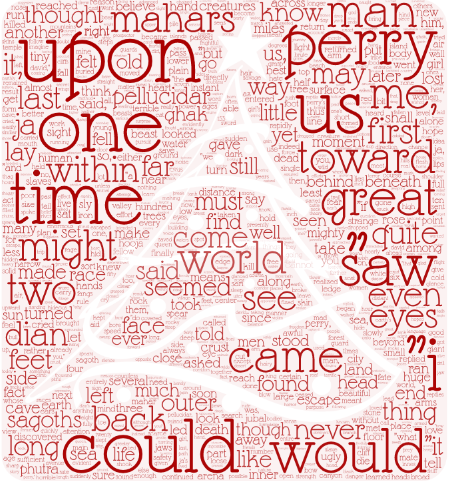本次作业在要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
1.列表,元组,字典,集合分别如何增删改查及遍历。
(1)列表
① 增加 & 修改
list = ['Google', 'Bob', 'Tray', 2000]; list1 = [1,2,3,4,5]; #在列表末尾添加 list.append('Cady'); print ( list); #在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) list.extend(list1); print ( list); #将对象插入列表 list.insert(1,'molly'); print ( list); #修改列表中的第一个元素的值 list[0]='python'; print ( list);
② 删除
list = ['Google', 'Bob', 'Tray', 2000]; #删除列表中的第二个元素 del list[1]; print ("列表现在为 : ", list) #移除列表中的一个元素,默认最后一个元素 list.pop() print ("列表现在为 : ", list) list.pop(1) print ("列表现在为 : ", list)
③ 查找
list = ['Google', 'Bob', 'Tray', 2000]; #从列表中找出某个值第一个匹配项的索引位置 x = list.index('Bob'); print(x); #使用下标索引来访问列表中的值 y = list[0]; print(y); z = list[1:3]; print(z);
④ 遍历
遍历指通过循环语句一次访问列表中的各元素的值,元组同理。列表可用到内置函数len() 、max()和min(),元组的内置函数同列表一样。
list1 = ['Google', 'Bob', 'Tray', 123,'Cady']; list2 = [2,8,9,7,4,3]; # 计算列表元素个数 print(len(list1)); # 返回列表中元素最大值 print(max(list2)); # 返回列表中元素最小值 print(min(list2));
(2)元组
① 增加 & 修改
注:元组中的元素是不允许修改的,但是我们可以对元组进行连接组合
tup1 = ('Google', 'Bob', 'Tray', 123,'Cady'); tup2 = (1,2,3,4,5,6,7); #元组在连接 tup3 = tup1 + tup2; print (tup3);
② 删除
注:元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组
tup1 = (1,2,3,4,5,6,7); print (tup1); #删除整个元组tup1 del tup1;
③ 查找
tup1 = ('Google', 'Bob', 'Tray', 123,'Cady'); #元组可以使用下标索引来查找元组中的值 print ("tup1[0]: ", tup1[0]); print ("tup1[1:5]: ", tup1[1:5]);
(3)字典
① 增加 & 修改
dict = {'Alice': 95, 'Beth': 81, 'Cecil': 76,'Cady':87,'Bob':79};
# 更新 Age
dict['Beth'] = 65;
print(dict);
# 添加信息
dict['Baby'] = 67;
print(dict);
② 删除
dict = {'Alice': 95, 'Beth': 81, 'Cecil': 76,'Cady':87,'Bob':79,'Molly':86};
# 删除键 'Alice'
del dict['Alice'];
print(dict);
# 清空字典
dict.clear();
print(dict);
# 删除字典,使用下面语句后整个字典被删除
del dict
③ 查找
dict = {'Alice': 95, 'Beth': 81, 'Cecil': 76,'Cady':87,'Bob':79,'Molly':86};
#通过使用相应的键来查找
print ( dict['Molly']);
(4)集合
① 增加 & 修改
set = {'Alice', 'Beth', 'Cecil','Cady','Bob','Molly'};
#添加某个元素到集合set中
set.add('Youth');
print(set);
#添加元素到集合set中,添加的参数可以是列表,元组,字典等
set.update({123,456});
print(set);
② 删除
set = {'Alice', 'Beth', 'Cecil','Cady','Bob','Molly'};
