论文地址 :https://www.aclweb.org/anthology/P19-1353/
作者 :Matthew Sims, Jong Ho Park, David Bamman
机构 :伯克利
研究的问题:
制作了一个文学事件数据集,也就是发生在小说里的事件。通过100本书选取了7849个事件,包含210532个token。
研究方法:
数据:主要是19世纪和20世纪的经典小说,如《傲慢与偏见》《尤利西斯》等,共1000本。
事件:
对于事件,按照Vendler(1957)提出的,分为以下四种:
Activities:一个动态演变的过程
Achievements:几乎瞬间完成
Accomplishments:持续一段时间,有个明确的端点
States:持续一段时间,没有明确的端点
事件的性质按照ACE2005的定义如下:
极性:必须是一个肯定的断言。如“他没有理解”不定义为一个事件。
时态:必须是过去式或现在式。不包括将来式。
通用性:只关注特定事件(如:我的狗今天早上叫了),不关注通用事件(如:狗叫)。也就是事件需要是在特定时间特定地点发生的。
Modelity:只包括明确发生的,不包括那些如“相信的、假设的、期望的”等。
额外的一些标准如下:
1、使用包括该事件的最小文本范围表示该事件,因此事件总是用一个单词来表述。
2、限定位动词、形容词、副词。
下面是三个例子。

实验部分:
使用的模型包括LSTM、BiLSTM、LSTM with document context、BiLSTM with sentence CNN、BiLSTM with subword CNN、BiLSMT with BERT。
实验结果如下:

最后作者做了一个额外的实验,使用上边的事件监测模型来探究更受欢迎的作者的作品与不受欢迎的作者的作品中真实事件的分布。结果如下:
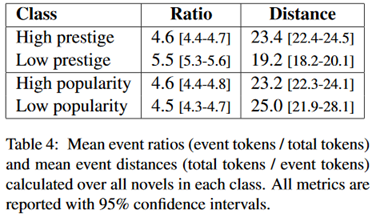
不过其实很难发现什么规律。
评价:
不得不承认的是,标记这样的一个数据集本身是一个很有挑战性的工作。因为它不像新闻中,小说通常会使用很多修辞手法,这些需要针对特定的例子来分析是否符合事件的定义,是否被定义为一个事件。如果做文学文本的分析,应该会是一个不错的数据集。作者最后做的使用事件监测模型来探究不同作者中真实事件的分布与其受欢迎程度的关系,作者的逻辑是,这样可以说明事件探测在文本分析中的重要性,因此我们做的这个数据集很重要。但从实验结果上来看并没有什么明显规律。不过在这个方面之前也没有这方面的研究。附上数据集的链接https://github.com/dbamman/litbank。