前言
上周写了一篇译文专门从结构设计的层面来分析HDFS的QJM的架构设计,总体而言,文章偏重理论介绍.本文将继续围绕QJM机制展开分析,但是不同点在于,本文将会从更细粒度的层面来分析这套机制,帮助大家从源代码层面理解QJM的具体实现.本文将从Active/Standby的editlog读写,QJM的RPC调用过程以及JournalNode的同步/恢复三方面进行具体的分析.
Active/Standby的editlog读写
更直接地来说,此标题所表示的意思其实是Active/Standby的NameNode之间的数据同步,通过的”媒介信息”就是editlog.下面用一句话来概况这个过程,如下:
ANN写editlog到各个JN上,然后SNN再从这些JN上以流式的方式读取editlog,然后load到自己的内存中,以此保证自身与ANN上数据的一致性.
当然,上述过程中会有少许的延时,因为SNN做tail editlog动作是周期性的执行,并不是实时的.至于SNN具体如何去读edilog的过程,后面将会提到.
下面这张非常经典的HDFS的HA模式图直观地展示了上面所说的过程(请关注中间那块区域):
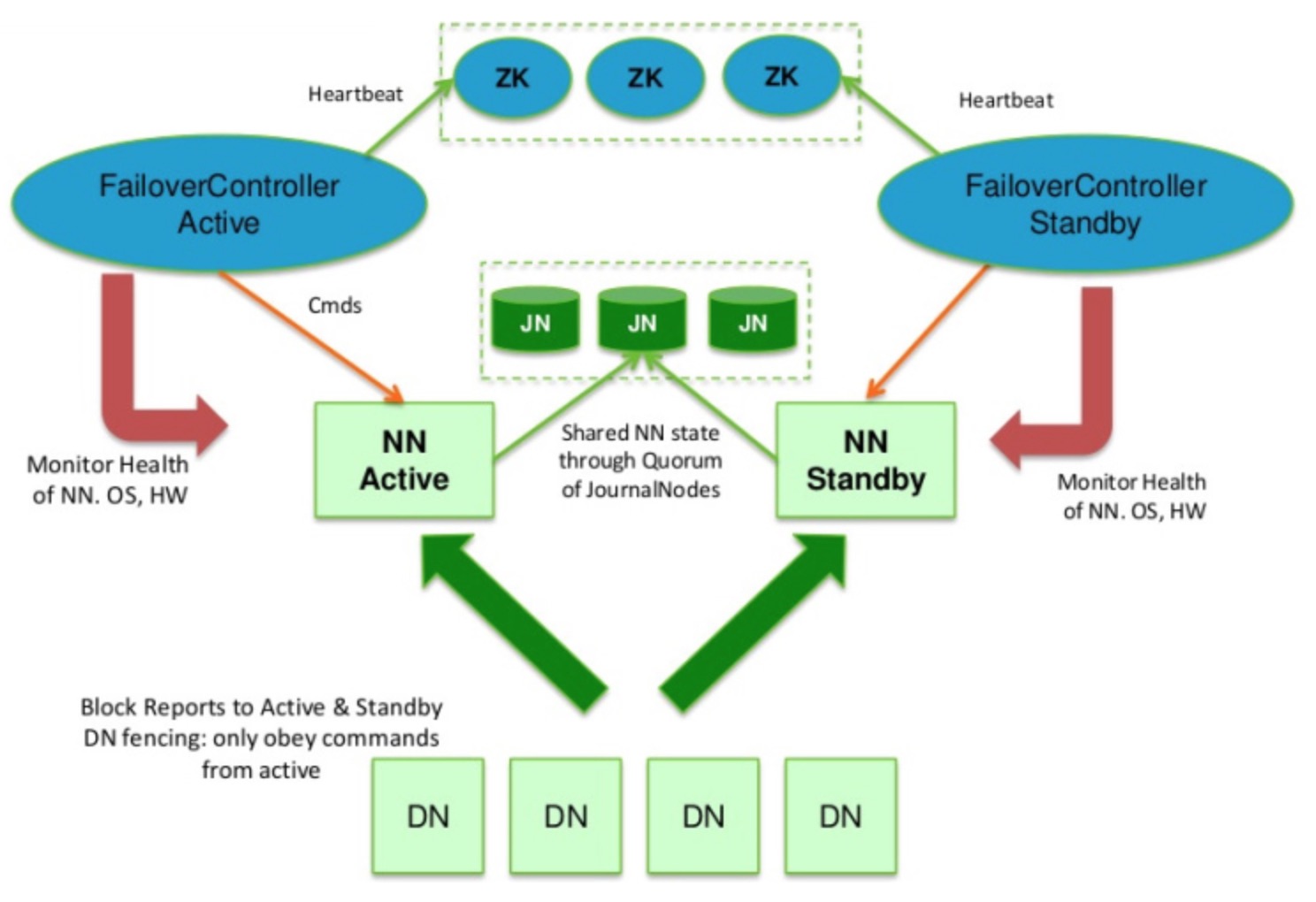
图 1-1 HDFS HA模式
ANN如何向各个JN写edlitlog的过程在下文中将会提到,所以此部分主要来讨论讨论SNN如何做定期的editlog-tail的动作.实现这个功能的核心类叫做EditLogTailer,下面我们直接进入此类.
