之前学习了SVM的原理(见http://www.cnblogs.com/bentuwuying/p/6444249.html),以及SMO算法的理论基础(见http://www.cnblogs.com/bentuwuying/p/6444516.html)。最近又学习了SVM的实现:LibSVM(版本为3.22),在这里总结一下。
1. LibSVM整体框架
Training: parse_command_line 从命令行读入需要设置的参数,并初始化各参数 read_problem 读入训练数据 svm_check_parameter 检查参数和训练数据是否符合规定的格式 do_cross_validation svm_cross_validation 对训练数据进行均匀划分,使得同一个类别的数据均匀分布在各个fold中 最终得到的数组中,相同fold的数据的索引放在连续内存空间数组中 Cross Validation(k fold) svm_train(使用k-1个fold的数据做训练) svm_predict(使用剩下的1个fold的数据做预测) 得到每个样本在Cross Validation中的预测类别 得出Cross Validation的准确率 svm_train classification svm_group_classes 对训练数据按类别进行分组重排,相同类别的数据的索引放在连续内存空间数组中 得到类别总数:nr_class,每个类别的标识:label,每个类别的样本数:count,每个类别在重排数组中的起始位置:start,重排后的索引数组:perm(每个元素的值代表其在原始数组中的索引) train k*(k-1)/2 models 新建1个训练数据子集sub_prob,并使用两个类别的训练数据进行填充 svm_train_one //根据svm_type的不同,使用不同的方式进行单次模型训练 solve_c_svc //针对C-SVC这一类型进行模型训练 新建1个Solver类对象s s.Solve //使用SMO算法求解对偶问题(二次优化问题) 初始化拉格朗日乘子状态向量(是否在边界上) 初始化需要参与迭代优化计算的拉格朗日乘子集合 初始化梯度G,以及为了重建梯度时候节省计算开销而维护的中间变量G_bar 迭代优化 do_shrinking(每间隔若干次迭代进行一次shrinking) 找出m(a)和M(a) reconstruct_gradient(如果满足停止条件,进行梯度重建) 因为有时候shrinking策略太过aggressive,所以当对shrinking之后的部分变量的优化问题迭代优化到第一次满足停止条件时,便可以对梯度进行重建 接下来的shrinking过程便可以建立在更精确的梯度值上 be_shrunk 判断该alpha是否被shrinking(不再参与后续迭代优化) swap_index 交换两个变量的位置,从而使得参与迭代优化的变量(即没有被shrinking的变量)始终保持在变量数组的最前面的连续位置上 select_working_set(选择工作集) 对工作集的alpha进行更新 更新梯度G,拉格朗日乘子状态向量,及中间变量G_bar 计算b 填充alpha数组和SolutionInfo对象si并返回 返回alpha数组和SolutionInfo对象si 输出decision_function对象(包含alpha数组和b) 修改nonzero数组,将alpha大于0的对应位置改为true 填充svm_model对象model(包含nr_class,label数组,b数组,probA&probB数组,nSV数组,l,SV二维数组,sv_indices数组,sv_coef二维数组)并返回 //sv_coef二维数组内元素的放置方式很特别 svm_save_model 保存模型到制定文件中 Prediction: svm_predict svm_predict_values Kernel.k_function //计算预测样本与Support Vectors的Kernel值 用k(k-1)/2个分类器对预测样本进行预测,得出k(k-1)/2个预测类别 使用投票策略,选择预测数最多的那个类别作为最终的预测类别 返回预测类别
2. 各参数文件
1 public class svm_node implements java.io.Serializable 2 { 3 public int index; 4 public double value; 5 }
用于存储单个向量中的单个特征。index是该特征的索引,value是该特征的值。这样设计的好处是,可以节省存储空间,提高计算速度。
1 public class svm_problem implements java.io.Serializable 2 { 3 public int l; 4 public double[] y; 5 public svm_node[][] x; 6 }
用于存储本次运算的所有样本(数据集),及其所属类别。
1 public class svm_parameter implements Cloneable,java.io.Serializable 2 { 3 /* svm_type */ 4 public static final int C_SVC = 0; 5 public static final int NU_SVC = 1; 6 public static final int ONE_CLASS = 2; 7 public static final int EPSILON_SVR = 3; 8 public static final int NU_SVR = 4; 9 10 /* kernel_type */ 11 public static final int LINEAR = 0; 12 public static final int POLY = 1; 13 public static final int RBF = 2; 14 public static final int SIGMOID = 3; 15 public static final int PRECOMPUTED = 4; 16 17 public int svm_type; 18 public int kernel_type; 19 public int degree; // for poly 20 public double gamma; // for poly/rbf/sigmoid 21 public double coef0; // for poly/sigmoid 22 23 // these are for training only 24 public double cache_size; // in MB 25 public double eps; // stopping criteria 26 public double C; // for C_SVC, EPSILON_SVR and NU_SVR 27 public int nr_weight; // for C_SVC 28 public int[] weight_label; // for C_SVC 29 public double[] weight; // for C_SVC 30 public double nu; // for NU_SVC, ONE_CLASS, and NU_SVR 31 public double p; // for EPSILON_SVR 32 public int shrinking; // use the shrinking heuristics 33 public int probability; // do probability estimates 34 35 public Object clone() 36 { 37 try 38 { 39 return super.clone(); 40 } catch (CloneNotSupportedException e) 41 { 42 return null; 43 } 44 } 45 46 }
