论文地址 :https://www.aclweb.org/anthology/P19-1483/
作者 :Bhuwan Dhingra, Manaal Faruqui, Ankur Parikh, Ming-Wei Chang, Dipanjan Das, William Cohen
机构 : CMU,Google
研究的问题:
关注的是table2text中评估指标的问题。当前主要使用的是BLEU、ROUGE,但是这种评估指标前提是参考文本是完全标准的,实践中往往并非如此。本文提出了一种新的评估指标,PARENT(Precision And Recall of Entailed Ngrams from the Table)。是将参考文献和生成的文本中的n-gram对其到半结构化数据中,然后计算它们的精度和召回率。
这里举了一个例子:
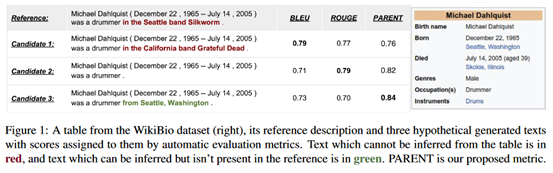
可以看见,左边句子中红色的部分是无法从表中得出的信息,而绿色的部分是可以得出的信息,这说明数据集的参考句子在一定程度上和表格信息出现了偏离(diverge)。而真正在候选文本3中应该得出的信息在参考文本中却没有出现。如果我们使用BLEU值或ROUGE值进行评估,发现候选文本3的得分反而最低,这显然是不符合人类的判断的。所以我们需要一种解决文本偏离的方法,或者说制定一种更符合人类判断标准的指标。PARENT是将生成的句子直接和表格信息比较,从而和人类的判断更加契合。
研究方法:
首先定义table2text任务。将table表示为一些记录的集合,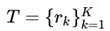 ,每个记录是一个三元组(entity, attribute, value)。当该表格的所有记录的entity都是相同的话,我们可以省略entity将其变为二元组(attribute, value)。任务就是根据给定的表格记录,生成一段流畅的文本G对其进行描述。在训练阶段,我们还假定有参考文本R。数据集合文本可以描述为
,每个记录是一个三元组(entity, attribute, value)。当该表格的所有记录的entity都是相同的话,我们可以省略entity将其变为二元组(attribute, value)。任务就是根据给定的表格记录,生成一段流畅的文本G对其进行描述。在训练阶段,我们还假定有参考文本R。数据集合文本可以描述为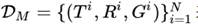 。
。
此外,用 表示
表示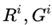 中的n-gram集合,
中的n-gram集合,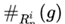 表示其中对应的文本中g的数量,
表示其中对应的文本中g的数量,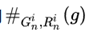 表示
表示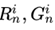 中g的数量的最小值。
中g的数量的最小值。
下面具体介绍PAENT,它对于每组数据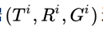 评估。
评估。
隐含的概率:
表示一个出现在文本中的n-gram(用g表示),在给定的表格下,为真的概率。也就是可以从表格推理出g的概率。作者介绍了两种模型来估计这个概率。
单词重叠模型:令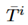 表示出现在
表示出现在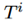 中的所有词的集合,然后计算
中的所有词的集合,然后计算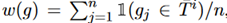 ,这里的n是g的长度。
,这里的n是g的长度。
共发生模型:由一个表格推出一个g这个-gram中的一个词的概率等于使用其中一项来推出它的概率的最大值。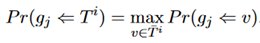 这里的v是表中的一项。这里的
这里的v是表中的一项。这里的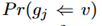 是通过统计训练集中表项和参考文献共现的次数来得到的。对于n-gram总体的概率是取几何平均值。
是通过统计训练集中表项和参考文献共现的次数来得到的。对于n-gram总体的概率是取几何平均值。
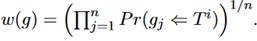
接下来是计算precision和recall。
Precision:当计算precision时,需要知道在生成文本中多少的n-gram是正确的。对于正确的定义包括两个方面,一个是该n-gram出现在了参考文本中,或者它的w(g)分数很高,都说它是正确的。
