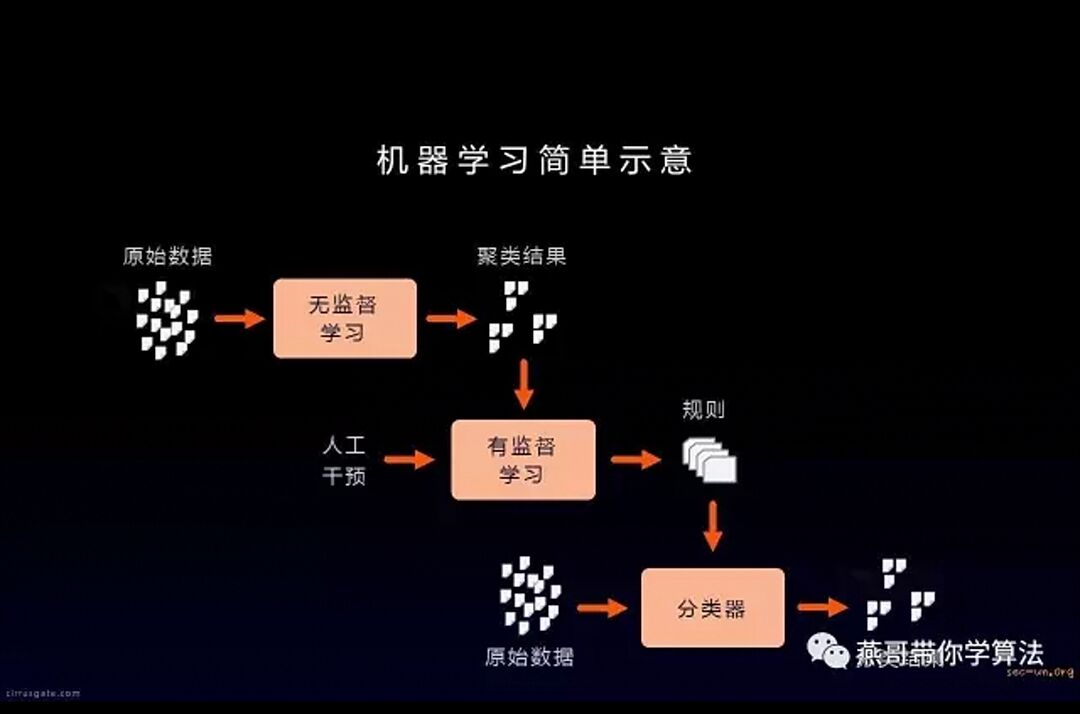
一、什么是机器学习?
对于机器学习,没有一个明确的定义。从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
A.S.(1959年)开发跳棋程序,给了机器学习一个定义:
Machine Learning:Field of study that gives computers the ability to learn without being explicitly programmed.
即:机器学习是一种未经明确的设置,便给予计算机以学习能力的领域。
T.M.(1998年)给出了另一种定义:
A computer program is said to learn from experience E with respect to some task T and some performance measure P,
if its performance on T, as measured by P, improves with experience E.
即:计算机程序从经验E中学习解决某一任务T进行某一性能度量P,通过P测定在T上的表现因经验E而提高。
该定义在跳棋程序中可以这样解释:
经验E=程序与自己下几万次跳棋 任务T=玩跳棋 性能度量P=与新对手玩跳棋时赢的概率
通俗讲,系统在任务T上的性能,在得到经验E之后会提高性能度量P。
在举一个例子,
在个人邮箱中,基于个人对某些垃圾邮件的标记,邮件程序学会了如何更好地过滤垃圾邮件,在这个例子中,
任务T=把邮件分类
经验E=观察你是否标记了垃圾邮件
性能度量P=正确归类的邮件的比例
应用:
Machine Learnning
——Grew out of work in AI
——New capability for computers
Examples:
——Database mining 数据挖掘
——Applications can`t program
——Self-customizing programs 私人订制程序
——Understanding human learning (brain,real AI)
机器学习算法:
——Supervised learning 监督学习
——Unsupervised learning 无监督学习
others :reinforcement learning 强化学习
recommender systems 推荐系统
二、监督学习
什么是监督学习?先看维基百科给出的定义:
监督式学习(英语:Supervised learning),是一个机器学习中的方法,可以由训练资料中学到或建立一个模式(函数 / learning model),并依此模式推测新的实例。
训练资料是由输入物件(通常是向量)和预期输出所组成。函数的输出可以是一个连续的值(称为回归分析),或是预测一个分类标签(称作分类)
从数据的角度来讲, 监督学习和无监督学习的区别就在于监督学习的数据不仅仅有特征组成, 即每一个数据样本都包含一个准确的输出值. 在房价预测的问题中, 数据由特征+房价组成.