用于存储模型训练所需设置的参数。
1 public class svm_model implements java.io.Serializable 2 { 3 public svm_parameter param; // parameter 4 public int nr_class; // number of classes, = 2 in regression/one class svm 5 public int l; // total #SV 6 public svm_node[][] SV; // SVs (SV[l]) 7 public double[][] sv_coef; // coefficients for SVs in decision functions (sv_coef[k-1][l]) 8 public double[] rho; // constants in decision functions (rho[k*(k-1)/2]) 9 public double[] probA; // pariwise probability information 10 public double[] probB; 11 public int[] sv_indices; // sv_indices[0,...,nSV-1] are values in [1,...,num_traning_data] to indicate SVs in the training set 12 13 // for classification only 14 15 public int[] label; // label of each class (label[k]) 16 public int[] nSV; // number of SVs for each class (nSV[k]) 17 // nSV[0] + nSV[1] + ... + nSV[k-1] = l 18 };
用于存储训练得到的模型,当然原来的训练参数也必须保留。
3. Cache类
Cache类主要负责运算所涉及的内存的管理,包括申请和释放等。
1 private final int l; 2 private long size; 3 private final class head_t 4 { 5 head_t prev, next; // a cicular list 6 float[] data; 7 int len; // data[0,len) is cached in this entry 8 } 9 private final head_t[] head; 10 private head_t lru_head;
类成员变量。包括:
l:样本总数。
size:指定的全部内存总量。
head_t:单块申请到的内存用class head_t来记录所申请内存,并记录长度。而且通过双向的指针,形成链表,增加寻址的速度。记录所有申请到的内存,一方面便于释放内存,另外方便在内存不够时适当释放一部分已经申请到的内存。
head:类似于变量指针,该指针用来记录程序所申请的内存。
lru_head:双向链表的头。
1 Cache(int l_, long size_) 2 { 3 l = l_; 4 size = size_; 5 head = new head_t[l]; 6 for(int i=0;i<l;i++) head[i] = new head_t(); 7 size /= 4; 8 size -= l * (16/4); // sizeof(head_t) == 16 9 size = Math.max(size, 2* (long) l); // cache must be large enough for two columns 10 lru_head = new head_t(); 11 lru_head.next = lru_head.prev = lru_head; 12 }
构造函数。该函数根据样本数L,申请L 个head_t 的空间。Lru_head 因为尚没有head_t 中申请到内存,故双向链表指向自己。至于size 的处理,先将原来的byte 数目转化为float 的数目,然后扣除L 个head_t 的内存数目。
1 private void lru_delete(head_t h) 2 { 3 // delete from current location 4 h.prev.next = h.next; 5 h.next.prev = h.prev; 6 }
从双向链表中删除某个元素的链接,不删除、不释放该元素所涉及的内存。一般是删除当前所指向的元素。
1 private void lru_insert(head_t h) 2 { 3 // insert to last position 4 h.next = lru_head; 5 h.prev = lru_head.prev; 6 h.prev.next = h; 7 h.next.prev = h; 8 }
在链表后面插入一个新的节点。
1 // request data [0,len) 2 // return some position p where [p,len) need to be filled 3 // (p >= len if nothing needs to be filled) 4 // java: simulate pointer using single-element array 5 int get_data(int index, float[][] data, int len) 6 { 7 head_t h = head[index]; 8 if(h.len > 0) lru_delete(h); 9 int more = len - h.len; 10 11 if(more > 0) 12 { 13 // free old space 14 while(size < more) 15 { 16 head_t old = lru_head.next; 17 lru_delete(old); 18 size += old.len; 19 old.data = null; 20 old.len = 0; 21 } 22 23 // allocate new space 24 float[] new_data = new float[len]; 25 if(h.data != null) System.arraycopy(h.data,0,new_data,0,h.len); 26 h.data = new_data; 27 size -= more; 28 do {int tmp=h.len; h.len=len; len=tmp;} while(false); 29 } 30 31 lru_insert(h); 32 data[0] = h.data; 33 return len; 34 }