使用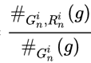 来表示g出现参考文本中的概率,那么precision的公式如下:
来表示g出现参考文本中的概率,那么precision的公式如下:
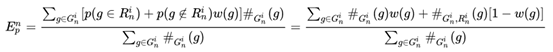
对于上边这个式子的解释是,当g以p的概率出现在参考文本中时,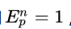 ,否则
,否则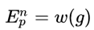
和BLEU类似的,用1-4gram来求几何平均表示精度。
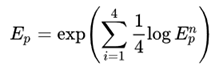
Recall:在计算recall的时候,同时考虑了参考文本和表格两部分内容。
首先,计算关于参考文本的recall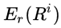 ,公式如下:
,公式如下:
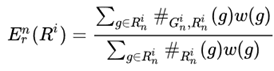
之所以使用w(g)来加权,是为了排除上文提到的偏离的问题。
这里和精度一样,使用1-4gram来求几何平均值表示。
对于表格部分的recall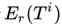 ,因为表格是一系列记录的集合。对于一条记录r_k,使用
,因为表格是一系列记录的集合。对于一条记录r_k,使用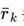 去表示它的字符串值(也就是内容项,比如上边图1当中的Michael Dahlquist或者male等)。计算公式如下:
去表示它的字符串值(也就是内容项,比如上边图1当中的Michael Dahlquist或者male等)。计算公式如下:

在得到了参考本文和表格各自的recall之后,取几何平均值作为最终的召回率。
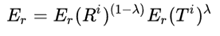
几何平均可以理解为一个AND操作,也就是只有两者的recall都高时,最终的recall才高。比如直接简单地复制表格的内容也可以得到很高的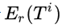 ,但它不应该是一个好的结果。
,但它不应该是一个好的结果。
在有了precision和recall之后,就可以计算F值了,也就是PARENT值,对于一个模型M,它的PARENT值如下所示:
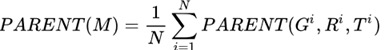
一些操作:
(1)平滑。为了避免求几何平均值过程中出现0的情况,使用了smoothing方法。具体是给每个为0的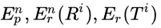 赋予一个小的值。
赋予一个小的值。
(2)多份参考。当有多个参考文本时,像METEOR一样去计算每个参考文本的PARENT值并取最大。
信息抽取的评估方式:
在PARENT指标之外,作者来提出了一种信息抽取的评价标准。作者提出了一个指针网络,从文本中抽取(attribute, value)对,然后跟表格的内容比较。作者在wikiBio上训练的,取得了35.1的F值。
在获得了之后这样的信息抽取系统之后,可以有以下三种评估方式:
Content selection(CS):从生成文本和参考文本中分别抽取(attribute, value)对,从而进行F值的比较。
Relation Generation(RG): 从生成文本中抽取(attribute, value)对,与表格进行比较,得到精确值。
RGF: 同上,只不过比较的是F值。
实验部分:
首先通过人工评估几个模型,评估标准包括流畅性、信息完整性、内容可靠性,结果如下:
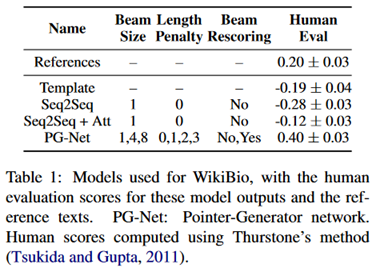
可以看到,PG-Net取得了最好的结果。
之后就是模型在各种指标下的结果。

这里的C/W对应于概率建模的两种模型(单词重叠模型和共发生模型),这个表还是很明显地可以看出PARENT的区分度远优于其它评估标准。
评价:
讨论table2text的评估指标的一篇很优秀的论文。对于使用BLEU、METHOR的评估指标,只考虑了参考文本,没有考虑表本身。所以本文的motivation很自然地提出利用表的信息。计算的方法就是一个gram和表格中信息的匹配相似度,这样就避免了参考文本与表格提供信息之间出现的误差。之后将两个部分,参考文本和表部分的分数通过对“正确性”的定义统一到了一个公式当中。实验部分可以看出来PARENT的区分度相当好,作者也通过实验证明了PARENT与人工评估有最高的相关性,即最符合人类的评价标准。另外作者来讨论了信息抽取方式的评估,这部分是将前人推广到开放领域当中,也通过实验进行了评估。