前言:
本文代码基于python3
Content:
1.python中的序列类分类
2. python序列中abc基类继承关系
3. 由list的extend等方法来看序列类的一些特定方法
4. list这种序列类的一大特点:切片。和如何实现可切片对象。到如何自定义一个序列类。
5. biset维护排序序列
6. 什么时候使用list
7.列表推导式、生成器表达式、字典推导式
1.python中的序列类分类
a.什么是python的序列类?
之前提到的魔法函数这种时候就很重要啦。满足序列类相关的协议就称为python里的序列类。python内置的序列类有dict、tuple、list等。
而我们自定义序列类的话,由于魔法函数的存在。序列的相关魔法方法允许我们自己创建的类拥有序列的特性,让其使用起来就像 python 的内置序列。
b.python按分类来看有哪些序列类?
- 容器序列:list,tuple,deque(可以放任意的类型的容器)
- 扁平序列:str,bytes,bytearray,array.array(可以使用 for循环遍历的)
- 可变序列:list,deque,bytearray,array
- 不可变:str,tuple,bytes
Python标准库提供了大量使用C来实现的序列类型,
从序列中的元素类型是否一致作为标准,包括容器序列(Container sequences,包括list、tuple、collections.deque等)和固定序列(Flat sequences,包括str、bytes、bytearray、memoryview、array.array)等。
ps.容器序列中实际存放的元素是对其他任意对象的引用,而固定序列中存放是真正的是元素值,因此所有的元素必须是相同类型,并且只能是Python基本类型(字符、字节、数字等)的数据。
如果从序列中的元素是否能够被修改的标准来看,Python的序列类型又分为可变序列(Mutable sequences,包括list、bytearray、array.array、collections.deque、memoryview等)和不可变序列(Immutable sequences,包括tuple、str、bytes等)
c.序列常见操作
索引(index) 分片(slicing) 序列相加(拼接) 乘法(重复) 成员资格(in) 长度(len) max() min() 可以迭代sorted enumerate zip filter map
2. python序列中的abc继承关系
在python的collection模块中,有abc模块,和容器相关的抽象基类和数据结构都在其中。
那么abc模块中,具体有哪些类呢?

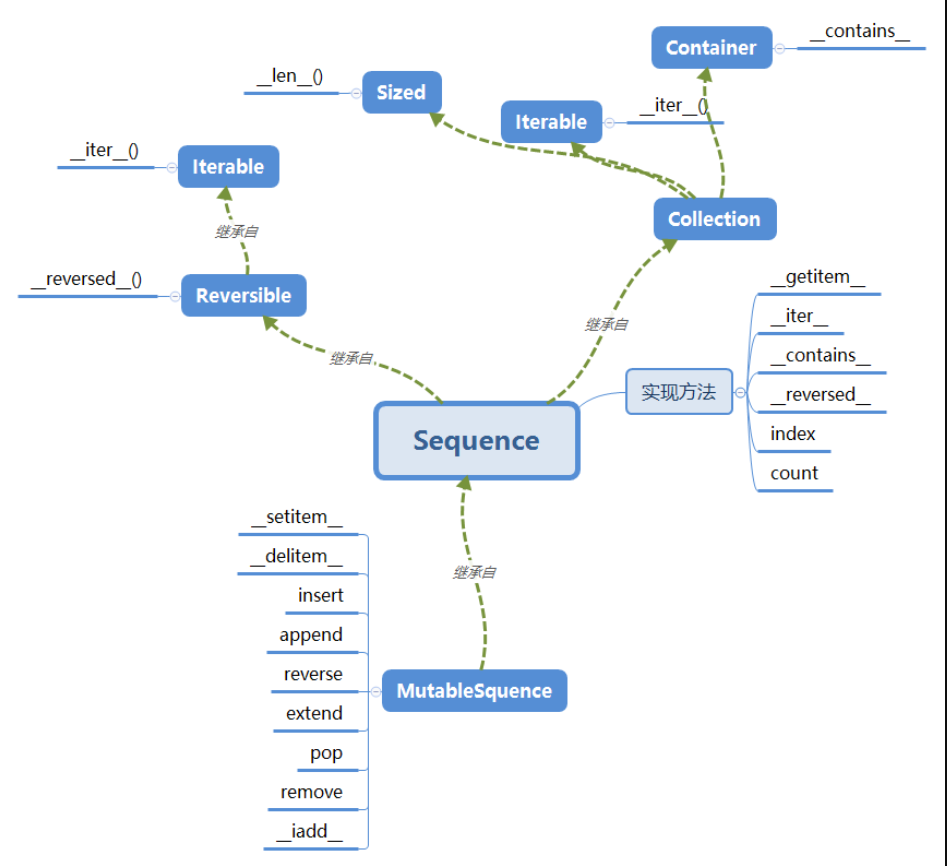
其中,Sequence就是不可变序列的方法集合的抽象基类,MutableSequence是集合了可变序列的方法和协议的抽象基类。
这些抽象类之间的关系:
a.可变序列(MutableSequence)从不可变序列(Sequence)那里继承了一些方法.