basket = {'orange', 'banana', 'pear', 'apple'};
#1.删除元素,如果元素不存在,则会发生错误
set.remove('Alice');
print(set);
#2.删除元素,如果元素不存在,不会发生错误
set.discard('Beth');
print(set);
#3.随机删除集合中的一个元素
x = basket.pop();
print("删除的元素是:",x);
print(basket);
③ 集合的运算
basket1 = {'strawberry','apple','grape','chestnut','orange','mango'};
basket2 = {'orange', 'banana', 'pear', 'apple'};
x = basket1 - basket2;
print(x);
y = basket1 | basket2;
print(y);
z = basket1 & basket2;
print(z);
2.总结列表,元组,字典,集合的联系与区别。
| 列表 | 元组 | 字典 | 集合 | |
| 英文 | list | tuple | dict | set |
| 表示 | [ ‘元素一’, ‘元素二’],如:[1,’a’,3] | ( ‘元素一’,’元素二’ ),如:(1,’a’,3) | {key1:value,key2:value2},如:{’a’:1,’b’:2,’c’:3} | {key1,key2,key3},如:{1,2,3} |
| 有无顺序 | 有序 | 有序 | 无序 | 无序 |
| 可否变化 | 可变 | 不可变,元组中的元素不可修改、不可删除 | 可变 | 可变 |
| 是否重复 | 是 | 是 | 是 | 否 |
| 存储方式 | 值 | 值 | 键-值对 | 集合中的元素唯一,不能索引 |
| 查找方式 |
① 找出某个值第一个匹配项的索引位置,如:list.index(‘a’) ② 使用下标索引,如:list[1] |
使用下标索引,如:tuple[1] | 通过使用相应的键来查找,如:dict[‘a’] | 通过判断元素是否在集合内,如:1 in dict |
3.词频统计
(1)准备工作
下载一长篇小说,存成utf-8编码的文本文件 file。我下载的是一篇英文科幻小说At the Earth's Core,如下图所示。
(2)词频统计源代码
1 # 导入nltk库获得英文的停用词 2 import nltk 3 nltk.download("stopwords") 4 from nltk.corpus import stopwords 5 stops = stopwords.words('english'); 6 print(stops); 7 set2 = set(stops); # 将停用词转化为集合 8 9 # 读取文件并对其进行预处理 10 def getArticle(): 11 sep = ".-,:?;_'—-'"; 12 f = open("At the Earth's Core.txt", 'r', encoding='utf8'); 13 article = f.read().lower(); # 将文章全部转化为小写 14 for i in sep: 15 article = article.replace(i, ' '); 16 return article; 17 18 # 指定以空格作为分隔符对字符串进行切片 19 list1 = getArticle().split(); 20 print(list1); 21 22 # 将列表转化为集合 23 set1 = set(list1); 24 print(set1); 25 26 set1 = set1 - set2; # 去停用词 27 print(set1); 28 dict = {}; 29 for word in set1: # 计算单词出现的次数 30 dict[word] = list1.count(word); 31 print(dict); 32 33 print(dict.items()); 34 words = list(dict.items()); # 以列表返回可遍历的(键, 值)元组数组 35 36 words.sort(key = lambda x:x[1],reverse = True); # 根据单词出现的次数进行排名 37 print(words); 38 39 print(words[0:21]); # 输出TOP(20) 40 41 # 生成一个名为article.csv的词频统计结果 42 import pandas as pd 43 pd.DataFrame(data=words).to_csv('article.csv',encoding='utf-8');
(3)运行结果

(4)可视化:词云
我根据上面的运行结果生成了一个名叫article.csv文件,文件里面存的是文章词频统计的结果,根据文件结果我利用了WordArt工具做了一个可视化词云,如下图所示。