targets.
* @param blocksize size of the data to be written.
* @return array of DatanodeDescriptor instances chosen as target
* and sorted as a pipeline.
*/
public abstract DatanodeStorageInfo[] chooseTarget(String srcPath,
int numOfReplicas,
Node writer,
List<DatanodeStorageInfo> chosen,
boolean returnChosenNodes,
Set<Node> excludedNodes,
long blocksize,
BlockStoragePolicy storagePolicy);
/**
* Same as {@link #chooseTarget(String, int, Node, Set, long, List, StorageType)}
* with added parameter {@code favoredDatanodes}
* @param favoredNodes datanodes that should be favored as targets. This
* is only a hint and due to cluster state, namenode may not be
* able to place the blocks on these datanodes.
*/
DatanodeStorageInfo[] chooseTarget(String src,
int numOfReplicas, Node writer,
Set<Node> excludedNodes,
long blocksize,
List<DatanodeDescriptor> favoredNodes,
BlockStoragePolicy storagePolicy) {
}在chooseTargets传入偏爱的节点参数会使得方法在选择节点时候优先选取偏爱节点参数中的节点.这是这个参数的最根本的影响.
chooseTarget无favoredNodes参数实现
我们先来分析 chooseTarget无favoredNodes参数的实现过程,最终会进入到真正的同名实现方法中.我将此过程分为了3个子阶段
1.初始化操作
/** This is the implementation. */ private DatanodeStorageInfo[] chooseTarget(int numOfReplicas, Node writer, List<DatanodeStorageInfo> chosenStorage, boolean returnChosenNodes, Set<Node> excludedNodes, long blocksize, final BlockStoragePolicy storagePolicy) { // 如果目标完成副本数为0或机器节点数量为0,返回空 if (numOfReplicas == 0 || clusterMap.getNumOfLeaves()==0) { return DatanodeStorageInfo.EMPTY_ARRAY; } // 创建黑名单列表集 if (excludedNodes == null) { excludedNodes = new HashSet<Node>(); } // 计算每个机架所允许最大副本数 int[] result = getMaxNodesPerRack(chosenStorage.size(), numOfReplicas); numOfReplicas = result[0]; int maxNodesPerRack = result[1]; ...2.选择目标节点
... // 将所选节点加入到结果列表中,同时加入到移除列表中,意为已选择过的节点 final List<DatanodeStorageInfo> results = new ArrayList<DatanodeStorageInfo>(chosenStorage); for (DatanodeStorageInfo storage : chosenStorage) { // add localMachine and related nodes to excludedNodes addToExcludedNodes(storage.getDatanodeDescriptor(), excludedNodes); } // 计算是否需要避免旧的,未更新的节点 boolean avoidStaleNodes = (stats != null && stats.isAvoidingStaleDataNodesForWrite()); // 选择numOfReplicas规定副本数的目标机器,并返回其中第一个节点 final Node localNode = chooseTarget(numOfReplicas, writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storagePolicy, // 如果不像返回初始选中的目标节点,则进行移除 if (!returnChosenNodes) { results.removeAll(chosenStorage); } ...3.排序目标节点列表,形成pipeline
... // sorting nodes to form a pipeline // 根据最短距离排序目标节点列表,形成pipeline return getPipeline( (writer != null && writer instanceof DatanodeDescriptor) ? writer : localNode, results.toArray(new DatanodeStorageInfo[results.size()]));
在上述的3个子阶段中,第二阶段是其中最主要的策略选择操作同样也是最具复杂性的,所以这里先分析第三个阶段的工作,就是根据已经选择好的目标节点存放位置,然后形成pipeline进行返回.
Pipeline节点的形成
整个过程就是传入目标节点列表参数,经过getPipeline方法的处理,然后返回此pipeline.先来看getPipeline的注释:
Return a pipeline of nodes.