1.监督学习的两类问题
在监督学习中,可预测额结果有两类,一种是连续值,一种是离散值,根据数据集的特征与属性,将监督学习划分为两类问题:回归(regression) 和分类(classification )
2.回归问题——连续值
举例:A想卖房子,但不知道卖多少合适,又不想亏本,于是他从某一二手房中介处获得了大量的卖房信息。从这些信息中找出房间大小与售价间可能的关系,然后利用这个关系,预测所要售卖房子的可能价格。在这个问题中,特征是房子的面积,输出值是房子的售价,因此这是一个监督学习的问题,而输出的房价可以看做是连续的,因此这是一个回归问题。
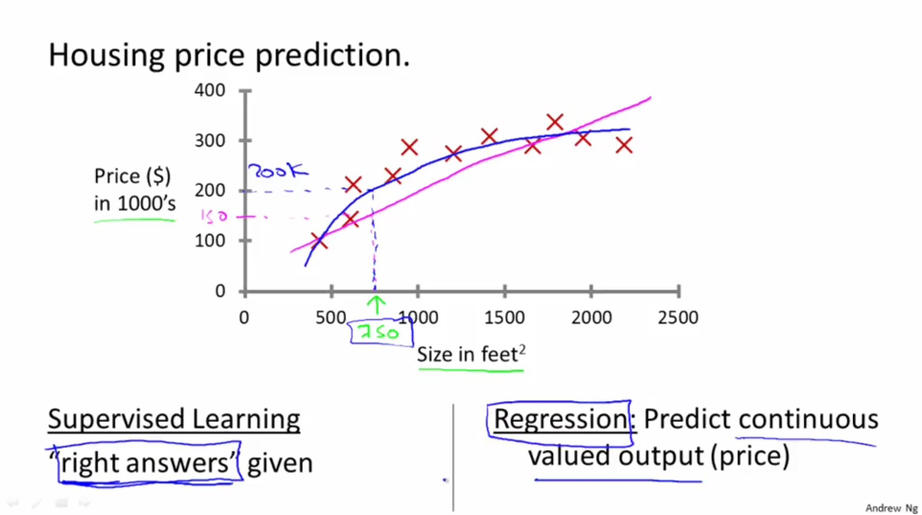
在这组数据中,我们可以采用线性函数或者二次函数来拟合数据,然后在已有数据上做出预测。机器学习有众多算法,一些强力算法可以拟合出复杂的非线性模型,用来反映一些不是直线所能表达的情况。即“right answer” given.
