(一)基本光照
光照 —— 即根据场景中光源的分布及物体的形状、朝向等信息,为物体"涂"上阴影、高光等一系列增加真实感的色彩。
为了给物体着色,我们需要一个"模型"—— 根据光源的情况和当前表面的参数,得到一个这个表面该有的颜色。
这么说可能不太好理解,那么来看一个最基本的光照模型:Phong光照模型。这种光照模型更像是一种"经验模型",由于它在复杂场景中的真实性远不足,在现在已经鲜有人使用,但是它仍然是一种非常重要的计算方法。(而且应该仍是各大学图形学课程的必修内容)
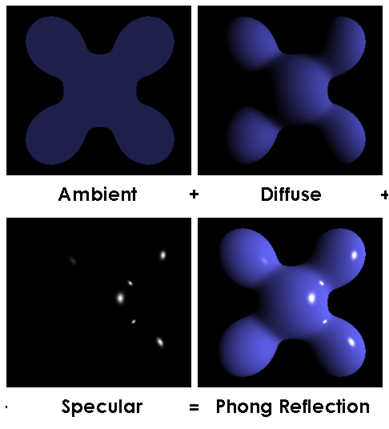
我们知道,我们能看见一个自身不发光的物体是因为它反射了从其他地方的光。Phong光照模型把不发光物体所反射的光分成三种分别计算(如下图):
下文中"表面"的解释:
类似"dS"的感觉。把一个曲面分成一个个一个个细小的平面(多边形),这些小平面足够小,以致于在有限分辨率的屏幕前我们分辨不出它们。而它作为一个平面,自然有一个法向量代表它的朝向,也有它中心点的位置及一系列数据。而着色就是为这一个个小平面分别决定它们该有的颜色,最后组合成具有真实感的整个物体。
1) 环境光
在一个场景中,确定的光源并不是光唯一的来源。正如上面所讲,不发光的物体会反射光源所发出的光,而这种反射大多是漫反射,这就导致了场景中有着无数"乱七八糟""横冲直撞"的漫反射光。如果考虑这些光的存在,以当时计算机的计算能力,最顶级的计算机渲染出一帧(为了完成实时渲染,至少要在1/20秒内完成)可能都要花出比一天还多的运算时间;为了大幅度简化计算,Phong光照模型把这些光视为各个方向上强度都相等的光,导致物体的各个表面都具有一个相同的,比较暗的"底色"。
2) 漫反射
它模拟了物体表面对光源发出的光产生的漫反射。它根据物体表面的朝向与光源相对于这个表面的位置给表面染上不同的颜色。当光源相对于该表面的位置与该表面的法向量夹角比较小时 —— 此时这个面朝向光源 —— 这个面就会被赋予一个比较亮的颜色。反之,这个面就会被赋予阴影的颜色。
3) 高光
它模拟了物体表面"规则"的部分,这部分遵循镜面反射原则,进而可以在物体上产生光斑。由表面位置和光源位置可以确定出一道入射光;以这个平面的法线为反射平面的法线,可以求出对应的出射光。当这个出射光的朝向与观察点相对于表面的朝向非常接近时,就给这个表面一个非常亮的颜色,进而在整个物体表面产生高光反射。
Phong模型把上述三种方式产生的颜色值按一定比例混合起来,就产生了最后的图像。具体的计算方式限于篇幅原因不再叙述,这方面的网上应该有一大堆。大概是这样的:使用夹角的余弦值来当作“强度”,并对高光部分的“强度”进行乘方来控制光斑大小。最后将这几种颜色混合起来,就得到了最后的图像。
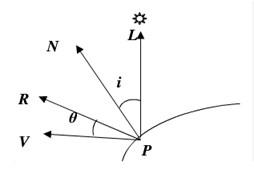
(Phong光照模型的参考图。P:小平面;V:观察点;L:光源;N:法线;R:出射光)
(二)基本阴影
虽然上面的这种光照模型十分好用且经典,但还存在着非常多非常多的不足之处。其中比较大的是它无法体现物体之间或是物体自身对自身遮挡产生的阴影。为了解决这个问题,人们提出了一种称为shadowMap的技术。
在此之前,需要先说明一下深度缓冲区的概念。计算机在渲染图像时,需要保证离摄像机比较远的物体被离摄像机较近的物体遮挡。但是很明显,计算机不能在渲染之前先对物体进行一次离摄像机距离的排序再渲染,这是即耗时又容易“穿帮”的作法。为了解决这个问题,深度缓冲区的概念产生了。一般情况下,计算机在渲染图像的过程中会同时产生一张深度图,这是一张只有一个通道的图像,代表了物体距离摄像机的距离。

上图是一张典型的深度图。越亮的地方代表离摄像机的距离越近,越暗的地方代表离摄像机的距离越远。有了这张图,在渲染物体时,先把即将输出的像素的深度值(深度图中这个像素的颜色)与当前深度缓冲区(当前深度图)中的像素颜色进行比较,如果这里已经有一个比要渲染的像素还要离摄像机近的像素存在,就抛弃掉将要渲染的像素;反之就覆盖掉原来的。这就是被称为“深度测试”(depth test)的操作。
有了这张图,我们其实不仅能处理遮挡,还能够渲染阴影 —— 阴影就是从光源的位置看来,各个物体之间的遮挡关系;被遮挡的地方涂上阴影,没被遮挡的地方该咋样咋样。也就是说,我们需要让摄像机的位置朝向等与光源一致,然后渲染一张图像,取出它的深度图(事实上,我们只需要深度数据,所以我们可以只渲染深度来节约开销)。然后把摄像机移回原来的位置,再进行渲染。在渲染时,对渲染的每个像素,找到它在光源处那张深度图中的位置,并计算出它离光源的距离;然后把光源深度图中的数据和它离光源的距离数据比较,就可以判断出它是不是应该被涂上阴影了。