这是源码中对此类功能的介绍:
EditLogTailer represents a thread which periodically reads from edits journals and applies the transactions contained within to a given FSNamesystem.
这里就不做解释了.下面再来看看几个主要周期时间的定义:
- 1.logRollPeriodMs:ANN写入新editlog的最长容忍时间,如果距离上次写完的时间已经超过此间隔时间,则会触发ANN做一次rollEditLog的动作,此配置项由dfs.ha.log-roll.period所控制,默认时间120s.
- 2.sleepTimeMs:SNN同步editlog日志的周期时间,由配置项dfs.ha.tail-edits.period所控制,默认时间60s.也就是说,SNN会每隔60s,从JN节点中读取新写入的editlog.
上述2个参数刚好是一个控制写速率,另一个控制读速率,通过调整这2个参数值,在一定程度上可以控制ANN与SNN之间元数据的同步速率.而在EditLogTailer中最主要的操作则是在EditLogTailerThread,上面定义的2个关键的时间变量也是在此线程中被调用.
private class EditLogTailerThread extends Thread {
private volatile boolean shouldRun = true;
...
@Override
public void run() {
SecurityUtil.doAsLoginUserOrFatal(
new PrivilegedAction<Object>() {
@Override
public Object run() {
// 执行doWork主操作方法
doWork();
return null;
}
});
}在doWork方法中,将会进行定期的tail editlog的操作.
private void doWork() {
while (shouldRun) {
try {
// There's no point in triggering a log roll if the Standby hasn't
// read any more transactions since the last time a roll was
// triggered.
// 这边会判断是否超过ANN定期写新editlog的最长时间
if (tooLongSinceLastLoad() &&
lastRollTriggerTxId < lastLoadedTxnId) {
triggerActiveLogRoll();
}
/**
* Check again in case someone calls {@link EditLogTailer#stop} while
* we're triggering an edit log roll, since ipc.Client catches and
* ignores {@link InterruptedException} in a few places. This fixes
* the bug described in HDFS-2823.
*/
if (!shouldRun) {
break;
}
// Prevent reading of name system while being modified. The full
// name system lock will be acquired to further block even the block
// state updates.
namesystem.cpLockInterruptibly();
try {
// 做SNN tail editlog的操作
doTailEdits();
} finally {
namesystem.cpUnlock();
}
//Update NameDirSize Metric
//...
try {
// 进行周期时间的睡眠
Thread.sleep(sleepTimeMs);
} catch (InterruptedException e) {
LOG.warn("Edit log tailer interrupted", e);
}
}
}
}我们继续进入doTailEdits方法的实现,
@VisibleForTesting
void doTailEdits() throws IOException, InterruptedException {
// Write lock needs to be interruptible here because the
// transitionToActive RPC takes the write lock before calling
// tailer.stop() -- so if we're not interruptible, it will
// deadlock.
