20155228 2017-2018-1 《信息安全系统设计基础》第七周学习总结
教材学习内容总结
ISA抽象的作用
- 一个处理器支持的指令和指令的字节级编码称为它的指令
集体系结构(Instruction-Set Architecture, ISA)。不同的处理器“家族”,例如Intel IA32
和x86-64, IBM/Freescale Power和ARM处理器家族,都有不同的ISA。一个程序编译
成在一种机器上运行,就不能在另一种机器上运行。另外,同一个家族里也有很多不同型
号的处理器。 - ISA在编译器编写者和处理器设计人员之间提供了一个概念抽象层,编译器编
写者只需要知道允许哪些指令,以及它们是如何编码的;而处理器设计者必须建造出执行
这些指令的处理器。
ISA
程序员可见状态
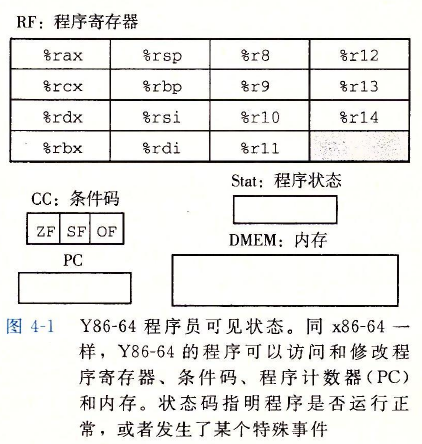
- Y86-64程序中的每条指令都会读取或修改处理器状态的某些部分。这
称为程序员可见状态,这里的“程序员”既可以是用汇编代码写程序的人,也可以是产生机器级代码的编译器。在处理器实现中,只要我们保证机器级程序能够访问程序员可见状
态,就不需要完全按照ISA暗示的方式来表示和组织这个处理器状态。 - 内存从概念上来说就是一个很大的字节数组,保存着程序和数据。Y86-64程序用虚
拟地址来引用内存位置。硬件和操作系统软件联合起来将虚拟地址翻译成实际或物理地
址,指明数据实际存在内存中哪个地方。
Y86-64指令和指令编码
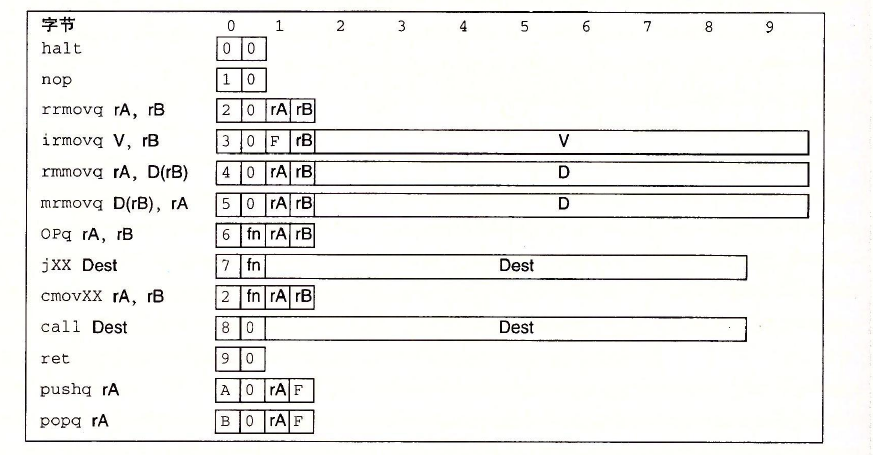
-
指令编码长度从1个字节到10个字节不等。一条指令含有一个单字节的
指令指示符,可能含有一个单字节的寄存器指示符,还可能含有一个8字节的常数字。字段fn指明是某个整数操作(OPq)、数据传送条件(cmovXX)或是分支条件(jXX)。所有的数值都
用十六进制表示 -
每条指令需要
哪些字段。每条指令的第一个字节表明指令的类型。
1一10个字节不等,这取决于需要
这个字节分为两个部分,每部分4位:高4位是代码(code)部分,低4位是功能(function)部分。如图4-2所示,代码值为
0^' OxB。功能值只有在一组相关指令共用一个代码时才有用。图4-3给出了整数操作、分
支和条件传送指令的具体编码。可以观察到,rrmovq与条件传送有同样的指令代码。可
以把它看作是一个“无条件传送”,就好像jmp指令是无条件跳转一样,它们的功能代码
都是0
Y86-64程序
long sum(long *start,long count)
{
long sum=0
while (count)
{
sum+=*start;
start++;
coun--;
}
return sum;
}
//x86-64 code
long sum. (long *start,long count)
start in %rdi,count in %rsi
Sum:
movl $0,%eax sum=0
jmp .L2 Goto test
.L3: loop:
addq (%rdi),%rax Add *start to sum
addq $8, %rdi start++
subq $1,%rsi coun--
.L2: test:
testq %rsi, %rsi Test sum
jne .L3 If !=0,goto loop
rep; ret Return
//y86-64 code
long sum (long*start ,long count)
start in %rdi,count in %rsi
sum:
irmovq $8,%r8
irmovq $1,%r9
xorq %rax,%rax
andq %rsi,%rsi
jmp test
loop:
mrmovq (%rdi),%r10
addq %r10,%rax
addq %r8,%rdi
subq %r9,%rsi
test:
jne loop
ret
- Y86-64将常数加载到寄存器(第2 -v 3行),因为它在算术指令中不能使用立即数。
- 要实现从内存读取一个数值并将其与一个寄存器相加,Y86-64代码需要两条指令
(第8 -}- 9行),而x86-64只需要一条addq指令(第5行)。 - 手工编写的Y86-64实现有一个优势,即。ubq指令(第11行)同时还设置了条
件码,因此GCC生成代码中的testq指令(第9行)就不是必需的。不过为此,Y86-64代码必须用andq指令(第5行)在进人循环之前设置条件码。
逻辑门
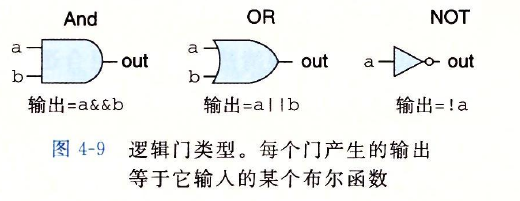
- 逻辑门是数字电路的基本计算单元。它们产生的输出,等于它们输人位值的某个布尔
函数。如图是布尔函数AND, OR和NOT的标准符号,C语言中运算符(2. 1. 8节)的
逻辑门下面是对应的HCL表达式:AND用&. &表示,OR用}l表示,而NOT用!表
示。用这些符号而不用C语言中的位运算符&,}和一,这是因为逻辑门只对单个
位的数进行操作,而不是整个字。虽然图中只说明了AND和OR门的两个输人的版本,
但是常见的是它们作为n路操作,n}2。不过,在HCL中我们还是把它们写作二元运算
符,所以,三个输人的AND门,输人为a.
b和c,用HCL表示就是a&&b&&co - 逻辑门总是活动的(active)。一旦一个门
的输人变化了,在很短的时间内,输出就会
相应地变化。
流水线及其实现方式
计算流水线

这里的“顾客”就是指令,每个阶段完成指令
执行的一部分。图给出了一个很简单的非流水线化的硬件系统例子。它是由一些执
行计算的逻辑以及一个保存计算结果的寄存器组成的。时钟信号控制在每个特定的时间间
隔加载寄存器。CD播放器中的译码器就是这样的一个系统。输人信号是从CD表面读出
的位,逻辑电路对这些位进行译码,产生音频信号。图中的计算块是用组合逻辑来实现
的,意味着信号会穿过一系列逻辑门,在一定时间的延迟之后,输出就成为了输人的某个
函数。
SEQ+重新安排计算阶段
作为实现流水线化设计的一个过渡步骤,我们必须稍微调整一下SEQ中五个阶段的
顺序,使得更新PC阶段在一个时钟周期开始时执行,而不是结束时才执行。只需要对整
体硬件结构做最小的改动,对于流水线阶段中的活动的时序,它能工作得更好。我们称这
种修改过的设计为“SEQ+"
插入流水线寄存器
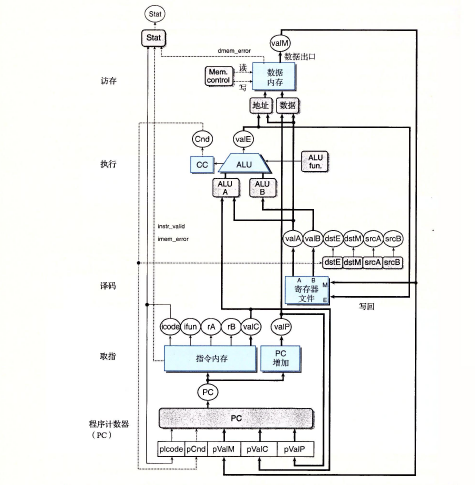
在创建一个流水线化的Y86-64处理器的最初尝试中,我们要在SEQ十的各个阶段之