The pipeline is formed finding a shortest path that
starts from the writer and traverses all nodes
This is basically a traveling salesman problem.关键是这句The pipeline is formed finding a shortest path that
starts from the writer,就是说从writer所在节点开始,总是寻找相对路径最短的目标节点,最终形成pipeline,学习过算法的人应该知道,这其实也是经典的TSP旅行商问题.下面是具体的源码实现:
private DatanodeStorageInfo[] getPipeline(Node writer,
DatanodeStorageInfo[] storages) {
if (storages.length == 0) {
return storages;
}
synchronized(clusterMap) {
int index=0;
// 首先如果writer请求方本身不在一个datanode上,则默认选取第一个datanode作为起始节点
if (writer == null || !clusterMap.contains(writer)) {
writer = storages[0].getDatanodeDescriptor();
}
for(; index < storages.length; index++) {
// 获取当前index下标所属的Storage为最近距离的目标storage
DatanodeStorageInfo shortestStorage = storages[index];
// 计算当前距离
int shortestDistance = clusterMap.getDistance(writer,
shortestStorage.getDatanodeDescriptor());
int shortestIndex = index;
for(int i = index + 1; i < storages.length; i++) {
// 遍历计算后面的距离
int currentDistance = clusterMap.getDistance(writer,
storages[i].getDatanodeDescriptor());
if (shortestDistance>currentDistance) {
shortestDistance = currentDistance;
shortestStorage = storages[i];
shortestIndex = i;
}
}
//switch position index & shortestIndex
// 找到新的最短距离的storage,并进行下标替换
if (index != shortestIndex) {
storages[shortestIndex] = storages[index];
storages[index] = shortestStorage;
}
// 找到当前这一轮的最近的storage,并作为下一轮迭代的源节点
writer = shortestStorage.getDatanodeDescriptor();
}
}
return storages;
}一句话概况来说,就是选出一个源节点,根据这个节点,遍历当前可选的下一个目标节点,找出一个最短距离的节点,作为下一轮选举的源节点,这样每2个节点之间的距离总是最近的,于是整个pipeline节点间的距离和就保证是足够小的了.那么现在另外一个问题还没有解决,如何定义和计算2个节点直接的距离,就是下面这行代码
clusterMap.getDistance(writer,
shortestStorage.getDatanodeDescriptor());要计算其中的距离,我们首先要了解HDFS中如何定义节点间的距离,其中涉及到了拓扑逻辑结构的概念,结构图如下:
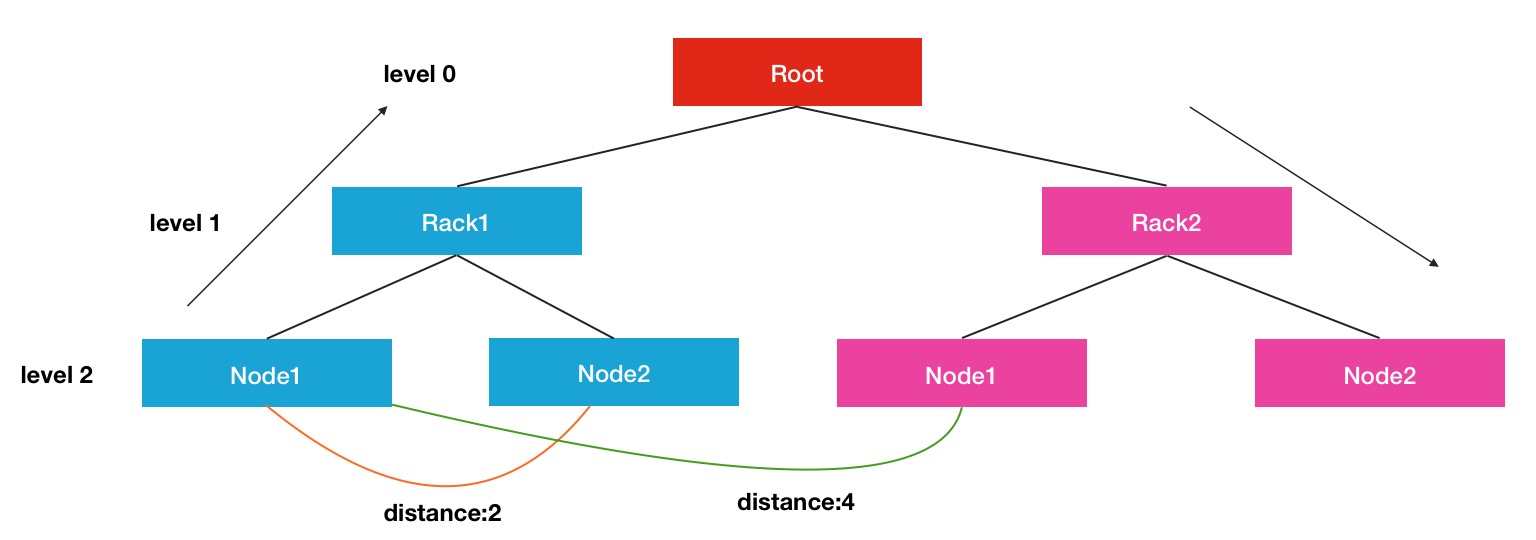
这里显示的是一个三层结构的树形效果图,Root可以看出是一个大的集群,下面划分出了许多个机架,每个机架下面又有很多属于此机架的节点.在每个连接点中,是通过交换机和路由器进行连接的.每个节点间的距离计算方式是通过寻找最近的公共祖先所需要的距离作为最终的结果.比如Node1到Node2的距离是2,就是Node1->Rack1, Rack1->Node2.同理,Rack1的Node1到Rack2的Node1的距离就是4.大家有兴趣的可以学习一下相关算法LCA最近公共祖先算法.
