常见的操作语句
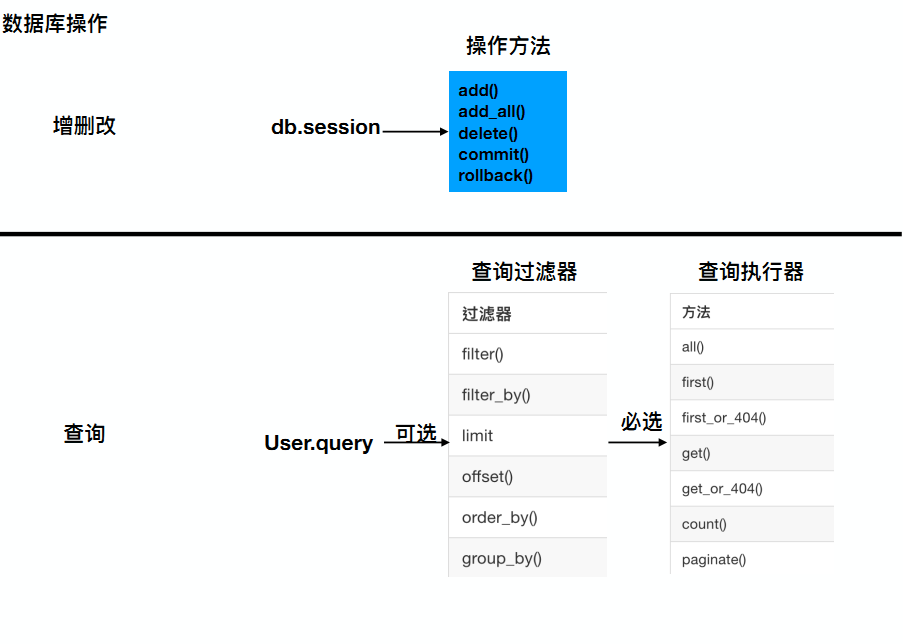
- db.session.add(obj) 添加对象
- db.session.add_all([obj1,obj2,..]) 添加多个对象
- db.session.delete(obj) 删除对象
- db.session.commit() 提交会话
- db.session.rollback() 回滚
- db.session.remove() 移除会话
常用的SQLAlchemy查询过滤器
| 过滤器 | 说明 |
|---|---|
| filter() | 把过滤器添加到原查询上,返回一个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
| limit | 使用指定的值限定原查询返回的结果 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() |
根据指定条件对原查询结果进行分组,返回一个新查询 |
常用的SQLAlchemy查询执行器
| 方法 | 说明 |
|---|---|
| all() | 以列表形式返回查询的所有结果 |
| first() | 返回查询的第一个结果,如果未查到,返回None |
| first_or_404() | 返回查询的第一个结果,如果未查到,返回404 |
| get() | 返回指定主键对应的行,如不存在,返回None |
| get_or_404() | 返回指定主键对应的行,如不存在,返回404 |
| count() | 返回查询结果的数量 |
| paginate() | 返回一个Paginate对象,它包含指定范围内的结果 |
练习


from flask import Flask from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) #配置信息 app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:123456@127.0.0.1:3306/basic8" #设置压制警告信息,如果True会追踪数据库变化,会增加显著开销,所以建议设置为False app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False #创建SQLAlchemy类对象,关联app db = SQLAlchemy(app) #编写模型类,继承db.Model #角色,用户之间的关系 class Role(db.Model): __tablename__ = "roles" #指定表名称 #参数1:表示整数类型, 参数2:表示主键 id = db.Column(db.Integer,primary_key=True) #角色名唯一的 name = db.Column(db.String(64),unique=True) #需要设置关系属性relationship(不会产生字段),设置在一方 #给Role添加了users关系属性, 查询格式: role.users #给User添加了role关系属性(反向引用),查询格式: user.role users = db.relationship('User',backref='role') #为了方便的看到对象输出的内容__repr__, 如果是普通类__str__ def __repr__(self): return "<Role:%s>"%self.name # 用户(多方) class User(db.Model): __tablename__ = "users" # 指定表名称 #参数1:表示整数类型, 参数2:表示主键 id = db.Column(db.Integer,primary_key=True) #用户名唯一的 name = db.Column(db.String(64),unique=True) #邮箱密码 email = db.Column(db.String(64),unique=True) password = db.Column(db.String(64)) #外键 role_id = db.Column(db.Integer,db.ForeignKey(Role.id)) #为了方便的看到对象输出的内容__repr__, 如果是普通类__str__ def __repr__(self): return "<User:%s,%s,%s,%s>"%(self.id,self.name,self.email,self.password) if __name__ == '__main__': #为了演示方便,先删除数据库表,和模型类关联的表 db.drop_all() #创建表,所有继承自dbModel的表 db.create_all() #创建测试数据 ro1 = Role(name='admin') db.session.add(ro1) db.session.commit() # 再次插入一条数据 ro2 = Role(name='user') db.session.add(ro2) db.session.commit() #多条用户数据 us1 = User(name='wang', email='wang@163.com', password='123456', role_id=ro1.id) us2 = User(name='zhang', email='zhang@189.com', password='201512', role_id=ro2.id) us3 = User(name='chen', email='chen@126.com', password='987654', role_id=ro2.id) us4 = User(name='zhou', email='zhou@163.com', password='456789', role_id=ro1.id) us5 = User(name='tang', email='tang@itheima.com', password='158104', role_id=ro2.id) us6 = User(name='wu', email='wu@gmail.com', password='5623514', role_id=ro2.id) us7 = User(name='qian', email='qian@gmail.com', password='1543567', role_id=ro1.id) us8 = User(name='liu', email='liu@itheima.com', password='867322', role_id=ro1.id) us9 = User(name='li', email='li@163.com', password='4526342', role_id=ro2.id) us10 = User(name='sun', email='sun@163.com', password='235523', role_id=ro2.id) db.session.add_all([us1, us2, us3, us4, us5, us6, us7, us8, us9, us10]) db.session.commit() app.run(debug=True)
