内置模块是Python自带的功能,在使用内置模块相应的功能时,需要【先导入】再【使用】
一、time模块
在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String)
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time
#--------------------------我们先以当前时间为准,让大家快速认识三种形式的时间
print(time.time()) # 时间戳:1487130156.419527
print(time.strftime("%Y-%m-%d %X")) #格式化的时间字符串:'2017-02-15 11:40:53'
print(time.localtime()) #本地时区的struct_time
print(time.gmtime()) #UTC时区的struct_time
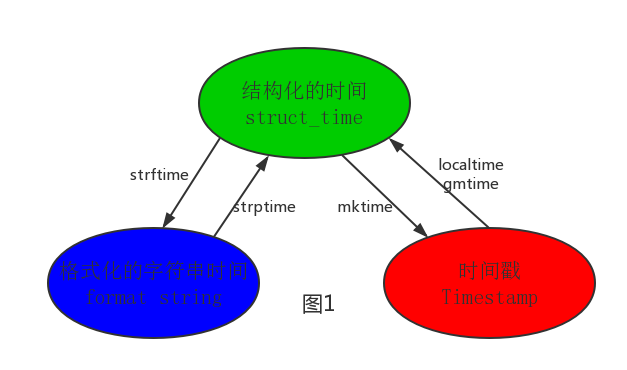
#--------------------------按图1转换时间
# localtime([secs])
# 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
time.localtime()
time.localtime(1473525444.037215)
# gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
# mktime(t) : 将一个struct_time转化为时间戳。
print(time.mktime(time.localtime()))#1473525749.0
# strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和
# time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个
# 元素越界,ValueError的错误将会被抛出。
print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56
# time.strptime(string[, format])
# 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X'))
#time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6,
# tm_wday=3, tm_yday=125, tm_isdst=-1)
#在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。
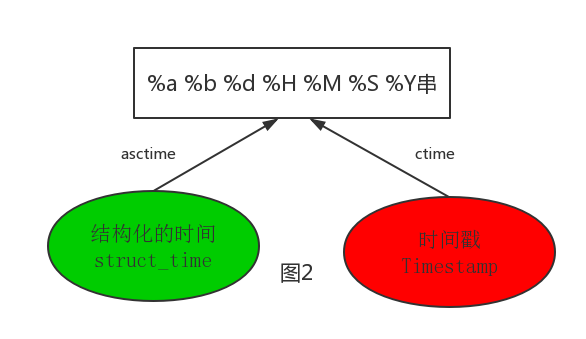
#--------------------------按图2转换时间 # asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。 # 如果没有参数,将会将time.localtime()作为参数传入。 print(time.asctime())#Sun Sep 11 00:43:43 2016 # ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为 # None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。 print(time.ctime()) # Sun Sep 11 00:46:38 2016 print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016
二、random模块
import random print(random.random())#(0,1)----float 大于0且小于1之间的小数 print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数 print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数 print(random.choice([1,'23',[4,5]]))#1或者23或者[4,5] print(random.sample([1,'23',[4,5]],2))#列表元素任意2个组合 print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716 item=[1,3,5,7,9] random.shuffle(item) #打乱item的顺序,相当于"洗牌" print(item)
三、OS模块与sys模块
os模块是与操作系统交互的一个接口,用于提供系统级别的操作。
sys模块用于提供对Python解释器相关的操作。
四、序列化
Python中用于序列化的两个模块
- json 用于【字符串】和 【python基本数据类型】 间进行转换
- pickle 用于【python特有的类型】 和 【python基本数据类型】间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
1.json模块
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象。
注意事项:
import json
#dct="{'1':111}"#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1}
dct='{"1":"111"}'
print(json.loads(dct))
#conclusion:
# 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
#----------------------------序列化
import json
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=json.dumps(dic)
print(type(j))#<class 'str'>
f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open('序列化对象')
data=json.loads(f.read())# 等价于data=json.load(f)
2.pickle模块
##----------------------------序列化
import pickle
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()
#-------------------------反序列化
import pickle
f=open('序列化对象_pickle','rb')
data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data['age'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
五、re模块