Tom Mitchell, 1996: Machine learning is the study of how to make programs improve their performance on certain tasks from (own) experience.机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。这里面性能标准可以是速度、准确率,而以往的经验则就是数据。
一般机器学习的问题分为两大类,但是不论是分类还是回归,我们最终学习的都是一个函数:
回归问题:最后结果是一个数值

分类问题:最后结果是一个类别
假定我已有数据集制图如下:
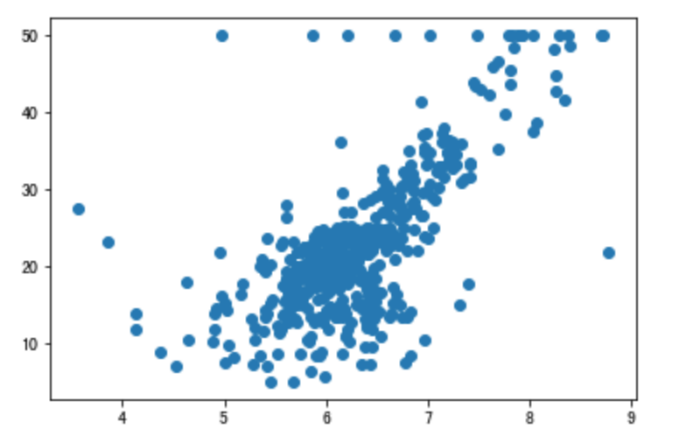
按我们回归问题的思路,现在我需要找到一个函数来拟合上面我原有的数据集,以方便后面预测新值。
那么我们如何找到最优函数?在这个函数由于x是给定的,那么其实我们需要调整的就是k与b的值。
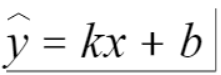
既然有调整那么肯定是有评测指标的,如何验证我的k、b是好是坏?我们可以计算我们以当前k、b计算出的值与数据集原真实值的误差是多少,然后取平均值,当这个误差最小时,则说明我们的k、b已经取到最优了。
在这里我们取的是预测值与真实值的误差平方,也可以用其他的方式,比如计算绝对值。

那么如何快速计算这个loss值呢?我们就需要要用到梯度下降方法。
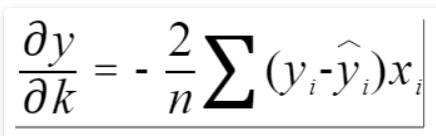
我们按照这个思路以自带数据集波士顿放假预测为例,以房间数设置为x,房间售价则是y实现代码如下:
1 #!/usr/bin/env python 2 # __author__ = '北方姆Q' 3 # -*- coding: utf-8 -*- 4 5 6 import random 7 from sklearn.datasets import load_boston 8 9 10 data_set = load_boston() 11 x, y = data_set['data'], data_set['target'] 12 X_rm = x[:, 5] 13 14 15 def price(rm, k, b): 16 return k * rm + b 17 18 19 def loss(y, y_hat): 20 """ 21 绝对值平均 22 :param y: 23 :param y_hat: 24 :return: 25 """ 26 return sum((y_i - y_hat_i)**2 for y_i, y_hat_i in zip(list(y), list(y_hat)))/len(list(y)) 27 28 29 def partial_derivative_k(x, y, y_hat): 30 """ 31 k的导数 32 :param x: 33 :param y: 34 :param y_hat: 35 :return: 36 """ 37 n = len(y) 38 gradient = 0 39 for x_i, y_i, y_hat_i in zip(list(x), list(y), list(y_hat)): 40 gradient += (y_i-y_hat_i) * x_i 41 return -2 * gradient / n 42 43 44 def partial_derivative_b(y, y_hat): 45 """ 46 b的导数 47 :param y: 48 :param y_hat: 49 :return: 50 """ 51 n = len(y) 52 gradient = 0 53 for y_i, y_hat_i in zip(list(y), list(y_hat)): 54 gradient += (y_i-y_hat_i) 55 return -2 * gradient / n 56 57 58 def boston_loss(): 59 k = random.random() * 200 - 100 60 b = random.random() * 200 - 100 61 62 learning_rate = 1e-3 63 64 iteration_num = 1000000 65 losses = [] 66 for i in range(iteration_num): 67 price_use_current_parameters = [price(r, k, b) for r in X_rm] 68 69 current_loss = loss(y, price_use_current_parameters) 70 losses.append(current_loss) 71 print("Iteration {}, the loss is {}, parameters k is {} and b is {}".format(i, current_loss, k, b)) 72 73 k_gradient = partial_derivative_k(X_rm, y, price_use_current_parameters) 74 b_gradient = partial_derivative_b(y, price_use_current_parameters) 75 76 k = k + (-1 * k_gradient) * learning_rate 77 b = b + (-1 * b_gradient) * learning_rate 78 best_k = k 79 best_b = b 80 81 boston_loss()