namesystem.writeLockInterruptibly();
try {
FSImage image = namesystem.getFSImage();
long lastTxnId = image.getLastAppliedTxId();
if (LOG.isDebugEnabled()) {
LOG.debug("lastTxnId: " + lastTxnId);
}
Collection<EditLogInputStream> streams;
try {
// 获取editlog输出流进行读取
streams = editLog.selectInputStreams(lastTxnId + 1, 0,
null, inProgressOk, true);
...现在问题来了,这个线程是在哪里被启动运行的呢?下面的代码给出了明确的答复.
void startStandbyServices(final Configuration conf) throws IOException {
LOG.info("Starting services required for standby state");
if (!getFSImage().editLog.isOpenForRead()) {
// During startup, we're already open for read.
getFSImage().editLog.initSharedJournalsForRead();
}
blockManager.setPostponeBlocksFromFuture(true);
// Disable quota checks while in standby.
dir.disableQuotaChecks();
// 在Standby NameNode服务中启动editlog tailer服务
editLogTailer = new EditLogTailer(this, conf);
editLogTailer.start();
...也就是每次NameNode切换为Standby服务的时候.
QJM机制中的RPC调用
这一小节主要讨论的主题是QJM机制中的RPC调用.在分析QJM的RPC调用过程之前,我们先来看看这里面到底分为哪几类RPC调用.主要为下面四大分类:
- 1.发起新写入editlog的RPC调用,比如startLogSegment方法.
- 2.恢复/同步editlog的RPC调用,比如recoverUnfinalizedSegments方法.
- 3.确认editlog完成的RPC调用,比如finalizeLogSegment方法.
- 4.其他相关的RPC调用,比如doPreUpgrade,format方法等.
本人对QuorumJournalManager中所有的RPC调用方法做了一个汇总,如下图:
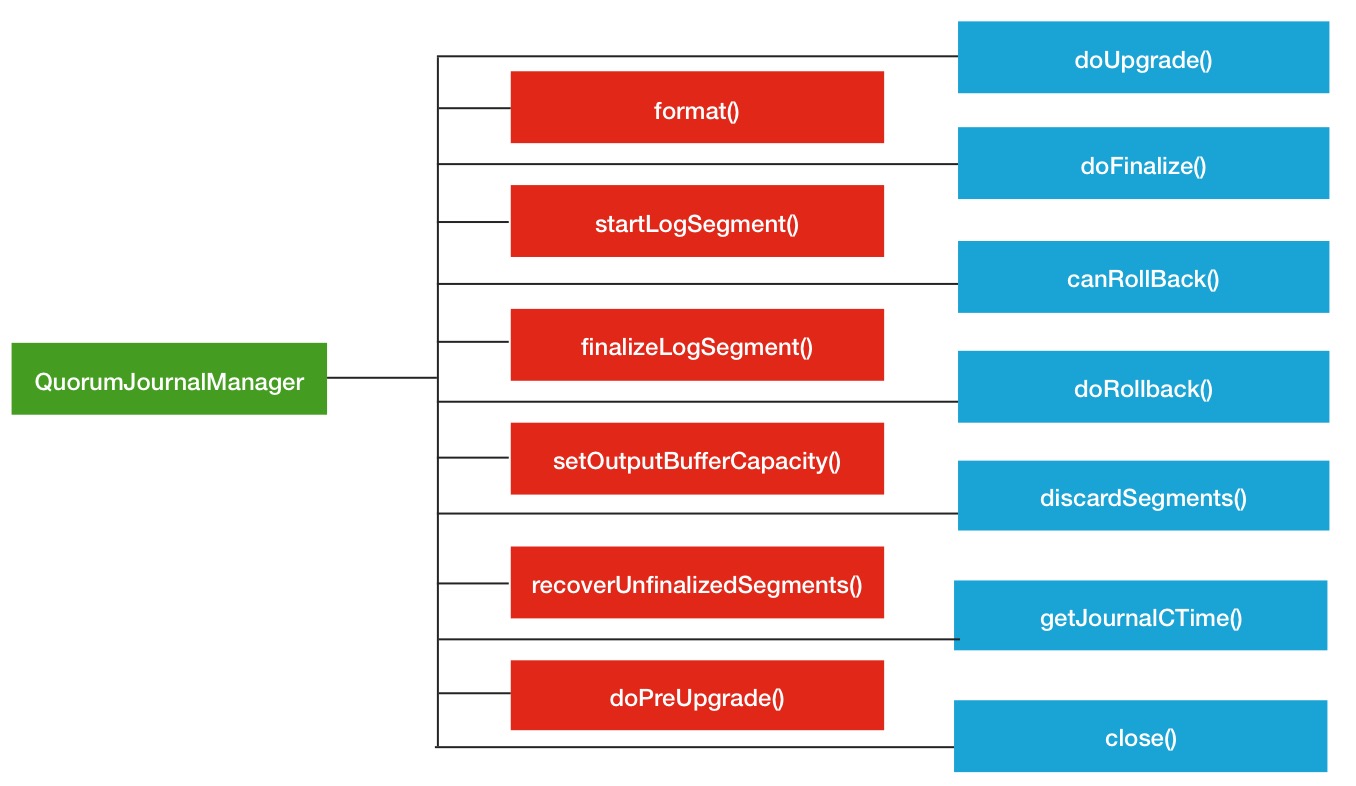
图 1-2 QJM RPC调用方法
上述各个RPC调用的过程大致相同,这里以finalizeLogSegment方法调用为例.首先是外界写editlog完成了,紧接着触发了QuorumJournalManager的finalizeLogSegment方法,代码如下:
@Override
public void finalizeLogSegment(long firstTxId, long lastTxId)
throws IOException {
// 执行AsyncLoggerSet的finalizeLogSegment方法
