文章目录
前言
在HDFS的DN中,为了计算DN的capacity使用量,DN会针对其自身的每块盘路径,进行du操作,然后将此数据汇报到NN中,然后NN就知道了下面所有DN的实际空间使用容量了。然后NN就知道哪些DN有空间能被写数据进去,哪些是空间不足的。为了保证数据使用量的近实时性,目前DN是以默认10分钟的间隔时间做du操作的。假设按照一个DN节点12个数据目录对应12块盘的情况,就会有12个du操作在每个10分钟内都会执行一次。当节点存储的数据使用率比较高的时候,这个开销影响绝对是存在的。有时甚至会引发阻塞io,系统load增高的情况。相信HDFS du的这个问题在很多大规模的集群运维过程中都或多或少的存在着。本文笔者来谈谈一种不是简单增大du执行时间的改良措施,从更深一个层面来优化这个问题。
DataNode中Du操作的性能问题
可能很多人不太理解,一个简单的du操作,哪里来的性能问题呢?这得从du执行的原理说起。du命令全程disk usage,它的统计原理在于将目标路径下的当前没有被删除的文件进行大小累加,然后得出总使用量。这种计算方式在文件数量少时往往不会表现出什么问题。但是当目标路径目录多,文件多的时候,du会表现出明显的时间执行耗时。
而在这一点上,df命令则用的是另一种更加高效的方式,它的统计值来通过文件系统获取的。但是df命令的一个最不适用的地方在于它不能按照具体目录进行使用量的统计。df是按照所在磁盘级别进行统计的。换句话说,用df命令在属于同一块物理盘的子路径下执行df命令,获取的值会是完全一致的。比较遗憾,这种情况将无法支持DataNode多block pool共用一块盘的情况。
我们再来进行更深入地思考,文件目录数繁多的情况下,如何进行du的改善呢?
Linux directory、inode cache对于du的影响
下面我们从kernel层面来聊聊与du执行相关的因素。
我们知道在linux文件系统中,文件和目录的组织形式是以inode的形式管理的。用户对于文件、目录的访问实际上是先访问其对应的inode的信息的。对于某些频繁的目录问题,倘若我们能将其inode信息cache起来,供下次访问时直接提取,将会明显加速用户的整个访问过程。而linux的VFS Inode Cache就是负责做这个事情的,而专门针对目录的访问,还有专门对应的directory cache。Directory cache内部采用的是LRU算法来进行cache的更新的,这能保证cache整体较高的活跃度。
这个时候我们再来看du多文件目录操作的问题,这里面慢的原因除了文件变多的原因之外,还有cache空间的不足,cache只提供了部分的inode cache。其它的文件目录访问走的是真实的inode访问,自然整个过程会慢上许多。
在Linux系统中,提供了以下参数来控制系统访问inode的方式,是尽可能地去利用cache做inode的访问还是按照非cache的方式来。
vm.vfs_cache_pressure
该项表示内核回收用于directory和inode cache内存的倾向:
缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比
降低该值低于100,将导致内核倾向于保留directory和inode cache,但同时意味着cahce使用掉的系统memory将会增加。
增加该值超过100,将导致内核倾向于回收directory和inode cache。
综上所述,改变系统参数vm.vfs_cache_pressure会是一个可行解,在不改变du的文件目录数的情况。那么还有一种方法,就是改变DN的目录结构,使得du操作能够跑的更快一些,以下就是本文将要阐述的另外一块内容了。
DataNode Layout升级减少现有目录层级
要想通过减少DN的数据存储目录,文件数来减少du的计算耗时,改变文件数不是一个简单的做法,因为block文件数是很难改变的,因为它都是独立存在代表一个block file。在这里,改变DN数据存储的目录数是一个不错的方案,
这里不得不提早期版本的block存储方式。早期版本的HDFS采用的是一种256x256的两级目录来存储block文件的,更具体地来说应该是(subdir0-255)x(subdir0-255)。而这里的第一级,第二级的目录确定,是依赖于block id而定的。相关生成逻辑如下:
/**
* Get the directory where a finalized block with this ID should be stored.
* Do not attempt to create the directory.