chooseTarget方法主逻辑
下面介绍chooseTarget主要选择逻辑,因为个人感觉是最复杂的,所以放在最后分析.首先,务必要明确以下几个涉及参数的作用和所代表的意义:
final Node localNode = chooseTarget(numOfReplicas, writer, excludedNodes,
blocksize, maxNodesPerRack, results, avoidStaleNodes, storagePolicy,
EnumSet.noneOf(StorageType.class), results.isEmpty());- numOfReplicas, 额外需要复制的副本数
- excludedNodes,移除节点集合,此集合内的节点不应被考虑作为目标节点
- results,当前已经选择好的目标节点集合
- storagePolicy,存储类型选择策略
OK,下面进入具体方法实现.
首节点的选择
我们可以对照上文提到的3副本的存放方式.首先是第一个节点的选择,第一个节点其实是最好选择的,因为他不用其他2个节点的位置影响,但是他同样要约束于请求方所在位置,这里满足2个原则:
- 如果writer请求方本身位于集群中的一个datanode之上,则第一个副本的位置就在本地节点上,很好理解,这样直接就是本地写操作了.
- 如果writer请求方纯粹来源于外界客户端的写请求时,则从已选择好的目标节点result列表中挑选第一个节点作为首个节点.
- 如果result列表中还是没有任何节点,则会从集群中随机挑选1个node作为第一个localNode.
后续还进行了如下的操作
// 如果额外需要请求副本数为0,或者集群中没有可选节点
if (numOfReplicas == 0 || clusterMap.getNumOfLeaves()==0) {
// 如果writer请求者在其中一个datanode上则返回此节点,否则直接返回null
return (writer instanceof DatanodeDescriptor) ? writer : null;
}
// 获取已经选择完成的节点数
final int numOfResults = results.size();
// 计算期望希望达到的副本总数
final int totalReplicasExpected = numOfReplicas + numOfResults;
// 如果writer为空或不在datanode上,则取出已选择好列表中的第一个位置所在节点,赋值给writer
if ((writer == null || !(writer instanceof DatanodeDescriptor)) && !newBlock) {
writer = results.get(0).getDatanodeDescriptor();
}
// Keep a copy of original excludedNodes
// 做一份移除列表名单的拷贝
final Set<Node> oldExcludedNodes = new HashSet<Node>(excludedNodes);
// choose storage types; use fallbacks for unavailable storages
// 根据存储策略获取副本需要满足的存储类型列表,如果有不可用的存储类型,会采用fallback的类型
final List<StorageType> requiredStorageTypes = storagePolicy
.chooseStorageTypes((short) totalReplicasExpected,
DatanodeStorageInfo.toStorageTypes(results),
unavailableStorages, newBlock);
// 将存储类型列表进行计数统计,并存于map中
final EnumMap<StorageType, Integer> storageTypes =
getRequiredStorageTypes(requiredStorageTypes);
if (LOG.isTraceEnabled()) {
LOG.trace("storageTypes=" + storageTypes);
}
...三副本位置的选取
下面是非常巧妙的3副本存储位置的选取,需要与上图描述的存放方式进行对照,可能会好理解一些
...