QuorumCall<AsyncLogger,Void> q = loggers.finalizeLogSegment(
firstTxId, lastTxId);
// 等待回复
loggers.waitForWriteQuorum(q, finalizeSegmentTimeoutMs,
String.format("finalizeLogSegment(%s-%s)", firstTxId, lastTxId));
}继续里面的finalizeLogSegment调用:
public QuorumCall<AsyncLogger, Void> finalizeLogSegment(long firstTxId,
long lastTxId) {
Map<AsyncLogger, ListenableFuture<Void>> calls = Maps.newHashMap();
for (AsyncLogger logger : loggers) {
// AsyncLogger的finalizeLogSegment方法
calls.put(logger, logger.finalizeLogSegment(firstTxId, lastTxId));
}
return QuorumCall.create(calls);
}在这里,我们会进入到AsyncLogger的具体实现子类IPCLoggerChannel的finalizeLogSegment调用:
public ListenableFuture<Void> finalizeLogSegment(
final long startTxId, final long endTxId) {
return singleThreadExecutor.submit(new Callable<Void>() {
@Override
public Void call() throws IOException {
throwIfOutOfSync();
getProxy().finalizeLogSegment(createReqInfo(), startTxId, endTxId);
return null;
}
});
}IPCLoggerChannel更形象的说是一个连向一个远程JournalNode的Hadoop IPC的代理类.
然后我们会进入JournalNodeRpcServer的相应方法中:
public void finalizeLogSegment(RequestInfo reqInfo, long startTxId,
long endTxId) throws IOException {
jn.getOrCreateJournal(reqInfo.getJournalId())
.finalizeLogSegment(reqInfo, startTxId, endTxId);
}最终在Journal类中将会进行实际操作的执行:
public synchronized void finalizeLogSegment(RequestInfo reqInfo, long startTxId,
long endTxId) throws IOException {
checkFormatted();
checkRequest(reqInfo);
boolean needsValidation = true;
// Finalizing the log that the writer was just writing.
if (startTxId == curSegmentTxId) {
...
}
...