* @param root the root directory where finalized blocks are stored
* @param blockId
* @return
*/
public static File idToBlockDir(File root, long blockId) {
int d1 = (int)((blockId >> 16) & 0xff);
int d2 = (int)((blockId >> 8) & 0xff);
String path = DataStorage.BLOCK_SUBDIR_PREFIX + d1 + SEP +
DataStorage.BLOCK_SUBDIR_PREFIX + d2;
return new File(root, path);
}
以上是通过blockId来确定两级subdir的执行逻辑,主要的思路是采用位运算的操作而非取余操作。下面通过一个实际的例子来阐述,某block文件目录位置如下:
/hadoop/hdfs/data/current/BP-xx.xx.xx.xx/current/finalized/subdir208/subdir192
[hdfs@xxxx subdir192]$ ls -l
total 108
-rw-r–r-- 1 hdfs hdfs 103445 Mar 28 01:24 blk_1221640230
-rw-r–r-- 1 hdfs hdfs 819 Mar 28 01:24 blk_1221640230_147924128.meta
从上图中,我们可以得知此块的blockId为1221640230,然后我们来算目录。
将1221640230转化为二进制数字,为0100 1000 1101 0000 1100 0000 0010 0110
,然后进行右移16位运算,再与0xff计算&运算,0xff是16进制数字,用二进制表示是8个1,计算表达式如下
blockId = 1221640230
0100 1000 1101 0000 1100 0000 0010 0110 >>16 = 0100 1000 1101 0000
0100 1000 1101 0000 & 1111 1111(0xff)= 1101 0000 = 208
同理进行第二级目录的时候,此时的区别是右移的操作变为了右移8位,
blockId = 1221640230
0100 1000 1101 0000 1100 0000 0010 0110 >>8 = 0100 1000 1101 0000 1100 0000
0100 1000 1101 0000 1100 0000 & 1111 1111(0xff) = 1100 0000 = 192
我们可以看到,第二级目录就是192,和上述的实际目录完全匹配。
为了减少du的性能问题,社区在新的版本中进行了目录数的减少,一个直接的改动是将256x256的目录数改变为了32x32,总目录数从65k降到了1024。很明显,这将大大减少目录数的访问。这个其实是涉及到DN的Layout升级的问题了,HDFS采用的办法很简单,将时与之计算的16进制数从0xff变为了0x1f,相当于这里少包含了3个位数的计算,于是实现了在单目录层级8倍的降维。
新的转换方法如此,
/**
* Get the directory where a finalized block with this ID should be stored.
* Do not attempt to create the directory.
* @param root the root directory where finalized blocks are stored
* @param blockId
* @return
*/