// 如果numOfReplicas或requiredStorageTypes大小为0,则抛出异常
try {
if ((numOfReplicas = requiredStorageTypes.size()) == 0) {
throw new NotEnoughReplicasException(
"All required storage types are unavailable: "
+ " unavailableStorages=" + unavailableStorages
+ ", storagePolicy=" + storagePolicy);
}
// 如果已选择的目标节点数量为0,则表示3副本一个都还没开始选,首先从选本地节点开始
if (numOfResults == 0) {
writer = chooseLocalStorage(writer, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, storageTypes, true)
.getDatanodeDescriptor();
// 如果此时目标需求完成的副本数为降为0,代表选择目标完成,返回第一个节点writer
if (--numOfReplicas == 0) {
return writer;
}
}
// 取出result列表第一个节点
final DatanodeDescriptor dn0 = results.get(0).getDatanodeDescriptor();
// 前面的过程已经完成首个本地节点的选择,此时进行不同机房的节点选择
if (numOfResults <= 1) {
// 选择1个不同于dn0所在机房的一个目标节点位置
chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
// 如果此时目标需求完成的副本数为降为0,代表选择目标完成,返回第一个节点writer
if (--numOfReplicas == 0) {
return writer;
}
}
// 如果经过前面的处理,节点选择数在2个以内,需要选取第3个副本
if (numOfResults <= 2) {
// 取出result列表第二个节点
final DatanodeDescriptor dn1 = results.get(1).getDatanodeDescriptor();
// 如果dn0,dn1所在同机房,
if (clusterMap.isOnSameRack(dn0, dn1)) {
// 则选择1个不同于dn0,dn1所在机房的副本位置
chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
} else if (newBlock){
// 如果是新的block块,则选取1个于dn1所在同机房的节点位置
chooseLocalRack(dn1, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
} else {
// 否则选取于writer同机房的位置
chooseLocalRack(writer, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
}
// 如果此时目标需求完成的副本数为降为0,代表选择目标完成,返回第一个节点writer
if (--numOfReplicas == 0) {
return writer;
}
}
// 如果副本数已经超过2个,说明设置的block的时候,已经设置超过3副本的数量
// 则剩余位置在集群中随机选择放置节点
chooseRandom(numOfReplicas, NodeBase.ROOT, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, storageTypes);如果看完这段逻辑,你还不理解的话,没有关系,只要明白经典的3副本存放位置,多余的副本随机存放的原理即可.当然在其间选择的过程中可能会发生异常,因为有的时候我们没有配置机架感知,集群中都属于一个默认机架的default-rack,则会导致chooseRemoteRack的方法出错,因为没有满足条件的其余机架,这时需要一些重试策略.
