0、存储引擎
MyISAM: 拥有较高的插入,查询速度,但不支持事务
InnoDB :5.5版本后Mysql的默认数据库,事务型数据库的首选引擎,支持ACID事务,支持行级锁定
BDB: 源自Berkeley DB,事务型数据库的另一种选择,支持COMMIT和ROLLBACK等其他事务特性
Memory :所有数据置于内存的存储引擎,拥有极高的插入,更新和查询效率。但是会占用和数据量成正比的内存空间。并且其内容会在Mysql重新启动时丢失
Merge :将一定数量的MyISAM表联合而成一个整体,在超大规模数据存储时很有用
Archive :非常适合存储大量的独立的,作为历史记录的数据。因为它们不经常被读取。Archive拥有高效的插入速度,但其对查询的支持相对较差
Federated: 将不同的Mysql服务器联合起来,逻辑上组成一个完整的数据库。非常适合分布式应用
Cluster/NDB :高冗余的存储引擎,用多台数据机器联合提供服务以提高整体性能和安全性。适合数据量大,安全和性能要求高的应用
CSV: 逻辑上由逗号分割数据的存储引擎。它会在数据库子目录里为每个数据表创建一个.CSV文件。这是一种普通文本文件,每个数据行占用一个文本行。CSV存储引擎不支持索引。
BlackHole :黑洞引擎,写入的任何数据都会消失,一般用于记录binlog做复制的中继
另外,Mysql的存储引擎接口定义良好。有兴趣的开发者通过阅读文档编写自己的存储引擎。
1、innodb存储引擎
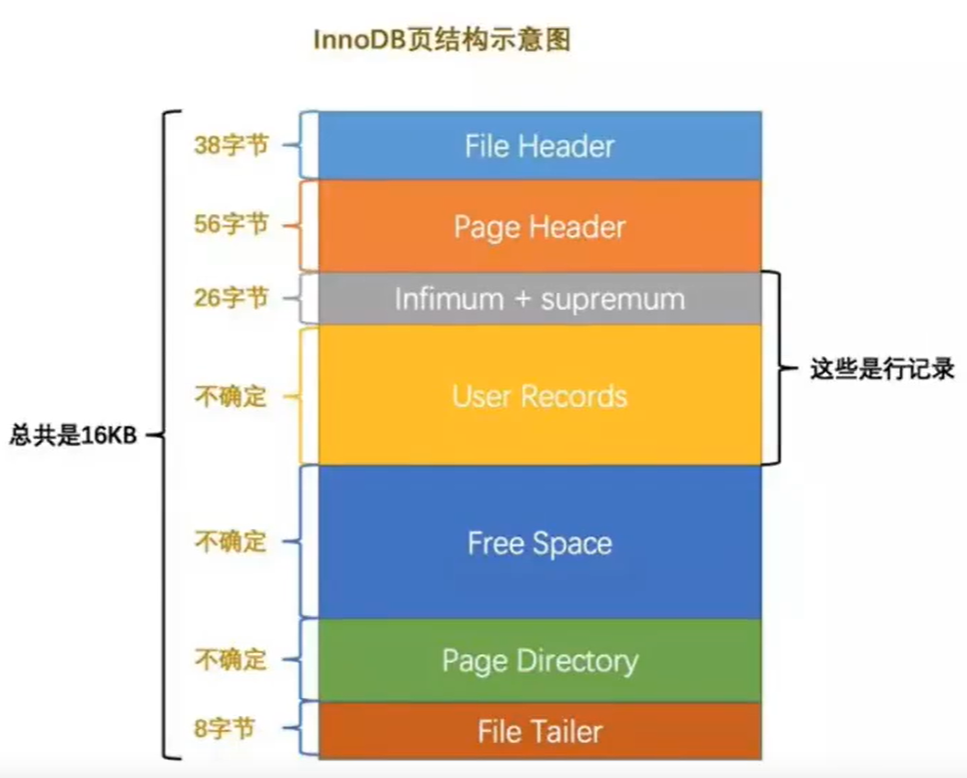