该函数保证head_t[index]中至少有len 个float 的内存,并且将可以使用的内存块的指针放在 data 指针中。返回值为申请到的内存。函数首先将head_t[index]从链表中断开,如果head_t[index]原来没有分配内存,则跳过断开这步。计算当前head_t[index]已经申请到的内存,如果不够,释放部分内存,等内存足够后,重新分配内存。重新使head_t[index]进入双向链表。返回值不为申请到的内存的长度,为head_t[index]原来的数据长度h.len。
调用该函数后,程序会计算 的值,并将其填入 data 所指向的内存区域,如果下次index 不变,正常情况下,不用重新计算该区域的值。若index 不变,则get_data()返回值len 与本次传入的len 一致,从get_Q( )中可以看到,程序不会重新计算。从而提高运算速度。
的值,并将其填入 data 所指向的内存区域,如果下次index 不变,正常情况下,不用重新计算该区域的值。若index 不变,则get_data()返回值len 与本次传入的len 一致,从get_Q( )中可以看到,程序不会重新计算。从而提高运算速度。
1 void swap_index(int i, int j) 2 { 3 if(i==j) return; 4 5 if(head[i].len > 0) lru_delete(head[i]); 6 if(head[j].len > 0) lru_delete(head[j]); 7 do {float[] tmp=head[i].data; head[i].data=head[j].data; head[j].data=tmp;} while(false); 8 do {int tmp=head[i].len; head[i].len=head[j].len; head[j].len=tmp;} while(false); 9 if(head[i].len > 0) lru_insert(head[i]); 10 if(head[j].len > 0) lru_insert(head[j]); 11 12 if(i>j) do {int tmp=i; i=j; j=tmp;} while(false); 13 for(head_t h = lru_head.next; h!=lru_head; h=h.next) 14 { 15 if(h.len > i) 16 { 17 if(h.len > j) 18 do {float tmp=h.data[i]; h.data[i]=h.data[j]; h.data[j]=tmp;} while(false); 19 else 20 { 21 // give up 22 lru_delete(h); 23 size += h.len; 24 h.data = null; 25 h.len = 0; 26 } 27 } 28 } 29 }
交换head_t[i] 和head_t[j]的内容,先从双向链表中断开,交换后重新进入双向链表中。然后对于每个head_t[index]中的值,交换其第 i 位和第 j 位的值。这两步是为了在Kernel 矩阵中在两个维度上都进行一次交换。
4. Kernel类
Kernel类是用来进行计算Kernel evaluation矩阵的。
1 // 2 // Kernel evaluation 3 // 4 // the static method k_function is for doing single kernel evaluation 5 // the constructor of Kernel prepares to calculate the l*l kernel matrix 6 // the member function get_Q is for getting one column from the Q Matrix 7 // 8 abstract class QMatrix { 9 abstract float[] get_Q(int column, int len); 10 abstract double[] get_QD(); 11 abstract void swap_index(int i, int j); 12 };
Kernel的父类,抽象类。
1 abstract class Kernel extends QMatrix { 2 private svm_node[][] x; 3 private final double[] x_square; 4 5 // svm_parameter 6 private final int kernel_type; 7 private final int degree; 8 private final double gamma; 9 private final double coef0; 10 11 abstract float[] get_Q(int column, int len); 12 abstract double[] get_QD();
Kernel类的成员变量。
1 Kernel(int l, svm_node[][] x_, svm_parameter param) 2 { 3 this.kernel_type = param.kernel_type; 4 this.degree = param.degree; 5 this.gamma = param.gamma; 6 this.coef0 = param.coef0; 7 8 x = (svm_node[][])x_.clone(); 9 10 if(kernel_type == svm_parameter.RBF) 11 { 12 x_square = new double[l]; 13 for(int i=0;i<l;i++) 14 x_square[i] = dot(x[i],x[i]); 15 } 16 else x_square = null; 17 }
构造函数。初始化类中的部分常量、指定核函数、克隆样本数据(每次数据传入时通过克隆函数来实现,完全重新分配内存)。如果使用RBF 核函数,则计算x_sqare[i]。