b.Sequence继承了collection,collection又继承了Sized、Container、Iterable
c.python的内置序类型并没有直接继承这些基类,但是这些基类定义了某种特性序列的方法和协议,了解这些基类间的继承关系能很好的帮助我们了解python的内置序列类型。
综上可得图:
3. 由list的extend等方法来看序列类的一些特定方法调用
对list序列进行添加操作一般有几种方法?
+、+=、extend、append

这里有几个好玩的地方:
a.+和+=的区别
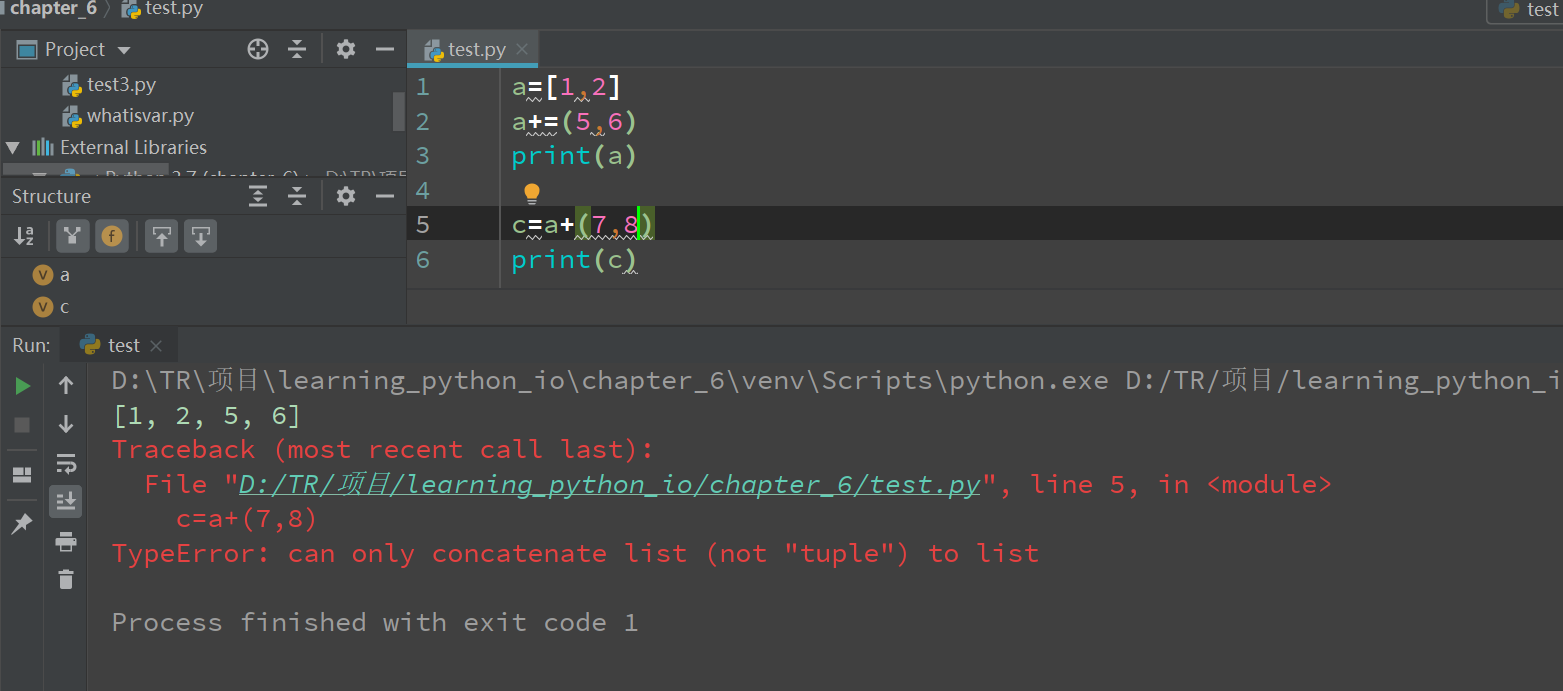
可以看到+=的对象可以是tuple,而+不可以。
实际上+=是调用了一个魔法函数 __iadd__实现的。使用+=的时候,实际上还是调用了extend方法。
extend传递的参数类型是可迭代类型,用for循环,它会遍历可迭代的类型,一个个加到列表里。
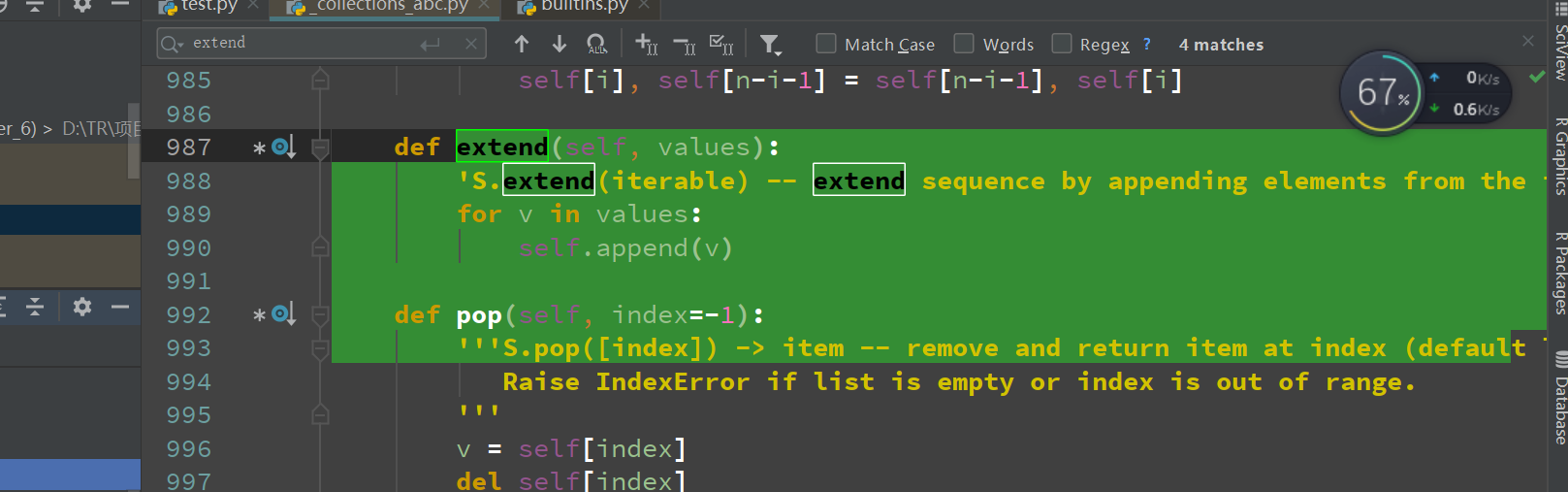
b.extend、append的区别
上面已经贴出了extend的实现,现在看append的实现:

很明显的一点,一个直接用insert把对象插入,一个遍历对象加入。
4. list这种序列类的一大特点:切片。和如何实现可切片对象。到如何自定义一个序列类。
a.python的切片的一些用法:
alist = [3,4,5,6,7,9,11,13,15,17] print(alist[::]) # 返回包含原列表中所有元素的新列表 print(alist[::-1]) # 返回原列表的逆序排列 print(alist[::2]) # 返回原列表的偶数位数据 print(alist[1::2]) # 获取奇数位置的数据 print(alist[3:6]) # 指定切片的开始和结束位置 print(alist[0:100]) # 切片位置大于列表长度时,从列表尾部截断 print(alist[100:]) # 切片开始位置大于列表长度时,返回空列表 alist[len(alist):]=[9] # 在列表尾部增加元素 print(alist) alist[:0] = [1,2] # 前面的0省略了,相当于是alist[0:0] = [1,2] print(alist) # 在列表的头部增加元素 alist[3:3] =[4] # 在列表中间插入元素 print(alist) alist[:3] = [1,2] # 相当于是alist[0:3] = [1,2] 替换列表元素 alist[3:] = [4,5,6] # 替换元素,结果按照两边的最短元素来决定. print(alist) alist[:3] = [] # 删除列表中前三个元素 del alist[:3] # 切片元素连续 del alist[::2] # 隔一个删除一个,切片元素不连续
b.自己实现一个可切片的序列类(包括可切片、可添加等内置序列类型有的操作)