show global status like 'innodb_page_size' // 每页大小
mysq一个页大小为16K,当然这个大小是可以通过修改配置文件来改变的。
当我们新建一个表的时候表中用户记录部分(user records)部分是空的,在我们插入一条记录后会被记录到其中,直到插入满时会把记录信息刷入到下一个页中,循环往复
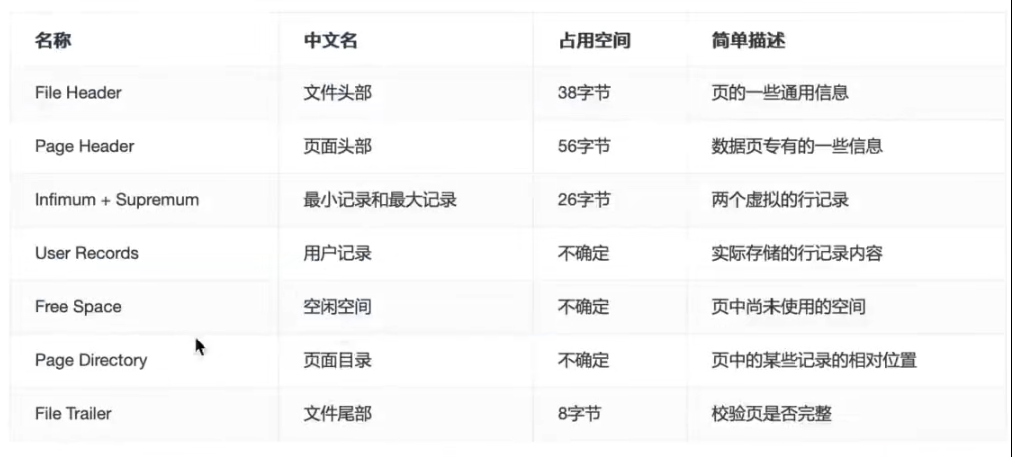
2、innodb行
mysql有4种存储格式:1)Compact 2) Redundant (5.0版本以前用,已废弃) 3) Dynamic (mysql5.7默认格式) 4) Compressed。 这是compact行格式数据存储结构:
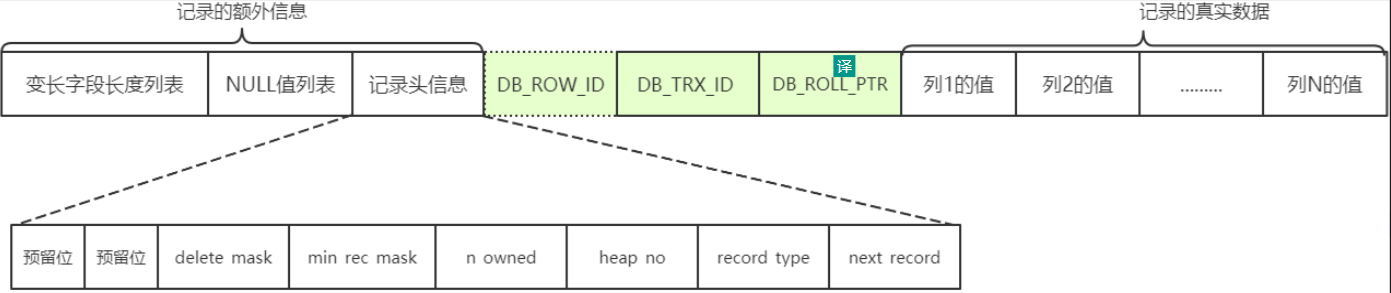
DB_ROW_ID(row_id) 如果表中没有显式定义主键列,mysql会默认生成一个row_id作为隐式主键,且row_id是全局概念,每一次有一行新数据insert,都会获取Max Row ID再加1就形成了一个新的row_id
DB_TRX_ID 事务有关,跟回滚指针有关,6个字节
DB_ROLL_PTR 事务有关,跟回滚指针有关, 7个字节
delete mask : 标记为是否被delete语句commit,也就是mysql不会真正物理删除一行记录,在页面上重新组装一个新链表,称为垃圾链表,如果垃圾链表占用空间可重用的话就会重用
3、溢出页