public static File idToBlockDir(File root, long blockId) {
int d1 = (int) ((blockId >> 16) & 0x1F);
int d2 = (int) ((blockId >> 8) & 0x1F);
String path = DataStorage.BLOCK_SUBDIR_PREFIX + d1 + SEP +
DataStorage.BLOCK_SUBDIR_PREFIX + d2;
return new File(root, path);
}
在新的转转换下模式下,上面的blockId的目录数将会变为如下:
blockId = 1221640230
subdir level1
0100 1000 1101 0000 & 1111 1111 = 1101 0000 = 208
0100 1000 1101 0000 & 0001 1111 = 0001 0000 = 16
sudir level2
0100 1000 1101 0000 1100 0000 & 1111 1111 = 1100 0000 = 192
0100 1000 1101 0000 1100 0000 & 0001 1111 = 0000 0000 = 0
DataNode Layout升级
DN目录层级从256x256变为32x32,是需要DN Layout升级改动的。社区在HDFS-8791中实现了相应的逻辑。在apply掉HDFS-8791之后,重启DN时,DN会进行一次自动的layout的更新。那么一个重要的问题来了,它是如何做新旧目录的compatible呢?主要原理过程如下:
1)rename当前current目录,到previous.tmp。
2)新建current目录,并且建立hardlink从previous.tmp到新current目录。
3)rename目录previous.tmp为previous目录。
这里hardlink的link关联模式图如下所示(图中blockId只是举例而已):
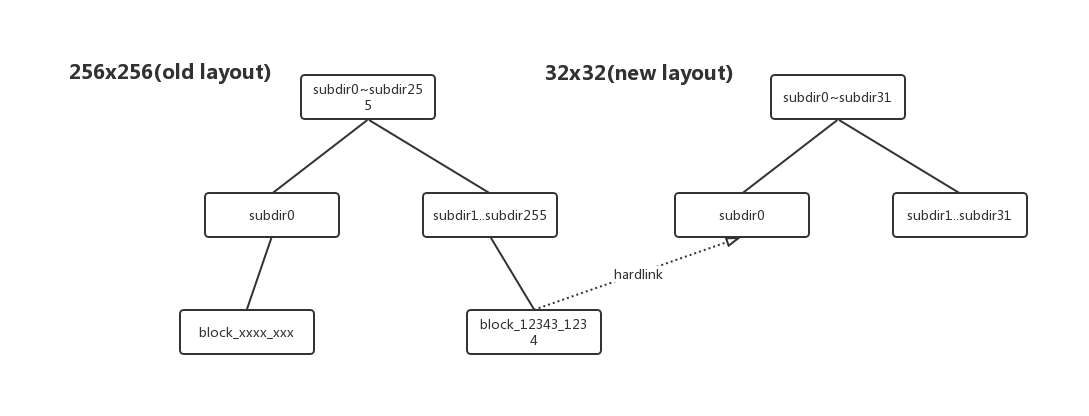
上述阶段其实是DN的Upgrade过程,等待真正执行了finalize操作之后,上面的previous才会被真正清除。DN的finalize的操作行为受NN控制,NN收到admin的finalize命令后,通过心跳的形式将finalize命令下发到下面的所有的DN中。因为这里只会涉及到DN的Upgrade,在NN中执行finailze命令只是为了下发命令到DN内,对NN来说无实际影响。
有Upgrade的情况,就会存在Rollback的情况。不过比较不方便的是,目前DN的layout无法支持一键式的rollback行为,只能通过手动启动DN带上rollback参数的方式来执行。在Rollback过程中,Upgrad过程中的previous目录会重新rename为current目录。另外还有其它局部目录的更新。Rollback, Upgrade,Finalize3个阶段的过程如下图所示:
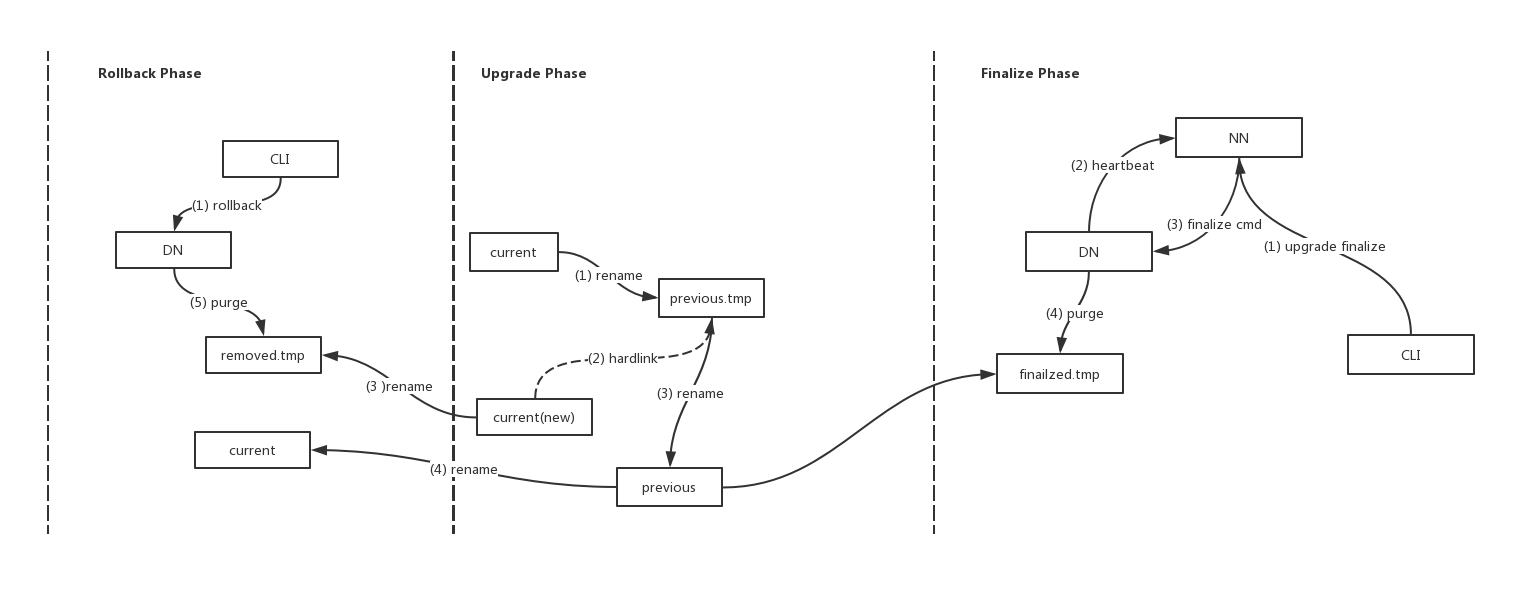
注意,上述DN Layout的升级并不依赖于大版本的升级,也不会有实际物理数据的move操作。DN Layout从256x256到32x32将会带来不小的du性能提升。
引用
[1].https://issues.apache.org/jira/browse/HDFS-8791
[2].http://www.science.unitn.it/~fiorella/guidelinux/tlk/node110.html
[3].http://www.science.unitn.it/~fiorella/guidelinux/tlk/node111.html