自定义序列的相关魔法方法允许我们自己创建的类拥有序列的特性,让其使用起来就像 python 的内置序列(dict,tuple,list,string等)。
如果要实现这个功能,就要遵循 python 的相关的协议。所谓的协议就是一些约定内容。例如,如果要将一个类要实现迭代,可以实现__iter__() 或者 __getitem__()其中一个方法。
例子:自定义一个可以被切片的Group类:
import numbers class Group: # 支持切片操作 def __init__(self, group_name, company_name, staffs): self.group_name = group_name self.company_name = company_name self.staffs = staffs def __reversed__(self): self.staffs.reverse() # 因为object[] 和 object[::]都会调动这个方法 def __getitem__(self, item): # 取到class cls = type(self) #判断传递进来的是slice类型还是int类型,返回不同的类型和操作, if isinstance(item, slice): return cls(group_name=self.group_name, company_name=self.company_name, staffs=self.staffs[item]) if isinstance(item, numbers.Integral): return self.staffs[item] def __iter__(self): return iter(self.staffs) def __len__(self): return len(self.staffs) def __str__(self): return '组员有:{}'.format(self.staffs) def __contains__(self, item): if item in self.staffs: return True else: return False staffs = ['tangrong1', '123', '456', '789'] group = Group('A', 'TR', staffs=staffs) sub_group = group[:2] print(group) print(sub_group) if 'A' in group: # 这里会调用__contains__魔法函数 print('yes') for item in group: print(item) reversed(group) # 实际上是调用了__reversed__魔法函数 print(group)
输出正常。
一些相关的魔法函数:
-