mysql规定每一页(可存放16384字节)必须至少存放 2 条数据,每一行除了存储真实数据之外,还会存储行的额外信息(比如索引信息),大概132个字节,另外:变长字段长度列表、NULL值列表、记录头信息、 这一堆还要花27个字节,也就是 132 + 2 * ( 27 + n) < 16384,所以这样会造成溢出页。另外,mysql对于一个varchar列最多可以定义为65535个字节大小,但是当一个列比如是varchar(40000),会超出mysql对于一页的磁盘存储大小16KB * 1024 = 16384 > 40000 个字节,这个就需要分页了,因为单页数据溢出了,这里也会产生了溢出页。
1)Compact和Redundant对于溢出的处理:mysql会存储768个真实数据的字节,并且用20个字节存储把其他数据存放到哪些页中去。
2)Dynamic和Compressed对于溢出的处理:干脆连768个字节也不存了,直接存储溢出页地址。好处就是当前页可以存更多的记录数
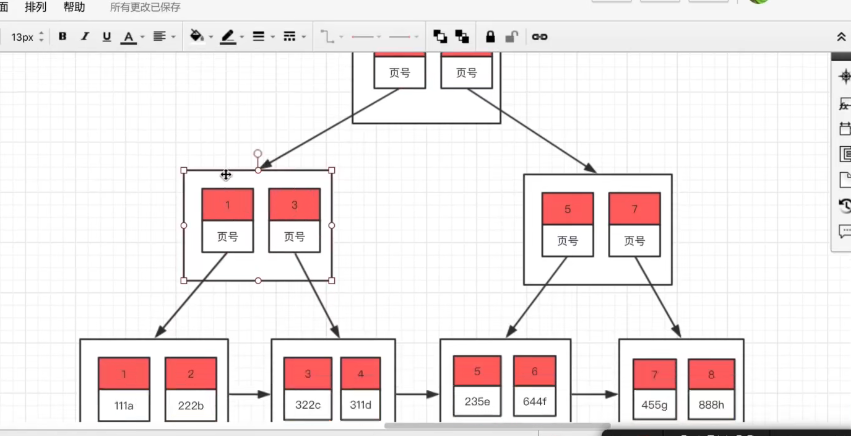
4、B+树
innodb存储引擎以B+树为基础,叶子节点包含最全的信息,并且有指向下一个节点的索引
5、多版本并发控制mvcc
基于mvcc(多版本并发控制)实现:可重复读、已提交读的事务控制,
mvcc 基于当前记录和undolog 获取数据事务链快照readview。
记录并维护系统当前活跃事务的ID(trx_id)(没有commit,当每个事务开启时,都会被分配一个ID, 这个ID是递增的,所以越新的事务,ID值越大),是系统中当前不应该被本事务看到的其他事务id列表。