}我们可以看到,整个调用过程还是有点长的,下面是finalizeLogSegment的调用流程图:
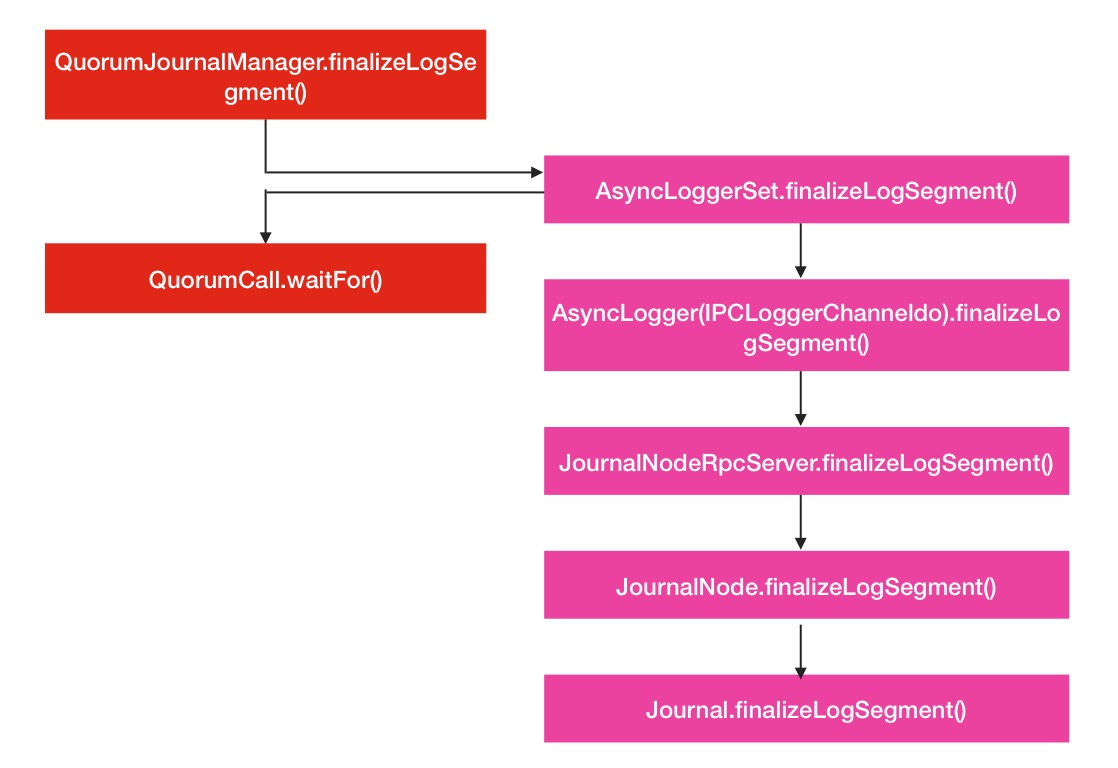
图 1-3 QJM finalizeLogSegment调用流程图
在上面的示意图中,出现了一个QuorumCall.waitFor的方法,这意味着你必须等待各个JournalNode的响应回复.在其他的RPC调用方法中,也出现了这样的响应等待方法,但是有一个不同点出现了:
在QuorumJournalManager中并不是所有的方法都必须等待全部的返回,部分调用只需保证超过一半返回结果即可.
上面说的实质上就是quorum的机制,我们在QuorumJournalManager的RPC调用中看到了具体的体现.我们同样举finalizeLogSegment的调用为例:
@Override
public void finalizeLogSegment(long firstTxId, long lastTxId)
throws IOException {
// 执行AsyncLoggerSet的finalizeLogSegment方法
QuorumCall<AsyncLogger,Void> q = loggers.finalizeLogSegment(
firstTxId, lastTxId);
// 等待超过一半的返回
loggers.waitForWriteQuorum(q, finalizeSegmentTimeoutMs,
String.format("finalizeLogSegment(%s-%s)", firstTxId, lastTxId));
}我们进入waitForWriteQuorum的具体实现:
<V> Map<AsyncLogger, V> waitForWriteQuorum(QuorumCall<AsyncLogger, V> q,
int timeoutMs, String operationName) throws IOException {
// 获取大多数的数值,在这里就是半数+1
int majority = getMajoritySize();
try {
// 将majority传入作为最小满足回复数
q.waitFor(
loggers.size(), // either all respond
majority, // or we get a majority successes
majority, // or we get a majority failures,
timeoutMs, operationName);
...继续进入getMajoritySize方法,来看看它是怎么计算此值的:
/**
* @return the number of nodes which are required to obtain a quorum.