if (retry) {
for (DatanodeStorageInfo resultStorage : results) {
addToExcludedNodes(resultStorage.getDatanodeDescriptor(),
oldExcludedNodes);
}
// 剔除之前完成的选择的目标位置,重新计算当前需要复制的副本数
numOfReplicas = totalReplicasExpected - results.size();
// 重新调用自身方法进行复制
return chooseTarget(numOfReplicas, writer, oldExcludedNodes, blocksize,
maxNodesPerRack, results, false, storagePolicy, unavailableStorages,
newBlock);
}chooseLocalStorage,chooseLocalRack,chooseRemoteRack和chooseRandom方法
标题显示的四个选择目标节点位置的方法其实是一个优先级渐渐降低的方法,首先选择本地存储位置.如果没有满足条件的,再选择本地机架的节点,如果还是没有满足条件的,进一步降级选择不同机架的节点,最后随机选择集群中的节点,关系图如下
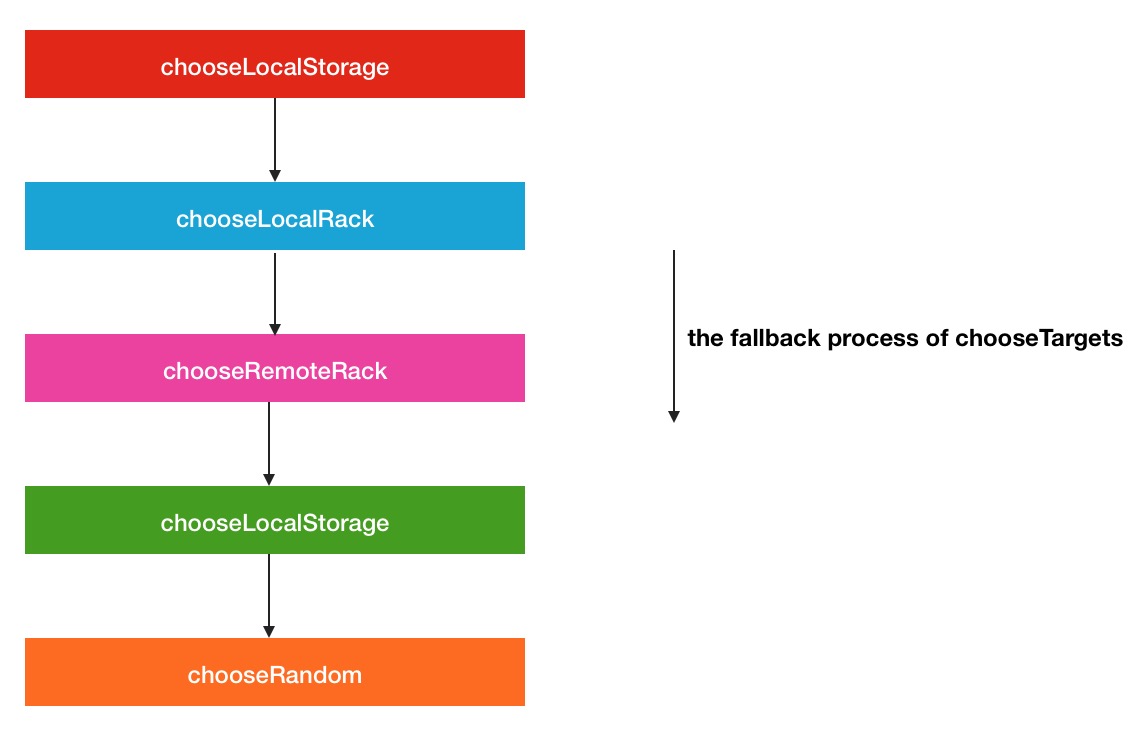
但是这里还是要区分一下,chooseLocalStorage方法,与其余的3个方法稍显不同,单独实现,而其余的方法是通过传入不同参数直接或间接调用
chooseRandom方法.