Read View主要是用来做可见性判断的, 即当我们某个事务执行快照读的时候,对该记录创建一个Read View读视图,把它比作条件用来判断当前事务能够看到哪个版本的数据,既可能是当前最新的数据,也有可能是该行记录的undo log里面的某个版本的数据。
6、redolog、undolog、binlog
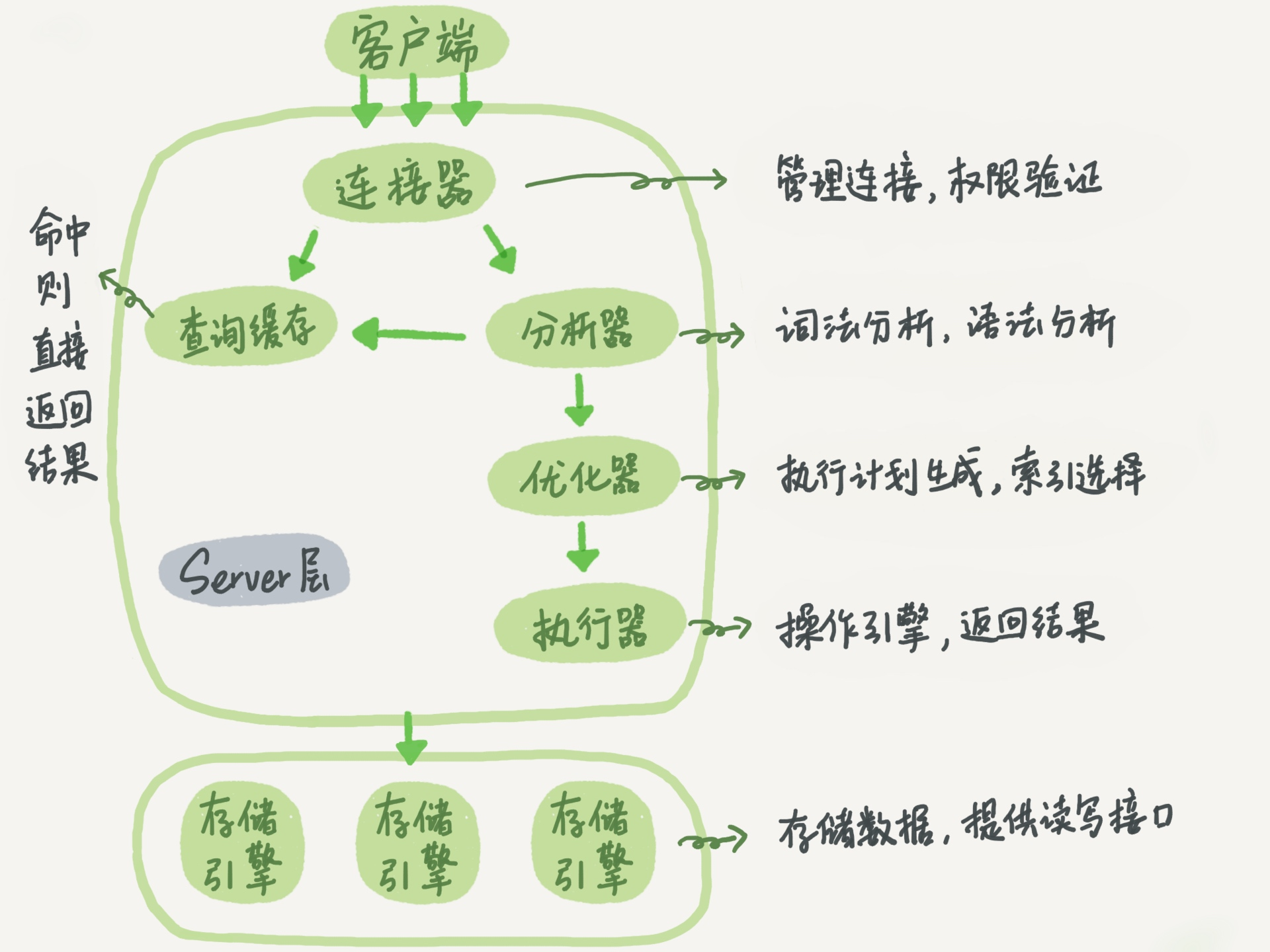
redo log是InnoDB存储引擎层的日志,又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。在实例和介质失败(media failure)时,redo log文件就能派上用场,如数据库掉电,InnoDB存储引擎会使用redo log恢复到掉电前的时刻,以此来保证数据的完整性。
binlog是属于MySQL Server层面的,又称为归档日志,属于逻辑日志,是以二进制的形式记录的是这个语句的原始逻辑,依靠binlog是没有crash-safe能力的
undo log不是redo log的逆向过程,其实它们都算是用来恢复的日志:
1.redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
2.undo用来回滚行记录到某个版本。undo log一般是逻辑日志,根据每行记录进行记录
7、其他
设置隔离级别:
mysql> set session transaction isolation level read uncommitted;
查看隔离级别:
mysql> select @@tx_isolation;
已提交读:只会对查询出来的记录加锁。所以会产生幻读
重复读:会对索引范围记录加锁(不走索引对表加锁)。所以禁止了幻读产生