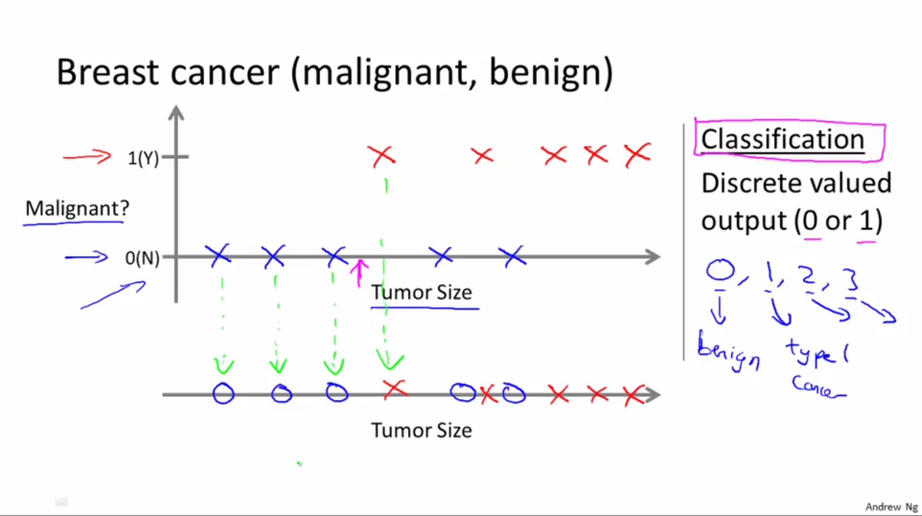
3.分类问题——离散值
对已有数据集(无特征,无属性)进行分类,例如有一组关于乳腺癌的医疗数据,其中包含肿瘤的大小及该肿瘤是良性的还是恶性的。在此问题中,输出结果只有两种情况,一种是良性,另一种是恶性(在其他问题中,输出值可以有多种可能性)。我们可以通过一个肿瘤的大小来预测它是良性的还是恶性的,我们可以用0代表良性,1代表恶性。因为此问题输出的是一个离散值,故这是一个分类问题。
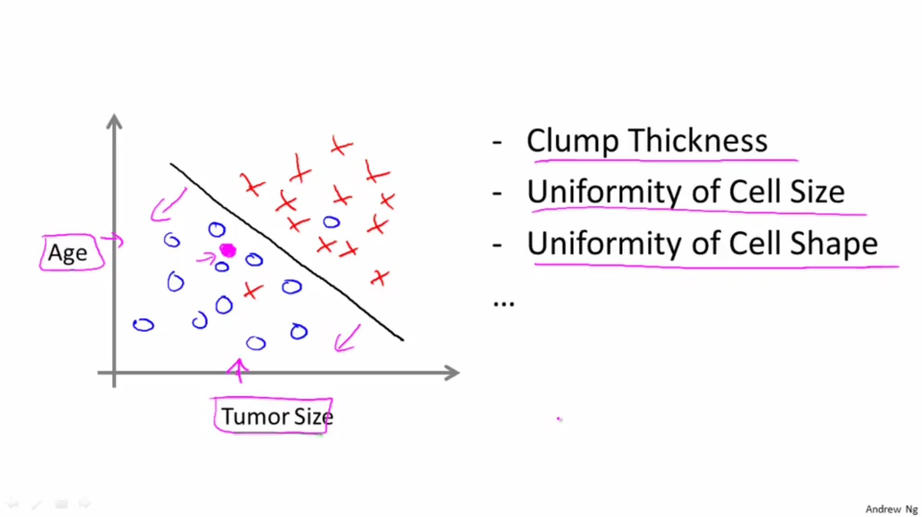
在这个例子中特征只有一个即瘤的大小。 对于大多数机器学习的问题, 特征往往有多个(上面的房价问题也是, 实际中特征不止是房子的面积). 例如下图, 有“年龄”和“肿瘤大小”两个特征。(还可以有其他许多特征,如下图右侧所示)
 三、无监督学习
三、无监督学习
对于监督学习中的每个样本,我们已经被清楚地告知了什么是所谓“right answer”,例如上面例子中的房价或者是良性还是恶性。而在无监督学习中, 我们的数据并没有给出特定的标签, 我们的目标也从预测某个值或者某个分类变成了寻找数据集中特殊的或者对我们来说有价值的结构. 如下图所示, 我们可以直观的感受到监督学习和无监督学习在数据集上的区别.