*/
int getMajoritySize() {
return loggers.size() / 2 + 1;
}可以看到,这其实就是quorum值的计算.正如上面所提到的,并不是所有的方法都只需要等待quorum数量的返回的,比如说下面这个方法,它就必须等待所有回复信息的返回:
@Override
public void doFinalize() throws IOException {
QuorumCall<AsyncLogger, Void> call = loggers.doFinalize();
try {
// 需要等待所有数量的返回信息
call.waitFor(loggers.size(), loggers.size(), 0, FINALIZE_TIMEOUT_MS,
"doFinalize");
...下面给出QJM中完整的RPC调用过程,包含了上游的调用以及下游实际操作的对象类:
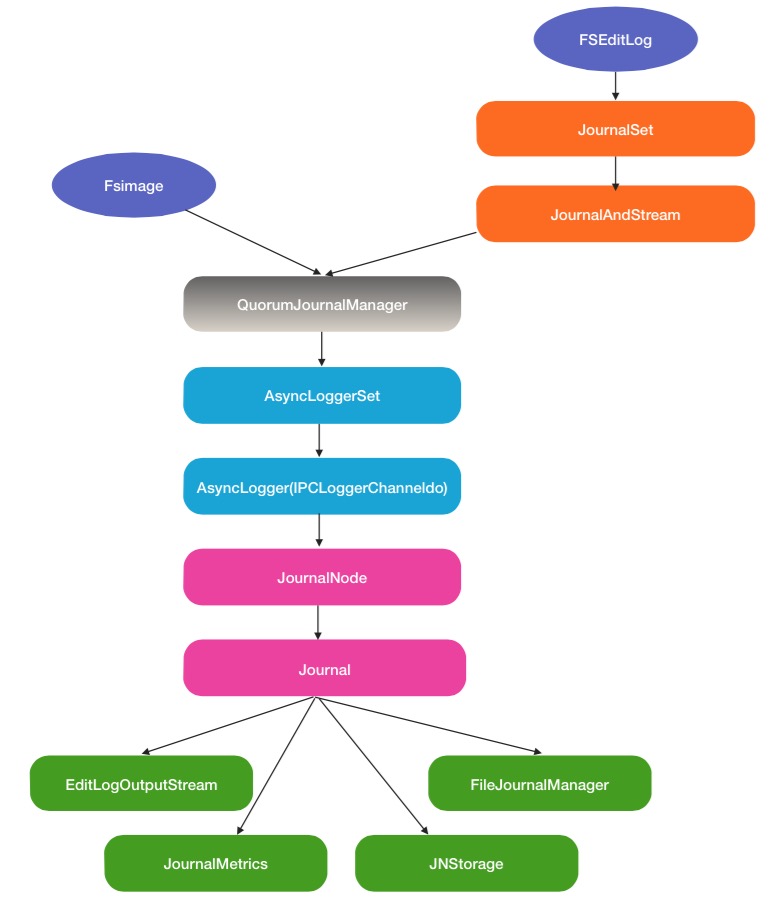
图 1-4 QJM PRC完整调用流程图
JournalNode的同步与恢复
看到这个小标题,可能有人会有疑问,为什么会有JournalNode的同步与恢复?哪些情况会导致JournalNode同步/恢复情况的发生呢?下面给出此触发场景:
NameNode在向JounralNode写editlog的时候,并不需要等待所有JournalNode的写成功,保证quorum数量的成功即可,在此期间就会可能有失败的情况发生,失败的情况会导致此JN同比其他正常JN丢失了一些数据信息,这个时候就需要从其他JN中选取一个节点进行内容的恢复与同步.
下面举一个例子,现在有3个JournalNode,JN1,JN2,JN3,目前最新txid为150,现在NameNode将要进行一次新的editlog的写入,如下:

图 1-5 JournalNode的同步/恢复
如上图所示,NameNode发起了新的3个txid的写入,然而在写向JN1的时候失败了,其txid还是维持在原来的150.但是JN已经保证了quorum数量的写成功(在此为2),这时JN1可以同时选择JN2或JN3进行txid的同步.
当然,上述例子只是一个非常简单的同步/恢复的场景,在这其中其实还有非常多复杂的场景,比如说此时写入成功的数量没达到quorum数量的时候怎么办,finalize editlog的时候出错了怎么恢复等等,更多例子可以查阅HDFS QJM的官方设计文档,里面列举了非常多的场景.
参考资料
[1].https://issues.apache.org/jira/secure/attachment/12547598/qjournal-design.pdf