首先看下chooseLocalStorage方法实现
protected DatanodeStorageInfo chooseLocalStorage(Node localMachine,
Set<Node> excludedNodes, long blocksize, int maxNodesPerRack,
List<DatanodeStorageInfo> results, boolean avoidStaleNodes,
EnumMap<StorageType, Integer> storageTypes, boolean fallbackToLocalRack)
throws NotEnoughReplicasException {
// if no local machine, randomly choose one node
if (localMachine == null) {
// 如果本地节点为空,则降级选择1个随机节点
return chooseRandom(NodeBase.ROOT, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, storageTypes);
}
if (preferLocalNode && localMachine instanceof DatanodeDescriptor) {
DatanodeDescriptor localDatanode = (DatanodeDescriptor) localMachine;
// otherwise try local machine first
if (excludedNodes.add(localMachine)) { // was not in the excluded list
for (Iterator<Map.Entry<StorageType, Integer>> iter = storageTypes
.entrySet().iterator(); iter.hasNext(); ) {
Map.Entry<StorageType, Integer> entry = iter.next();
// 遍历本地节点可用的存储目录
for (DatanodeStorageInfo localStorage : DFSUtil.shuffle(
localDatanode.getStorageInfos())) {
StorageType type = entry.getKey();
// 加入满足条件的存储目录位置
if (addIfIsGoodTarget(localStorage, excludedNodes, blocksize,
maxNodesPerRack, false, results, avoidStaleNodes, type) >= 0) {
int num = entry.getValue();
if (num == 1) {
iter.remove();
} else {
entry.setValue(num - 1);
}
return localStorage;
}
}
}
}
}
if (!fallbackToLocalRack) {
return null;
}
// 本地节点没有满足条件的存储位置,则降级选取同机架的节点
// try a node on local rack
return chooseLocalRack(localMachine, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, storageTypes);
}chooseLocalRack和chooseRemoteRack比较类似,
chooseLocalRack
// no local machine, so choose a random machine if (localMachine == null) { return chooseRandom(NodeBase.ROOT, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes); } // 获取本地机架名 final String localRack = localMachine.getNetworkLocation(); try { // choose one from the local rack // 将机架名作为scope参数传入 return chooseRandom(localRack, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes);chooseRemoteRack
// 获取本地机架名称,带上前缀字符~,作为scope参数传入 chooseRandom(numOfReplicas, "~" + localMachine.getNetworkLocation(), excludedNodes, blocksize, maxReplicasPerRack, results, avoidStaleNodes, storageTypes);
从这里我们可以看到,这里最明显的区别就是chooseRandom的scope参数的传入,scope参数的直接作用就是会选择出是否属于此机架下的节点列表
DatanodeDescriptor chosenNode =
(DatanodeDescriptor)clusterMap.chooseRandom(scope);在NetworkTopology下有了具体的实现
/** randomly choose one node from <i>scope</i>
* if scope starts with ~, choose one from the all nodes except for the
* ones in <i>scope</i>; otherwise, choose one from <i>scope</i>
* @param scope range of nodes from which a node will be chosen
* @return the chosen node
*/
public Node chooseRandom(String scope) {
netlock.readLock().lock();
try {
if (scope.startsWith("~")) {
return chooseRandom(NodeBase.ROOT, scope.substring(1));
} else {
return chooseRandom(scope, null);
}
} finally {
netlock.readLock().unlock();
}
}具体细节的实现,读者可以自行研究.根据机架选择好节点之后,同样会进行Storage存储位置的选择判断,然后加入到result目标列表中.
目标Storage好坏的判断
如果block放置节点位置已经初步选择好了,是否意味着此位置就可以加入最终的result列表中呢,答案是否定的,因为这里还要经过最后一道严谨的对于Storage的验证.(这里要明确一点:目标位置result类别存储的对象是DatanodeStorageInfo,这个类表示的是具体到节点存储磁盘目录级别的信息,并不是广义上的Node),需要满足以下几个条件
- storage的存储类型是要求给定的存储类型
- storage不能是READ_ONLY只读的
- storage不能是坏的
- storage所在机器不应该是已下线或下线中的节点
- storage所在节点不应该是旧的,一段时间内没有更新心跳的节点
- 节点内保证有足够的剩余空间能满足写Block要求的大小
- 要考虑节点的IO负载繁忙程度
- 要满足同机架内最大副本数的限制
可见,验证的条件还是非常苛刻,具体代码见BlockPlacementPolicyDefault的isGoodTarget方法.
chooseTargets的调用
chooseTargets的调用分为有favoredNodes参数和无favoredNodes参数参数2类.