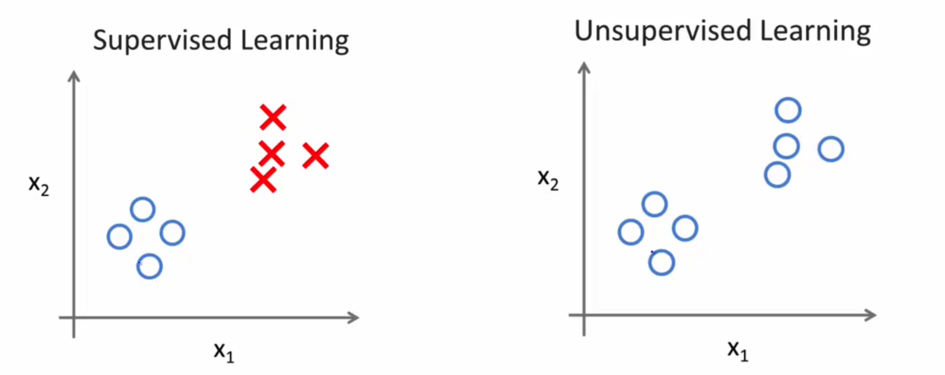
在无监督学习中,对于一个给定的数据集,无监督学习可以把这些数据分成两个不同的簇,这也被称为聚类算法。从下图中便可清晰明白,
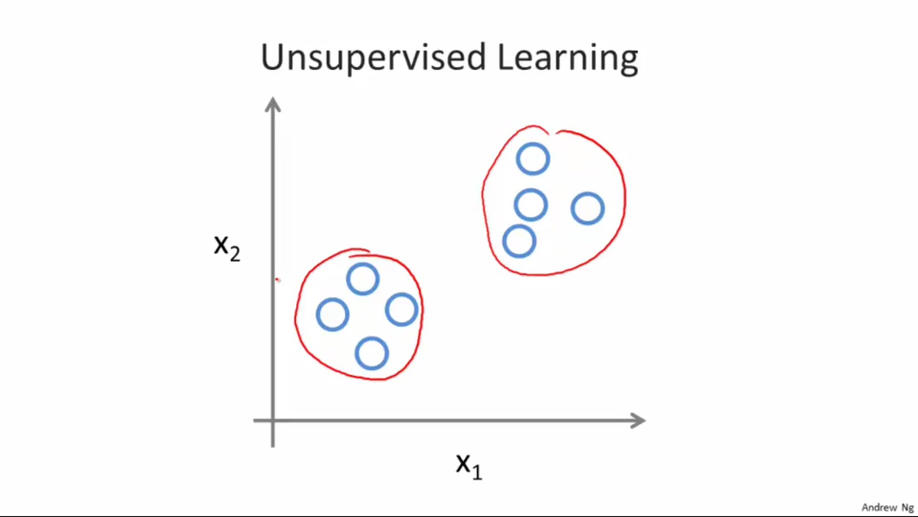
简单讲,给出一个数据集,从中分析出数据的结构,将其按结构分为不同的簇,在这其中没有数据的类型,分类等,即没有所谓的“right answer”.
无监督学习举例
1.谷歌新闻分类
在谷歌新闻中,计算机将新闻分为多个簇,属于同一簇的新闻被放到一起,
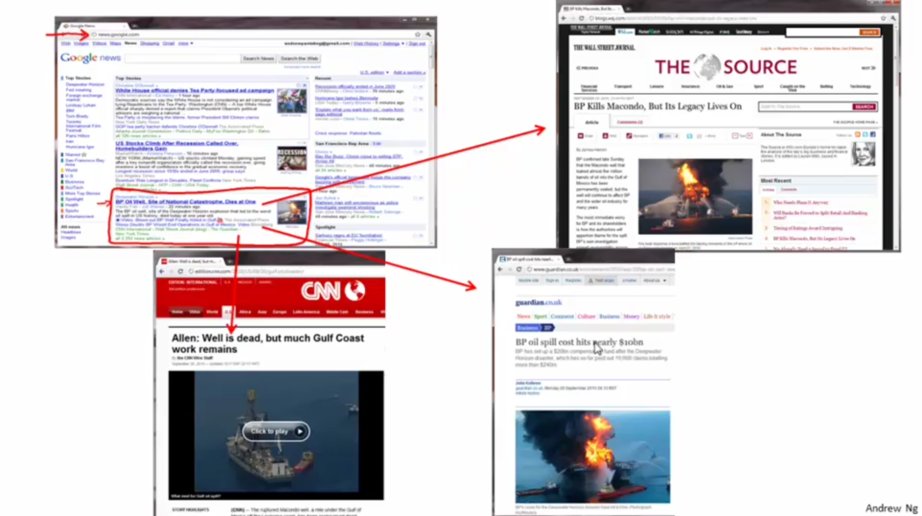
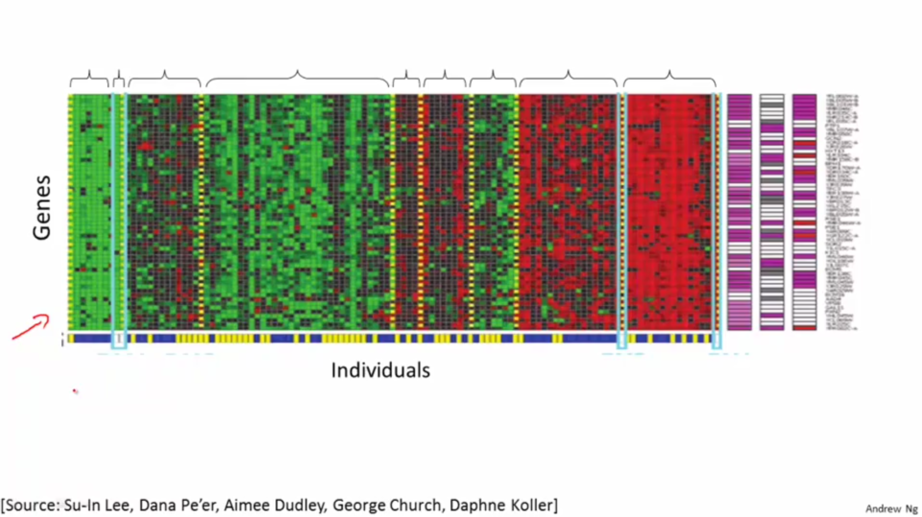
2.DNA划分
如图是DNA数据,对于一组不同的人我们测量他们DNA中对于一个特定基因的表达程度。然后根据测量结果可以用聚类算法将他们分成不同的类型。
3.“鸡尾酒会”问题
从两种相互掺杂的声音中,分离出各自不同的声源。