__len__(self) 返回容器的长度。可变和不可变容器都要实现它,这是协议的一部分。
- __getitem__(self, key) 定义当某一项被访问时,使用self[key]所产生的行为。这也是可变容器和不可变容器协议的一部分。如果键的类型错误将产生TypeError;如果key没有合适的值则产生KeyError。
- __setitem__(self, key, value) 定义当一个条目被赋值时,使用self[key] = value所产生的行为。这也是可变容器协议的一部分。而且,在相应的情形下也会产生KeyError和TypeError。
-
__delitem__(self, key) 定义当某一项被删除时所产生的行为。(例如del self[key])。这是可变容器协议的一部分。当你使用一个无效的键时必须抛出适当的异常。
- __iter__(self) 返回一个迭代器,尤其是当内置的iter()方法被调用的时候,以及当使用for x in container:方式进行循环的时候。 迭代器要求实现next方法(python3.x中改为__next__),并且每次调用这个next方法的时候都能获得下一个元素,元素用尽时触发 StopIteration 异常。 而其实 for 循环的本质就是先调用对象的__iter__方法,再不断重复调用__iter__方法返回的对象的 next 方法,触发 StopIteration 异常时停止,并内部处理了这个异常,所以我们看不到异常的抛出。 这种关系就好像接口一样。
ps:
可迭代对象:对象实现了一个__iter__方法,这个方法负责返回一个迭代器。
迭代器:内部实现了next(python3.x为__next__)方法,真正负责迭代的实现。当迭代器内的元素用尽之后,任何的进一步调用都之后触发 StopIteration 异常,所以迭代器需要一个__iter__方法来返回自身。
所以大多数的迭代器本身就是可迭代对象。这使两者的差距进一步减少。
但是两者还是不同的,如果一个函数要求一个可迭代对象(iterable),而你传的迭代器(iterator)并没有实现__iter__方法,那么可能会出现错误。
不过一般会在一个类里同时实现这两种方法(即是可迭代对象又是迭代器),此时__iter__方法只要返回self就足够的了。当然也可以返回其它迭代器。
- __reversed__(self) 实现当reversed()被调用时的行为。应该返回序列反转后的版本。仅当序列是有序的时候实现它,例如列表或者元组。
- __contains__(self, item) 定义了调用in和not in来测试成员是否存在的时候所产生的行为。这个不是协议要求的内容,但是你可以根据自己的要求实现它。当__contains__没有被定义的时候,Python会迭代这个序列,并且当找到需要的值时会返回True。
