论文地址:https://arxiv.org/abs/1901.02860
作者 :Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov
机构: CMU,Google
研究的问题:
Transformer的虽然具有表达长程的依赖关系,但是在目前的语言建模任务的环境设置之下,网络的输入被限制为固定长度的内容。Transformer-XL通过引入循环机制(Recurrence Mechanism)和相对位置编码(Relative Positional Encoding)来克服这个问题,不仅可以捕捉长时依赖,还解决了上下文断片问题。另外和vanilla Transformer相比,Transformer-XL的另一个优势是它可以被用于单词级和字符级的语言建模。
研究方法:
Vanilla transformer:
首先介绍vanilla transformer,它是Transformer和Transformer-XL中间过度的一个算法。原理图如下:
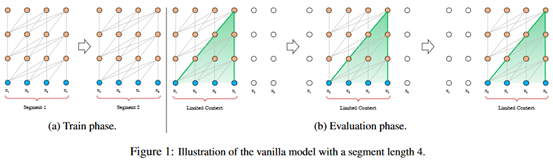
该模型基于Transformer,根据之前的字符预测片段中的下一个字符:例如,使用x_1,x_2...x_n-1预测字符x_n,x_n之后的序列被mask。
论文中,使用64层模型,并仅限于处理512个字符(定长)这种相对较短的输入,因此,它将输入分成段,分别从每个段中进行学习。在测试阶段如需处理较长的输入,该模型会在每一步中将输入向右移动一个字符,以此实现对单个字符的预测。
该模型在常用的数据集如enwik8和text8上的表现比RNN模型要好,但它仍有以下3个缺点
a. 上下文长度受限:字符之间的最大依赖距离受输入长度的限制,模型看不到出现在几个句子之前的单词。
b. 上下文碎片化:对于长度超过512个字符的文本,都是从头开始单独训练的。段与段之间没有上下文依赖性,会让训练效率低下,也会影响模型的性能。
c. 推理速度慢:在测试阶段,每次预测下一个单词,都需要重新构建一遍上下文,并从头开始计算,这样的计算速度非常慢。
Transformer-XL:循环机制
与vanilla Transformer的基本思路一样,Transformer-XL仍然是使用分段的方式进行建模,但其与vanilla Transformer的本质不同是在于引入了段与段之间的循环机制,使得当前段在建模的时候能够利用之前段的信息来实现长期依赖性。如下图所示:
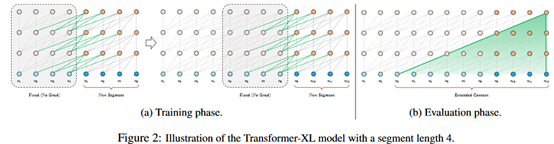
在训练阶段,处理后面的段时,每个隐藏层都会接收两个输入:
1、该段的前面隐藏层的输出,与vanilla Transformer相同(上图的灰色线)。
2、前面段的隐藏层的输出(上图的绿色线),可以使模型创建长期依赖关系。
这两个输入会被拼接,然后用于计算当前段的Key和Value矩阵。对于某个段的某一层的具体计算公式如下:
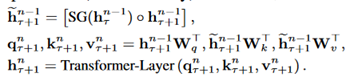
τ表示第几段,n表示第几层,h表示隐层的输出。公式中的SG表示stop-gradient,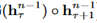 表示沿长度维度两个向量的拼接。它和transformer的主要区别在于Key和Value矩阵的计算上,即k_n_τ+1和v_n_τ+1,它们基于的是扩展后的上下文隐层状态进行计算。原则上只要GPU内存允许,该方法可以利用前面更多段的信息,测试阶段也可以获得更长的依赖。
表示沿长度维度两个向量的拼接。它和transformer的主要区别在于Key和Value矩阵的计算上,即k_n_τ+1和v_n_τ+1,它们基于的是扩展后的上下文隐层状态进行计算。原则上只要GPU内存允许,该方法可以利用前面更多段的信息,测试阶段也可以获得更长的依赖。
在测试阶段,与vanilla Transformer相比,其速度也会更快。在vanilla Transformer中,一次只能前进一个step,并且需要重新构建段,并全部从头开始计算;而在Transformer-XL中,每次可以前进一整个段,并利用之前段的数据来预测当前段的输出。
Transformer-XL:相对位置编码
在Transformer中使用了序列的位置信息。在分段的情况下,如果仅仅对于每个段仍直接使用Transformer中的位置编码,即每个不同段在同一个位置上的表示使用相同的位置编码,就会出现问题。需要对这种位置进行区分。
论文对于这个问题,提出了一种新的位置编码的方式,即会根据词之间的相对距离而非像Transformer中的绝对位置进行编码。
原始的transformer中,计算query和key之间的attention分数的公式为:
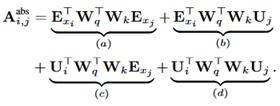
其中,E_xi是词i的embedding,U是位置向量。
在Transformer-XL中,对上述的attention计算方式进行了变换,转为相对位置的计算。

主要区别在于:
1、在(b)和(d)这两项中,将所有绝对位置向量U都转为相对位置向量R,与Transformer一样,这是一个固定的编码向量,不需要学习。
2、在(c)(d)中,将查询的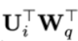 向量转为一个需要学习的参数向量u。因为在考虑相对位置的时候,不需要查询的绝对位置i,因此对于任意的i,都可以采用同样的向量。
向量转为一个需要学习的参数向量u。因为在考虑相对位置的时候,不需要查询的绝对位置i,因此对于任意的i,都可以采用同样的向量。
3、将键的权重变换矩阵W_k转为 ,分别作为content-based key vectors和location-based key vectors。
,分别作为content-based key vectors和location-based key vectors。
综上,对于一个N层的,只有一个head的模型,计算公式如下:

评价:
这篇论文是在transformer的变体中很有名的一个了。综合来说,它提出了一种新的相对位置编码,性能略有提升,但参数量增大。提出使用跨相邻两个segment的attention来建模长程依赖,在长文本上取得了更好的效果。但模型本身只能用于单向建模,后边在NIPS2019上的XLNet就是在这个网络基础上的改进,为了使其具有建模双向上下文的能力定义了permutation language modeling。并且它对于计算资源的要求也比较高。