[W,s,v]=svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
4.其他应用
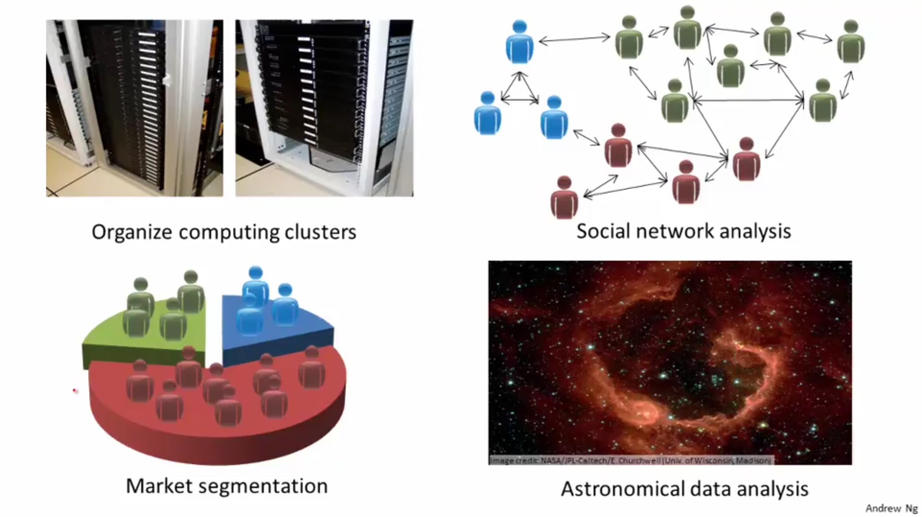
有组织计算机集群,社交网络分析,市场划分,天文数据分析等
小结:
机器学习研究的是计算机怎样模拟人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构使之不断改善自身。简单一点说,就是计算机从数据中学习出规律和模式,以应用在新数据上做预测的任务。
监督学习
监督学习是指进行训练的数据包含两部分信息:特征向量 + 类别标签。也就是说,他们在训练的时候每一个数据向量所属的类别是事先知道的。在设计学习算法的时候,学习调整参数的过程会根据类标进行调整,类似于学习的过程中被监督了一样,而不是漫无目标地去学习,故此得名。
无监督学习
相对于有监督而言,无监督方法的训练数据没有类标,只有特征向量。甚至很多时候我们都不知道总共的类别有多少个。因此,无监督学习就不叫做分类,而往往叫做聚类。就是采用一定的算法,把特征性质相近的样本聚在一起成为一类。