间插人流水线寄存器,并对信号重新排列,得到PIPE一处理器,这里的“一”代表这个
处理器和最终的处理器设计相比,性能要差一点。PIPE一的抽象结构如图所示。流
水线寄存器在该图中用黑色方框表示,每个寄存器包括不同的字段,用白色方框表示。正
如多个字段表明的那样,每个流水线寄存器可以存放多个字节和字。同两个顺序处理器的
硬件结构中的圆角方框不同,这些白色的方框表示实际的硬件组成。
对信号进行重排列和标号
顺序实现SEQ和SEQ+在一个时刻只处理一条指令,因此诸如va1C. srcA和valE
这样的信号值有唯一的值。在流水线化的设计中,与各个指令相关联的这些值有多个版
本,会随着指令一起流过系统。例如,在PIPE一的详细结构中,有4个标号为“Stat”的
白色方框,保存着4条不同指令的状态码。我们需要很小心以确保使用的是
正确版本的信号,否则会有很严重的错误,例如将一条指令计算出的结果存放到了另一条
指令指定的目的寄存器。我们采用的命名机制,通过在信号名前面加上大写的流水线寄存
器名字作为前缀,存储在流水线寄存器中的信号可以唯一地被标识。例如,4个状态码可
以被命名为D:tat, E stat、M stat和w stat。我们还需要引用某些在一个阶段内刚
刚计算出来的信号。它们的命名是在信号名前面加上小写的阶段名的第一个字母作为前
缀。以状态码为例,可以看到在取指和访存阶段中标号为“Stat”的控制逻辑块。因而,
这些块的输出被命名为f stat和m stat。我们还可以看到整个处理器的实际状态Stat
是根据流水线寄存器W中的状态值,由写回阶段中的块计算出来的。
测试下一个PC
在PIPE一设计中,我们采取了一些措施来正确处理控制相关。流水线化设计的目的就
是每个时钟周期都发射一条新指令,也就是说每个时钟周期都有一条新指令进人执行阶段并
最终完成。要是达到这个目的也就意味着吞吐量是每个时钟周期一条指令。要做到这一点,
我们必须在取出当前指令之后,马上确定下一条指令的位置。不幸的是,如果取出的指令是
条件分支指令,要到几个周期后,也就是指令通过执行阶段之后,我们才能知道是否要选择
分支。类似地,如果取出的指令是ret,要到指令通过访存阶段,才能确定返回地址。
实验5:处理器体系结构
wget http://labfile.oss.aliyuncs.com/courses/413/sim.tar//下载sim.tar文件
tar -xvf sim.tar//解压sim.tar文件
cd sim//切换目录
sudo apt-get install bison flex tk//安装bison flex
sudo ln -s /usr/lib/x86_64-linux-gnu/libtk8.6.so /usr/lib/libtk.so//配置环境
sudo ln -s /usr/lib/x86_64-linux-gnu/libtcl8.6.so /usr/lib/libtcl.so

make//编译文件
sudo apt-get install tcl8.5-dev tk8.5-dev tcl8.5 tk8.5//下载图形界面工具
//修改mkaefile(sim目录下)用文档方式打开,做以下修改
GUIMODE=-DHAS_GUI
TKLIBS=-L/usr/lib/ -ltk8.5 -ltcl8.5