1 double kernel_function(int i, int j) 2 { 3 switch(kernel_type) 4 { 5 case svm_parameter.LINEAR: 6 return dot(x[i],x[j]); 7 case svm_parameter.POLY: 8 return powi(gamma*dot(x[i],x[j])+coef0,degree); 9 case svm_parameter.RBF: 10 return Math.exp(-gamma*(x_square[i]+x_square[j]-2*dot(x[i],x[j]))); 11 case svm_parameter.SIGMOID: 12 return Math.tanh(gamma*dot(x[i],x[j])+coef0); 13 case svm_parameter.PRECOMPUTED: 14 return x[i][(int)(x[j][0].value)].value; 15 default: 16 return 0; // java 17 } 18 }
对Kernel类的对象中包含的任意2个样本求kernel evaluation。
1 static double k_function(svm_node[] x, svm_node[] y, 2 svm_parameter param) 3 { 4 switch(param.kernel_type) 5 { 6 case svm_parameter.LINEAR: 7 return dot(x,y); 8 case svm_parameter.POLY: 9 return powi(param.gamma*dot(x,y)+param.coef0,param.degree); 10 case svm_parameter.RBF: 11 { 12 double sum = 0; 13 int xlen = x.length; 14 int ylen = y.length; 15 int i = 0; 16 int j = 0; 17 while(i < xlen && j < ylen) 18 { 19 if(x[i].index == y[j].index) 20 { 21 double d = x[i++].value - y[j++].value; 22 sum += d*d; 23 } 24 else if(x[i].index > y[j].index) 25 { 26 sum += y[j].value * y[j].value; 27 ++j; 28 } 29 else 30 { 31 sum += x[i].value * x[i].value; 32 ++i; 33 } 34 } 35 36 while(i < xlen) 37 { 38 sum += x[i].value * x[i].value; 39 ++i; 40 } 41 42 while(j < ylen) 43 { 44 sum += y[j].value * y[j].value; 45 ++j; 46 } 47 48 return Math.exp(-param.gamma*sum); 49 } 50 case svm_parameter.SIGMOID: 51 return Math.tanh(param.gamma*dot(x,y)+param.coef0); 52 case svm_parameter.PRECOMPUTED: 53 return x[(int)(y[0].value)].value; 54 default: 55 return 0; // java 56 } 57 }
静态方法,对参数传入的任意2个样本求kernel evaluation。主要应用在predict过程中。
1 // 2 // Q matrices for various formulations 3 // 4 class SVC_Q extends Kernel 5 { 6 private final byte[] y; 7 private final Cache cache; 8 private final double[] QD; 9 10 SVC_Q(svm_problem prob, svm_parameter param, byte[] y_) 11 { 12 super(prob.l, prob.x, param); 13 y = (byte[])y_.clone(); 14 cache = new Cache(prob.l,(long)(param.cache_size*(1<<20))); 15 QD = new double[prob.l]; 16 for(int i=0;i<prob.l;i++) 17 QD[i] = kernel_function(i,i); 18 } 19 20 float[] get_Q(int i, int len) 21 { 22 float[][] data = new float[1][]; 23 int start, j; 24 if((start = cache.get_data(i,data,len)) < len) 25 { 26 for(j=start;j<len;j++) 27 data[0][j] = (float)(y[i]*y[j]*kernel_function(i,j)); 28 } 29 return data[0]; 30 } 31 32 double[] get_QD() 33 { 34 return QD; 35 } 36 37 void swap_index(int i, int j) 38 { 39 cache.swap_index(i,j); 40 super.swap_index(i,j); 41 do {byte tmp=y[i]; y[i]=y[j]; y[j]=tmp;} while(false); 42 do {double tmp=QD[i]; QD[i]=QD[j]; QD[j]=tmp;} while(false); 43 } 44 }
Kernel类的子类,用于对C-SVC进行定制的Kernel类。其中构造函数中会调用父类Kernel类的构造函数,并且初始化自身独有的成员变量。
在get_Q函数中,调用了Cache类的get_data函数。想要得到第 i 个变量与其它 len 个变量的Kernel函数值。但是如果取出的缓存中没有全部的值,只有部分的值的话,就需要重新计算一下剩下的那部分的Kernel值,这部分新计算的值会保存到缓存中去。只要不删除掉,以后可以继续使用,不用再重复计算了。
5. Solver类
LibSVM中的Solver类主要是SVM中SMO算法求解拉格朗日乘子的实现。SMO算法的原理可以参考之前的一篇博客:http://www.cnblogs.com/bentuwuying/p/6444516.html。