无参数的chooseTargets主要被BlockManager对象所调用,如图

其中RepliactionWork主要做的就是集群中待复制的副本块.
而带favoredNodes参数的调用则是外界主动设置进来的,调用场景如下
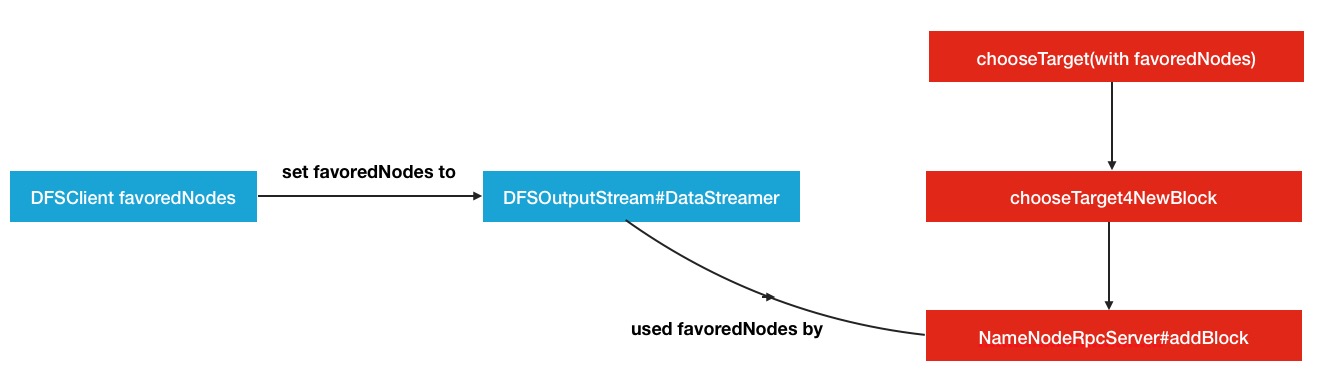
favoredNodes的源头是DFSClient客户端主动设置进来,然后创建到DFSOutputStream的DataStream中,然后被后续方法所调用.但是DFSClient在创建默认DFSOutputStream时是默认不带favoredNodes传入的
public DFSOutputStream create(String src,
FsPermission permission,
EnumSet<CreateFlag> flag,
short replication,
long blockSize,
Progressable progress,
int buffersize,
ChecksumOpt checksumOpt)
throws IOException {
return create(src, permission, flag, true,
replication, blockSize, progress, buffersize, checksumOpt, null);
}就是最后一个参数null.其实传入的favoredNodes更多的是一种期望,并不一定真正能被namenode最后真正存放,因为中间会经过很多因素的判断,而且在后面的Balance数据平衡的过程中,某些block还是会被挪走,就不会按照原来的位置存.
BlockPlacementPolicyWithNodeGroup继承类
BlockPlacementPolicyWithNodeGroup是BlockPlacementPolicyDefault的继承子类.前者与后者在原理上十分类似,不过在逻辑上从机架是否相同的判断变为了是否为同个Node-Group的判断.下面是其中的注释声明:
The class is responsible for choosing the desired number of targets
for placing block replicas on environment with node-group layer.
The replica placement strategy is adjusted to:
If the writer is on a datanode, the 1st replica is placed on the local
node (or local node-group), otherwise a random datanode.
The 2nd replica is placed on a datanode that is on a different rack with 1st
replica node.
The 3rd replica is placed on a datanode which is on a different node-group
but the same rack as the second replica node.他是一个4层层级结构,在Rack机架层下还多了Node-Group层,结构图如下:

由于与其父类的逻辑没有很大的差别,就不展开做阐述了.
总结
以上内容就是本文所要表达的HDFS放置策略的内容了,可能内容量上有点大,部分地方描述的可能也有不够好的地方,希望大家通过此文能对HDFS的3副本策略以及背后的HDFS的放置策略有更深的了解.
参考链接
1.http://www.ibm.com/developerworks/cn/data/library/bd-1505-hdfs-uilbps-optimize/index.html