TKINC=-I/usr/include/tcl8.5
//保存并退出,切换到pipe目录下
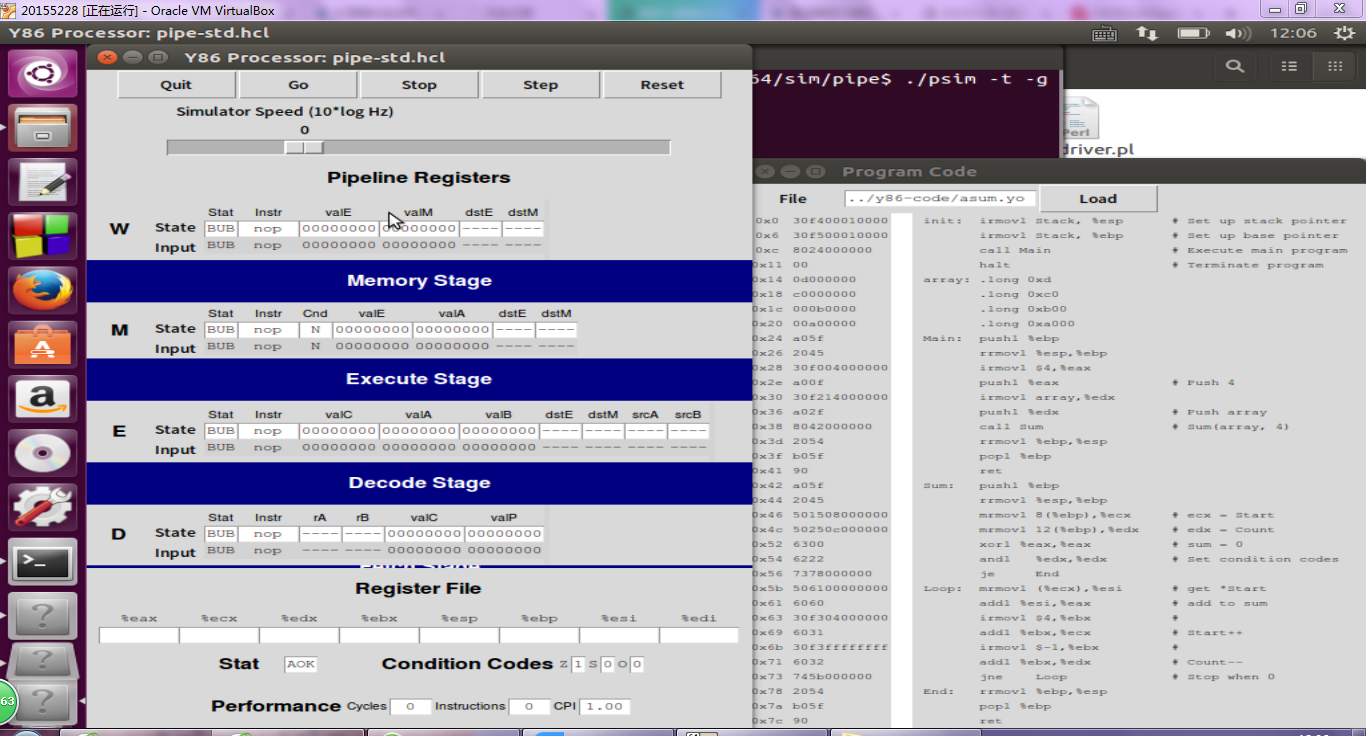
./psim -t -g ../y86-code/asum.yo
教材学习中的问题和解决过程
存储器和时钟
组合电路从本质上讲,不存储任何信息。相反,它们只是简单地响应输人信号,产生等
于输入的某个函数的输出。为了产生时序电路(sequential circuit),也就是有状态并且在这个
状态上进行计算的系统,我们必须引人按位存储信息的设备。存储设备都是由同一个时钟控制
的,时钟是一个周期性信号,决定什么时候要把新值加载到设备中。考虑两类存储器设备:
- 时钟寄存器(简称寄存器)存储单个位或字。时钟信号控制寄存器加载输人值。
- 随机访问存储器(简称内存)存储多个字,用地址来选择该读或该写哪个字。随机访
问存储器的例子包括:1)处理器的虚拟内存系统,硬件和操作系统软件结合起来使
处理器可以在一个很大的地址空间内访问任意的字;2)寄存器文件,在此,寄存器
标识符作为地址。在IA32或Y86-64处理器中,寄存器文件有15个程序寄存器(%
rax一%r14)。
代码调试中的问题和解决过程
//y86-64 code
long sum (long*start ,long count)
start in %rdi,count in %rsi
sum:
irmovq $8,%r8
irmovq $1,%r9
xorq %rax,%rax
andq %rsi,%rsi
jmp test
loop:
mrmovq (%rdi),%r10
addq %r10,%rax
addq %r8,%rdi
subq %r9,%rsi
test:
jne loop
ret
练习题4. 5
修改sum函数的Y86-64代码,实现函数absSum,它计算一个
数组的绝对值的和。在内循环中使用条件跳转指令。
#long absSum(long *start ,long count)
#start in %rdi,count in %rsi
absSum:
irmovq $8,%r8
irmovq $1,%r9
xorq %rax,%rax
andq %rsi,%rsi
jmp test
loop:
mrmovq (%rdi),%r10
xorq %rli,%rll
subq %r10,%r11
jle pos
rrmovq %r11,%r10
pos:
addq %r10,%rax
addq %r8,%rdi
subq %r9,%rsi
test:
jne loop
ret
代码托管

本周结对学习情况
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 | |
| 第五周 | 400/900 | 2/6 | 6/30 | |
| 第六周 | 200/1100 | 1/7 | 6/30 | |
| 第七周 | 500/1600 | 2/9 | 6/36 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:6小时
-
实际学习时间:6小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)