论文地址 : https://www.aclweb.org/anthology/P19-1352/
作者 :Xuebo Liu, Derek F. Wong, Yang Liu, Lidia S. Chao, Tong Xiao, Jingbo Zhu
机构 :澳门大学,清华大学,东北大学
研究的问题:
研究翻译任务中词向量的问题。传统的端到端模型中,源语言词向量和目标语言词向量是通过soft attention机制建立联系的,它们相对隔离且参数量大。本文提出利用共享-私有的词向量来建模源语言词向量和目标语言词向量之间的关系,同时减少了参数量。
研究方法:
核心思想:在单词向量空间中,相似的词在词向量上往往具有相似性,这一点已经在很多工作中证明。本文基于这一点,假设在源语言和目标语言中,表示相同意思的词也具有相似的向量,也就是说这部分是与语言无关的,可以共享;而另外一部分,作为私有向量,保留源语言和目标语言的私有特征。
方法:
首先,作者这里对源语言中的词和目标语言之间的词的关系做了分类:
(1) 词义相近(记为lm)
(2) 词形相近(记为wf)
(3) 不相关(记为ur)
源语言中的词和目标语言之间的词之间的约束如下:
(1) 一个源语言中的词只能和一个目标语言之间的词共享特征,反之亦然。
(2) 每个源语言中的词的匹配优先级是词义相近大于词形相近大于不相关
在实现上,首先利用fast-align根据一定的阈值找到语义对齐的词语,设源语言的词向量矩阵为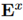 ,这个矩阵由三部分组成:
,这个矩阵由三部分组成:
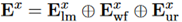
其分别代表前述三种共享关系的词语表示。由于前边的约束,每个词语只属于其中一种关系。而每种共享关系都是由共享部分和私有部分组成的。如
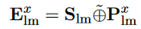
其中,S_lm表示共享部分,P_lm表示私有部分。运算符表示的是矩阵的拼接。示例如下:
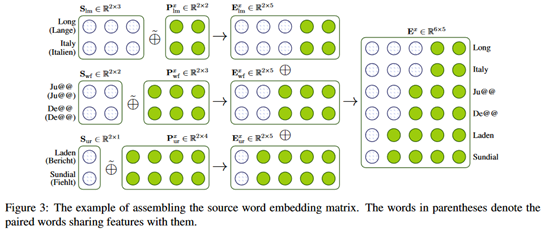
实验结果如下:
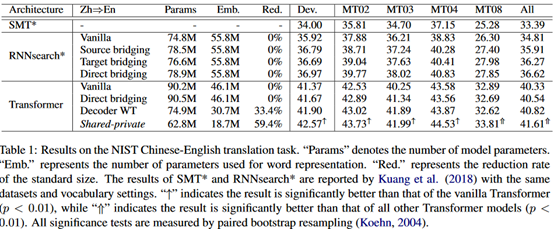
评价:
从词向量的表示上入手,提高机器翻译的质量,从结果来看提升比较明显。相较于之前的WT方法,在参数量上更有优势。在实现中,使用的是矩阵拼接,这个操作本身的计算复杂度也比较低。