增加
user = User(name='laowang') db.session.add(user) db.session.commit()
修改
user.name = 'xiaohua' db.session.commit()
删除
db.session.delete(user)
db.session.commit()
查询
特点: 模型.query: 得到了所有模型的数据的结果集对象 模型.query.过滤器: 过滤出了想要的数据,还是一个查询结果集对象 模型.query.过滤器.执行器: 取出了结果集中的内容 查询所有用户数据 User.query.all() ==> [user1,user2] 查询有多少个用户 User.query.count() 查询第1个用户 User.query.first() 查询id为4的用户[3种方式] User.query.get(4) (这里面只能是数字 或 ‘4’) 查询不到不会报错 User.query.filter_by(id = 4).first() (一个等号)查询不到不会报错 User.query.filter(User.id == 4).first() 查询不到不会报错 查询名字结尾字符为g的所有数据[开始/包含] User.query.filter(User.name.endswith('g')).all() User.query.filter(User.name.startswith('g')).all() User.query.filter(User.name.contains('g')).all() 查询名字不等于wang的所有数据[2种方式] User.query.fliter(User.name != 'wang').all() 或者 from sqlalchemy import not_ User.qudry.filter(not_(User.name == 'wang')) 查询名字和邮箱都以 li 开头的所有数据[2种方式] from sqlalchemy import and_ User.query.filter(User.name.startswith('li'),User.email.startswith('li')).all() User.query.filter(and_(User.name.startswith('li'),User.email.startswith('li'))).all() 查询password是 `123456` 或者 `email` 以 `itheima.com` 结尾的所有数据 from sqlalchemy import or_ User.query.filter(or_(User.password == '123456',User.email.endswith('itheima.com'))).all() 查询id为 [1, 3, 5, 7, 9] 的用户列表 User.query.filter(User.id.in_([1,3,5,7,9])).all() 查询name为liu的角色数据 user = User.query.filter(User.name == 'liu').first() role = Role.query.filter(Role.id == user.role_id).first() 查询所有用户数据,并以邮箱排序 User.query.order_by(User.email).all() User.query.order_by(User.email.desc()).all() 每页3个,查询第2页的数据 paginate = User.query.paginate(page, per_page,Error_out) paginate = User.query.paginate(2,3,False) page: 哪一个页 per_page: 每页多少条数据 Error_out: False 查不到不报错 paginate .pages: 共有多少页 paginate .items: 当前页数的所有对象 paginate .page: 当前页
sqlalchemy查询常见的过滤方式
sqlalchemy查询常见的过滤方式 filter过滤条件: 过滤是数据提取的一个很重要的功能,以下对一些常用的过滤条件进行解释,并且这些过滤条件都是只能通过filter方法实现的: 1. equals : == news= session.query(News).filter(News.title == "title1").first() query里面是列查询,字段,传入模型名表示全字段 。 filter是行查询,没有filter表示全表查询 2. not equals : != query(User).filter(User.name != 'ed') 3. like[不区分大小写] & ilike[区分大小写]: query(User).filter(User.name.like('%ed%··')) query(User).filter(User.name.like('__ed%__')) _表示站位符 4. in: query(User).filter(User.name.in_(['ed','wendy','jack'])) 5. not in: query(User).filter(~User.name.in_(['ed','wendy','jack'])) 6. is null: query(User).filter(User.name==None) # 或者是 query(User).filter(User.name.is_(None)) 7. is not null: query(User).filter(User.name != None) # 或者是 query(User).filter(User.name.isnot(None)) 8. and: query(User).filter(and_(User.name=='ed',User.fullname=='Ed Jones')) # 或者是传递多个参数 query(User).filter(User.name=='ed',User.fullname=='Ed Jones') # 或者是通过多次filter操作 query(User).filter(User.name=='ed').filter(User.fullname=='Ed Jones') 9. or: query(User).filter(or_(User.name=='ed',User.name=='wendy')) 如果想要查看orm底层转换的sql语句,可以在filter方法后面不要再执行任何方法直接打印就可以看到了。比如: news = session.query(News).filter(or_(News.title=='abc',News.content=='abc')) print(news)