- __missing__(self, key) 其在dict的子类中被使用。它定义了当一个不存在字典中的键被访问时所产生的行为。(例如,如果我有一个字典d,当"george"不是字典中的key时,使用了d["george"],此时d.__missing__("george")将会被调用)。
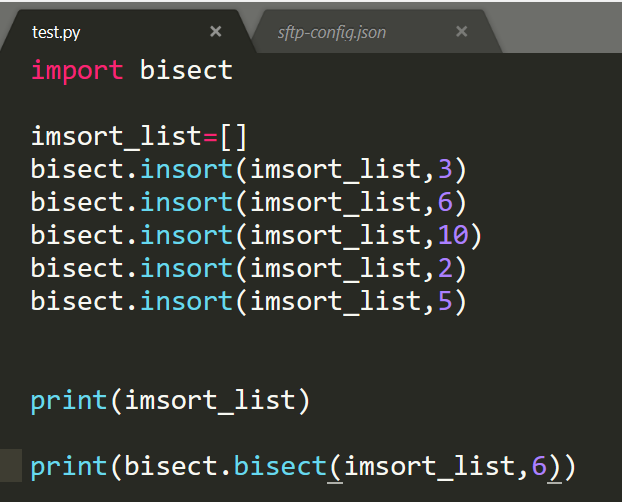
5. biset维护排序序列
a.biset模块干嘛的。模块里的insort干嘛的

6. 什么时候不应该使用list而用array
list和array的区别:
list是一个容器,装任何类型的数据。而array只能装指定类型的数据。
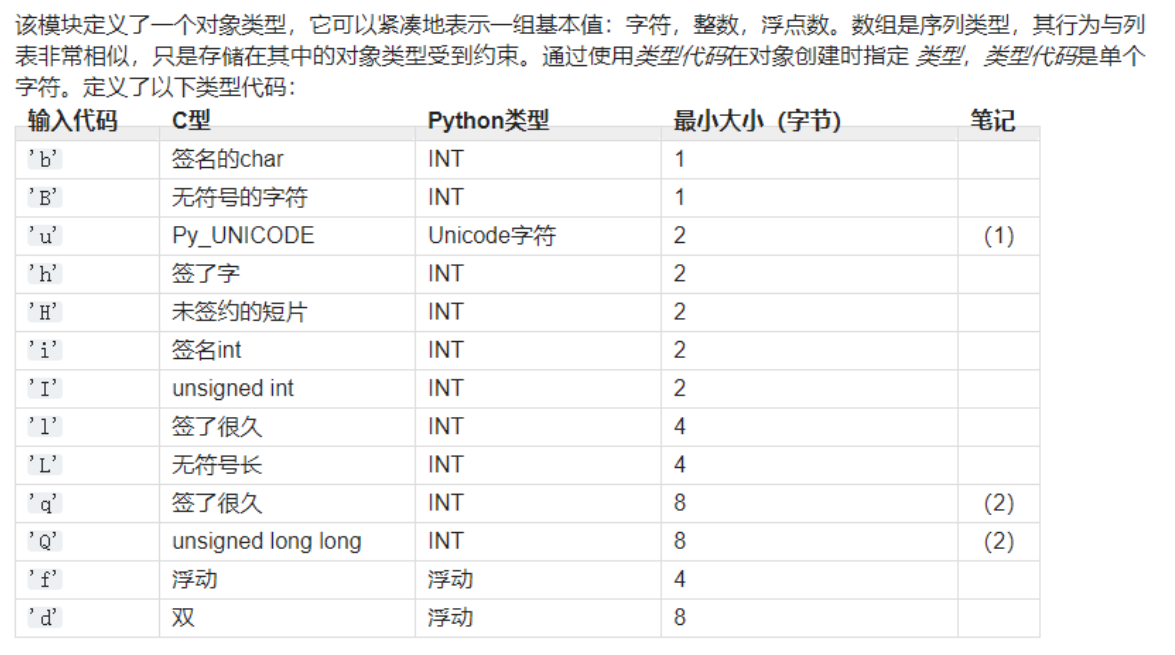
例子:用布隆过滤器的时候 就用了array。这时候array性能高list很多
7.列表推导式、生成器表达式、字典推导式
# 列表推导式 # 1.提取出1-20之间的奇数 odd_list = [] for i in range(21): if i % 2 == 1: odd_list.append(i) print(odd_list) # 使用列表推导式 odd_list = [x for x in range(21) if x % 2 == 1] print(odd_list) # 列表推导式的格式 # [on True for x in iteralbe 条件表达式(过滤)] # 逻辑复杂的情况 def handle_item(item): return item * item odd_list = [handle_item(x) for x in range(21) if x % 2 == 1] print(odd_list) # 列表表达式的前面可以是一个函数,也可以是一个函数,但是不能是匿名函数 # 生成器表达式,将列表推导式的[]改成(),就变成了生成器表达式 gen = (x for x in range(21) if x % 2 == 1) print(gen) # <generator object <genexpr> at 0x000001CF1B01C8E0> print(type(gen)) # <class 'generator'> for item in gen: print(item) # 字典推导式,颠倒key和value my_dict = {'bob1': 22, 'bob3': 23, 'bob4': 5} reversed_dict = {value: key for key, value in my_dict.items()} print(reversed_dict) # 集合推导式 set # 如何将一个字典的key全部放到一个集合当中. my_set = {key for key in my_dict.keys()} # 也可以使用 my_set = set(my_dict.keys()) print(type(my_set)) print(my_set)