基本数据类型的对齐问题:
变量在内存中的存放位置一般要求自然对齐。所谓自然对齐,就是基本数据类型的变量不能简单地存储在内存中任意的位置,而是其起始地址必须满足可以被它们的大小整除。例如,32位平台下,int和指针类型变量的地址应该可以被4整除,short类型变量的地址应该可以被2整除,char和bool由于占用1个字节,因此相当于没有对齐要求。
复合数据类型的对齐问题:
复合数据类型中,其中的成员必须满足自然对齐规则,其中对齐时以相对地址为基。同时考虑到了可能使用该类型数组,因此编译器会在最后一个变量末尾插入一定的字节(具体插入多少字节以复合类型中包含的最大基本类型为准)以保证即使使用该类型数组,也尽可能不影响访问效率(一般数组中的元素都是连续存放的,如果复合类型所占空间满足其包含的最大基本类型的倍数,那么即使使用复合类型数组,也可以较高的效率访问数组中的下一个复合类型对象)。如下为一个示例程序:
1 struct A 2 { 3 bool a; 4 int b; 5 bool c; 6 double d; 7 bool e; 8 9 }; 10 11 int main() 12 { 13 struct A sa; 14 cout << sizeof(sa) << endl; 15 cout << "&sa.a = " << &sa.a << endl; 16 cout << "&sa.b = " << &sa.b << endl; 17 cout << "&sa.c = " << &sa.c << endl; 18 cout << "&sa.d = " << &sa.d << endl; 19 cout << "&sa.e = " << &sa.e << endl; 20 21 return 0; 22 } 23 24 // 32 25 // &sa = 0x22fee0 26 // &sa.a = 0x22fee0 27 // &sa.b = 0x22fee4 28 // &sa.c = 0x22fee8 29 // &sa.d = 0x22fef0 30 // &sa.e = 0x22fef8
分析:
变量sa的内存布局如下所示:

首先a的地址和结构体变量sa的地址是相同的。
a占用1个字节,地址为0x22fee0;
b占用4个字节,但是为了满足自然对齐原则,其相对地址必须为4的倍数,因此最小的可使用地址为0x22fee4;
c占用1个字节,任何地址都满足自然对齐原则,因此紧挨着b存放;
d占用8个字节,其起始地址必须满足8的倍数,因此最小可用地址为0x22fef0;
e占用1个字节,但是为何其后又填充了7个多余字节呢?这是编译器为了满足struct A类型的数组对齐而设定的。试想一下,如果不填充这多余的7个字节,那么如果定义了struct A类型的数组,那么数组中的下一个元素的存放地址必然为ox22fef1,那么就不是自然对齐的,势必会影响该数组的访问效率。因此,一个复合类型的对象的存放地址必然为其中包含的最大类型所占字节的整数倍(假设其中包含的最大类型占用x个字节,那么该符合类型必须满足x字节对齐)。
复合类型对象在内存中创建后,每个成员的地址为相对地址(相对于该复合类型的起始地址),取决于相对该对象起始地址的偏移字节数。可以使用offsetof宏来查看不同成员相对于某个复合类型起始地址的偏移字节数:
1 cout << "offsetof(A, a) = " << offsetof(A, a) << endl; 2 cout << "offsetof(A, b) = " << offsetof(A, b) << endl; 3 cout << "offsetof(A, c) = " << offsetof(A, c) << endl; 4 cout << "offsetof(A, d) = " << offsetof(A, d) << endl; 5 cout << "offsetof(A, e) = " << offsetof(A, e) << endl; 6 7 // offsetof(A, a) = 0 8 // offsetof(A, b) = 4 9 // offsetof(A, c) = 8 10 // offsetof(A, d) = 16 11 // offsetof(A, e) = 24
用户也可以为这个对象类型指定成员对其方式,可以使用#pragma编译指令实现。实际应用中,最好显式为每个复合数据类型指定对齐方式(但是要注意指定对齐方式后,虽然在某种程度上可以改善程序效率,但是不可移植),如下为示例代码:
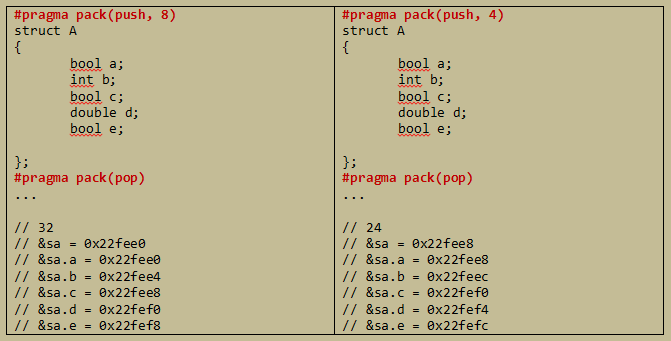
从上述程序可以看出,gcc编译器默认是8字节对齐的。
由于在存储变量时存在自然对齐和复合类型对齐这种约束,因此我们在设计一个复合类型时,尽量将占用空间比较大的成员安排到前面,这样即使需要对齐,也是以小类型成员为主,有利于节约存储空间,如:
1 #pragma pack(push, 8) 2 struct A 3 { 4 double d; 5 int b; 6 bool a; 7 bool c; 8 bool e; 9 }; 10 #pragma pack(pop) 11 // 这样安排数据成员后,结构体所占空间变为16个字节,整整减少了一半。
综上所述,可以看出影响对象实际大小和访问效率的因素包括:数据成员类型、声明顺序、对齐方式。同时不同的对齐方式还会影响接口之间的语义一致性和二进制兼容性,比如一个应用程序包含若干个模块,而不同模块使用的对齐方式不同,如果此时模块之间共享的复合数据类型也没有显式指定对齐方式,那么程序出错的概率就大大增加了,因为此时不同模块对于同一个共享数据的解释方式不一样了。