来看一组wikipedia上的连环画(误):
 这是我们要渲染的场景,没有阴影。
这是我们要渲染的场景,没有阴影。
 切换到光源视点,渲染了一张图(由于是平行光,所以是正交投影)
切换到光源视点,渲染了一张图(由于是平行光,所以是正交投影)
 得到的深度信息
得到的深度信息
 “假想的”把这张深度图投射到实际的物体表面的状况
“假想的”把这张深度图投射到实际的物体表面的状况
 进行深度测试(需要涂上阴影的地方用白色标出)
进行深度测试(需要涂上阴影的地方用白色标出)
 最后贴上阴影的图像。
最后贴上阴影的图像。
大概就是这么一个过程。但是梦想是美好的,现实可未必如此;为了让世界有最基本的阴影,还有一些需要解决的问题。再来看一下刚才的过程:
我们需要让摄像机的位置朝向等与光源一致,然后渲染一张图像,取出它的深度图(事实上,我们只需要深度数据,所以我们可以只渲染深度来节约开销)[我们该如何渲染一张图像,不显示它,并且在之后的渲染中使用它?如何获取到它的深度信息?]。然后把摄像机移回原来的位置,再进行渲染。在渲染时,对渲染的每个像素,找到它在光源处那张深度图中的位置[该如何找?],并计算出它离光源的距离[怎么算?];然后把光源深度图中的数据和它离光源的距离数据比较[怎么比较?如何把颜色数据转换为距离?],就可以判断出它是不是应该被涂上阴影了。
好在这些问题都没有那么困难。一个个来:
1)我们该如何渲染一张图像,不显示它,并且在之后的渲染中使用它? —— 渲染到纹理(Render To Texture)
在渲染过程中,我们可以使用被称为“纹理”的图像数据来帮助我们决定每个像素的颜色,比如每个模型的贴图,法线贴图,乱七八糟各种贴图之类的。同样,我们也有办法在程序运行过程中动态的创建、修改它们。这里说起来太杂,而且网上也有许多现成的信息和教程(关键词:“Render to texture”,“RTT”,“渲染到纹理”)。对于OGL/DX,可以使用诸如FrameBuffer,RenderTarget之类的东西;Unity可以用Unity提供的RenderTexture,并在场景中创建一个摄像机设置一下就行了。
2)如何获取到它的深度信息?
首先,在渲染时告诉计算机“你需要给我一张深度图”,然后去用就好了。
3)该如何找到某像素在光源深度图中的位置?
我们需要对这个像素的位置进行变换。
首先,在vertex shader中向后传一个世界坐标信息,这样会方便之后的计算;并且要知道光源的变换矩阵(一个4x4的矩阵,代表了光源相对于世界空间的位置、朝向、透视(对于平行光来讲是正交)的信息)
然后在fragment shader中取出这个坐标(就是这个像素在世界空间中的位置),把这个坐标矢量右乘矩阵,得到在光源“屏幕空间”中的坐标;这个坐标的x,y值就是对应于深度图中的位置。
P.S. 对于平行光来讲,由于没有透视的问题,所以也可以用光源的位置加上光源局部坐标系下的至少两个正交基,来确定相对于光源的位置。
4)怎么算离光源的距离?如何把颜色数据转换为距离?
如何计算点到光源的距离这个问题没什么好说的,光源也是一个点,两个坐标矢量单纯的相减即可。
接下来就是如何把颜色数据转换为距离。
首先,对于深度图中的颜色,我们有办法用一个0.0~1.0之间的浮点数来代表它。通常直接读取图像数据就可以拿到这个浮点数;
然后我们需要把这个浮点数转换为距离。把距离转换为这个浮点数会相对好说一点,想要反着转换回去只需要反着算就行。把这个距离转换为0~1的浮点数事实上就是向深度缓冲区里写入颜色信息的过程,这个过程大致如下:
先得到当前摄像机“屏幕空间”中的坐标pos(就是上一步中已经算好的坐标“深度图中的位置”)。pos.z / pos.w的结果就是最终的颜色值。
对于正交摄像机来说,w是一个常数。此时深度图中的颜色就是把0~1的浮点数线性地 “涂在” 近剪裁平面到远剪裁平面之间。
然后我们就能算出这个点的“深度值”(一个0~1的浮点数),把它和光源深度图中的颜色比较,得到这个点应不应该被覆盖上阴影,进行后续的操作。
附一张极丑无比的图,是我弄了棵树然后强行丢了个shadowmap上去的结果:(
(真***丑啊...没眼看了23333)
这种shadowmapping的方法十分基础,也有着诸多的缺陷,例如分辨率不够、没法弄软阴影之类的乱七八糟的不足。由上面这种最基本的方法衍生出了许许多多新的计算阴影的方式,诸如CSM等各种比较不错的阴影处理算法,但它们都是上述方法的衍生产物。有时间的话再说吧(懒
P.S. 关于上面把离光源的位置转换为0~1的浮点数的逆过程称为“从深度重建位置信息”(或这一类的称呼)。由于透视投影下这个变换不是线性的,离摄像机较远的地方分辨率十分低下导致各种问题,也有一些比较好的改进算法来进行这个变换。还请善用搜索w~