1 // An SMO algorithm in Fan et al., JMLR 6(2005), p. 1889--1918 2 // Solves: 3 // 4 // min 0.5(alpha^T Q alpha) + p^T alpha 5 // 6 // y^T alpha = delta 7 // y_i = +1 or -1 8 // 0 <= alpha_i <= Cp for y_i = 1 9 // 0 <= alpha_i <= Cn for y_i = -1 10 // 11 // Given: 12 // 13 // Q, p, y, Cp, Cn, and an initial feasible point alpha 14 // l is the size of vectors and matrices 15 // eps is the stopping tolerance 16 // 17 // solution will be put in alpha, objective value will be put in obj 18 // 19 class Solver {
5.1 Solver类的成员变量
1 int active_size; 2 byte[] y; 3 double[] G; // gradient of objective function 4 static final byte LOWER_BOUND = 0; 5 static final byte UPPER_BOUND = 1; 6 static final byte FREE = 2; 7 byte[] alpha_status; // LOWER_BOUND, UPPER_BOUND, FREE 8 double[] alpha; 9 QMatrix Q; 10 double[] QD; 11 double eps; 12 double Cp,Cn; 13 double[] p; 14 int[] active_set; 15 double[] G_bar; // gradient, if we treat free variables as 0 16 int l; 17 boolean unshrink; // XXX 18 19 static final double INF = java.lang.Double.POSITIVE_INFINITY;
Solver类的成员变量。包括:
active_size:计算时实际参加运算的样本数目,经过shrinking处理后,该数目会小于全部样本总数。
y:样本所属类别,+1/-1。
G:梯度,![]() 。
。
alpha_status:拉格朗日乘子的状态,分别是 ,代表内部点(非SV,LOWER_BOUND),错分点(BSV,UPPER_BOUND),和支持向量(SV,FREE)。
,代表内部点(非SV,LOWER_BOUND),错分点(BSV,UPPER_BOUND),和支持向量(SV,FREE)。
alpha:拉格朗日乘子。
Q:核函数矩阵。
QD:核函数矩阵中的对角线部分。
eps:误差极限。
Cp,Cn:正负样本各自的惩罚系数。
p:目标函数中的系数。
active_set:计算时实际参加运算的样本索引。
G_bar:在重建梯度时的中间变量,可以降低重建的计算开销。
l:样本数目。
5.2 Solver类的简单辅助成员函数
1 double get_C(int i) 2 { 3 return (y[i] > 0)? Cp : Cn; 4 }
double get_c(int i):返回对应样本的C值(惩罚系数)。这里对正负样本设置了不同的惩罚系数Cp,Cn。
1 void update_alpha_status(int i) 2 { 3 if(alpha[i] >= get_C(i)) 4 alpha_status[i] = UPPER_BOUND; 5 else if(alpha[i] <= 0) 6 alpha_status[i] = LOWER_BOUND; 7 else alpha_status[i] = FREE; 8 }
void update_alpha_status(int i):更新拉格朗日乘子的状态。
1 boolean is_upper_bound(int i) { return alpha_status[i] == UPPER_BOUND; } 2 boolean is_lower_bound(int i) { return alpha_status[i] == LOWER_BOUND; } 3 boolean is_free(int i) { return alpha_status[i] == FREE; }
boolean is_upper_bound(int i),boolean is_lower_bound(int i),boolean is_free(int i):返回拉格朗日是否在界上。
1 // java: information about solution except alpha, 2 // because we cannot return multiple values otherwise... 3 static class SolutionInfo { 4 double obj; 5 double rho; 6 double upper_bound_p; 7 double upper_bound_n; 8 double r; // for Solver_NU 9 }
static class Solutioninfo:SMO算法求得的解(除了alpha)。
1 void swap_index(int i, int j) 2 { 3 Q.swap_index(i,j); 4 do {byte tmp=y[i]; y[i]=y[j]; y[j]=tmp;} while(false); 5 do {double tmp=G[i]; G[i]=G[j]; G[j]=tmp;} while(false); 6 do {byte tmp=alpha_status[i]; alpha_status[i]=alpha_status[j]; alpha_status[j]=tmp;} while(false); 7 do {double tmp=alpha[i]; alpha[i]=alpha[j]; alpha[j]=tmp;} while(false); 8 do {double tmp=p[i]; p[i]=p[j]; p[j]=tmp;} while(false); 9 do {int tmp=active_set[i]; active_set[i]=active_set[j]; active_set[j]=tmp;} while(false); 10 do {double tmp=G_bar[i]; G_bar[i]=G_bar[j]; G_bar[j]=tmp;} while(false); 11 }
void swap_index(int i, int j):完全交换样本 i 和样本 j 的内容,包括申请的内存的地址。
5.3 Solving the Quadratic Problems
我们可以用一个通用的表达式来表示SMO算法要解决的二次优化问题:

对于这个二次优化问题,最困难的地方在于Q是一个很大的稠密矩阵,难以存储,所以需要采用分解的方式解决,SMO算法就是采用每次选取拉格朗日乘子中的2个来更新,直到收敛到最优解。


5.4 Stopping Criteria
假设存在向量 是(11)式的解,则必然存在实数
是(11)式的解,则必然存在实数 和两个非负向量
和两个非负向量 使得下式成立:
使得下式成立:

其中, 是目标函数的梯度。
是目标函数的梯度。
上面的条件可以被重写为:

进一步,存在b使得
其中,

则目标函数存在最优解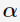 的条件是:
的条件是:

而实际实现过程中,优化迭代的停止条件为:

其中,epsilon是误差极限,tolerance。
5.5 Working Set Selection

1 // return 1 if already optimal, return 0 otherwise 2 int select_working_set(int[] working_set) 3 { 4 // return i,j such that 5 // i: maximizes -y_i * grad(f)_i, i in I_up(alpha) 6 // j: mimimizes the decrease of obj value 7 // (if quadratic coefficeint <= 0, replace it with tau) 8 // -y_j*grad(f)_j < -y_i*grad(f)_i, j in I_low(alpha) 9 10 double Gmax = -INF; 11 double Gmax2 = -INF; 12 int Gmax_idx = -1; 13 int Gmin_idx = -1; 14 double obj_diff_min = INF; 15 16 for(int t=0;t<active_size;t++) 17 if(y[t]==+1) 18 { 19 if(!is_upper_bound(t)) 20 if(-G[t] >= Gmax) 21 { 22 Gmax = -G[t]; 23 Gmax_idx = t; 24 } 25 } 26 else 27 { 28 if(!is_lower_bound(t)) 29 if(G[t] >= Gmax) 30 { 31 Gmax = G[t]; 32 Gmax_idx = t; 33 } 34 } 35 36 int i = Gmax_idx; 37 float[] Q_i = null; 38 if(i != -1) // null Q_i not accessed: Gmax=-INF if i=-1 39 Q_i = Q.get_Q(i,active_size); 40 41 for(int j=0;j<active_size;j++) 42 { 43 if(y[j]==+1) 44 { 45 if (!is_lower_bound(j)) 46 { 47 double grad_diff=Gmax+G[j]; 48 if (G[j] >= Gmax2) 49 Gmax2 = G[j]; 50 if (grad_diff > 0) 51 { 52 double obj_diff; 53 double quad_coef = QD[i]+QD[j]-2.0*y[i]*Q_i[j]; 54 if (quad_coef > 0) 55 obj_diff = -(grad_diff*grad_diff)/quad_coef; 56 else 57 obj_diff = -(grad_diff*grad_diff)/1e-12; 58 59 if (obj_diff <= obj_diff_min) 60 { 61 Gmin_idx=j; 62 obj_diff_min = obj_diff; 63 } 64 } 65 } 66 } 67 else 68 { 69 if (!is_upper_bound(j)) 70 { 71 double grad_diff= Gmax-G[j]; 72 if (-G[j] >= Gmax2) 73 Gmax2 = -G[j]; 74 if (grad_diff > 0) 75 { 76 double obj_diff; 77 double quad_coef = QD[i]+QD[j]+2.0*y[i]*Q_i[j]; 78 if (quad_coef > 0) 79 obj_diff = -(grad_diff*grad_diff)/quad_coef; 80 else 81 obj_diff = -(grad_diff*grad_diff)/1e-12; 82 83 if (obj_diff <= obj_diff_min) 84 { 85 Gmin_idx=j; 86 obj_diff_min = obj_diff; 87 } 88 } 89 } 90 } 91 } 92 93 if(Gmax+Gmax2 < eps || Gmin_idx == -1) 94 return 1; 95 96 working_set[0] = Gmax_idx; 97 working_set[1] = Gmin_idx; 98 return 0; 99 }
其中,第1个 for 循环是在确定工作集的第1个变量 i 。在确定了 i 之后,第2个 for 循环即是为了确定第2个变量 j 的选取。当两者都确定了之后,通过看停止条件来确定是否当前变量已经处在最优解上了,如果是则返回1,如果不是对working_set数组赋值并返回0。
5.6 Maintaining the Gradient
我们可以看到,在每次迭代中,主要操作是找到 ((12)式目标函数中会用到),以及
((12)式目标函数中会用到),以及 (在working set selection和stopping condition中会用到)。这两个主要操作可以合起来一起看待,因为:
(在working set selection和stopping condition中会用到)。这两个主要操作可以合起来一起看待,因为:


在第k次迭代中,我们已经得到了 ,于是便可以得到,用来计算(12)式的目标函数。当第k次迭代的目标函数得到解决后,我们又可以得到 k+1 次的
,于是便可以得到,用来计算(12)式的目标函数。当第k次迭代的目标函数得到解决后,我们又可以得到 k+1 次的 。所以,LibSVM在整个迭代优化过程中都一直维护着梯度数组。
。所以,LibSVM在整个迭代优化过程中都一直维护着梯度数组。
5.7 The Calculation of b
令
(1)当存在 ,有
,有 。为了数值的稳定性,做一个平均处理,
。为了数值的稳定性,做一个平均处理,

(2)当 ,有
,有

则取中值。
1 double calculate_rho() 2 { 3 double r; 4 int nr_free = 0; 5 double ub = INF, lb = -INF, sum_free = 0; 6 for(int i=0;i<active_size;i++) 7 { 8 double yG = y[i]*G[i]; 9 10 if(is_lower_bound(i)) 11 { 12 if(y[i] > 0) 13 ub = Math.min(ub,yG); 14 else 15 lb = Math.max(lb,yG); 16 } 17 else if(is_upper_bound(i)) 18 { 19 if(y[i] < 0) 20 ub = Math.min(ub,yG); 21 else 22 lb = Math.max(lb,yG); 23 } 24 else 25 { 26 ++nr_free; 27 sum_free += yG; 28 } 29 } 30 31 if(nr_free>0) 32 r = sum_free/nr_free; 33 else 34 r = (ub+lb)/2; 35 36 return r; 37 }
5.8 Shrinking
对于(11)式目标函数的最优解中会包含一些边界值 ,这些值在迭代优化的过程中可能就已经成为了边界值了,之后便不再变化。为了节省训练时间,使用shrinking方法去除这些个边界值,从而可以进一步解决一个更小的子优化问题。下面的这2个定理显示,在迭代的最后,只有一小部分变量还在改变。
,这些值在迭代优化的过程中可能就已经成为了边界值了,之后便不再变化。为了节省训练时间,使用shrinking方法去除这些个边界值,从而可以进一步解决一个更小的子优化问题。下面的这2个定理显示,在迭代的最后,只有一小部分变量还在改变。


使用A来表示 k 轮迭代中没有被shrinking的元素集合,从而(11)式目标函数便可以缩减为一个子优化问题:

其中, 是被shrinking的集合。在LibSVM中,通过元素的重排使得始终有
是被shrinking的集合。在LibSVM中,通过元素的重排使得始终有 。
。
当(28)式解决了之后,我们会发现可能会有部分的元素被错误地shrinking了。如果有这种情况发生,那么需要对(11)式原优化问题进行重新求解最优值,而重新求解的起始点即是 ,其中
,其中 是(28)式子问题的最优解,
是(28)式子问题的最优解, 是被shrinking的变量。
是被shrinking的变量。
shrinking的步骤如下:


1 private boolean be_shrunk(int i, double Gmax1, double Gmax2) 2 { 3 if(is_upper_bound(i)) 4 { 5 if(y[i]==+1) 6 return(-G[i] > Gmax1); 7 else 8 return(-G[i] > Gmax2); 9 } 10 else if(is_lower_bound(i)) 11 { 12 if(y[i]==+1) 13 return(G[i] > Gmax2); 14 else 15 return(G[i] > Gmax1); 16 } 17 else 18 return(false); 19 }
通过上述shrinking条件来判断第 i 个变量是否被shrinking。
1 void do_shrinking() 2 { 3 int i; 4 double Gmax1 = -INF; // max { -y_i * grad(f)_i | i in I_up(alpha) } 5 double Gmax2 = -INF; // max { y_i * grad(f)_i | i in I_low(alpha) } 6 7 // find maximal violating pair first 8 for(i=0;i<active_size;i++) 9 { 10 if(y[i]==+1) 11 { 12 if(!is_upper_bound(i)) 13 { 14 if(-G[i] >= Gmax1) 15 Gmax1 = -G[i]; 16 } 17 if(!is_lower_bound(i)) 18 { 19 if(G[i] >= Gmax2) 20 Gmax2 = G[i]; 21 } 22 } 23 else 24 { 25 if(!is_upper_bound(i)) 26 { 27 if(-G[i] >= Gmax2) 28 Gmax2 = -G[i]; 29 } 30 if(!is_lower_bound(i)) 31 { 32 if(G[i] >= Gmax1) 33 Gmax1 = G[i]; 34 } 35 } 36 } 37 38 if(unshrink == false && Gmax1 + Gmax2 <= eps*10) 39 { 40 unshrink = true; 41 reconstruct_gradient(); 42 active_size = l; 43 } 44 45 for(i=0;i<active_size;i++) 46 if (be_shrunk(i, Gmax1, Gmax2)) 47 { 48 active_size--; 49 while (active_size > i) 50 { 51 if (!be_shrunk(active_size, Gmax1, Gmax2)) 52 { 53 swap_index(i,active_size); 54 break; 55 } 56 active_size--; 57 } 58 } 59 }
第1个 for 循环是为了找到 这2个变量。
这2个变量。
因为有时候shrinking策略太过aggressive,所以当对shrinking之后的部分变量的优化问题迭代优化到第一次满足条件 时,便可以对梯度进行重建。于是,接下来的shrinking过程便可以建立在更精确的梯度值上。
时,便可以对梯度进行重建。于是,接下来的shrinking过程便可以建立在更精确的梯度值上。
最后的 for 循环是为了交换两个变量的位置,从而使得参与迭代优化的变量(即没有被shrinking的变量)始终保持在变量数组的最前面的连续位置上。进一步,为了减少交换操作的次数,从而优化计算开销,可以使用以下的trick:从左向右遍历找出需要被shrinking的变量位置 t1,从右向左遍历找出需要参与迭代优化计算的变量位置 t2,交换 t1 和 t2 的位置,然后继续遍历,直到两个遍历的指针相遇。
5.9 Reconstructing the Gradient
一旦(31)式和(32)式满足了,便需要重建梯度向量。因为在优化(28)子问题的时候, 一直都在内存中的,所以在重建梯度时,我们只需要计算
一直都在内存中的,所以在重建梯度时,我们只需要计算 即可。为了减少计算的开销,在迭代计算时,我们可以维护着另一个向量:
即可。为了减少计算的开销,在迭代计算时,我们可以维护着另一个向量:

而对于任意不在 A 集合中的变量 i 而言,有:

而对于上式的计算,包含了两层循环。是先对 i 循环还是先对 j 进行循环,意味着截然不同的Kernel evaluation次数。具体证明如下:

所以,我们具体选择method 1 还是method 2,是要看情况讨论的:

1 void reconstruct_gradient() 2 { 3 // reconstruct inactive elements of G from G_bar and free variables 4 5 if(active_size == l) return; 6 7 int i,j; 8 int nr_free = 0; 9 10 for(j=active_size;j<l;j++) 11 G[j] = G_bar[j] + p[j]; 12 13 for(j=0;j<active_size;j++) 14 if(is_free(j)) 15 nr_free++; 16 17 if(2*nr_free < active_size) 18 svm.info(" WARNING: using -h 0 may be faster "); 19 20 if (nr_free*l > 2*active_size*(l-active_size)) 21 { 22 for(i=active_size;i<l;i++) 23 { 24 float[] Q_i = Q.get_Q(i,active_size); 25 for(j=0;j<active_size;j++) 26 if(is_free(j)) 27 G[i] += alpha[j] * Q_i[j]; 28 } 29 } 30 else 31 { 32 for(i=0;i<active_size;i++) 33 if(is_free(i)) 34 { 35 float[] Q_i = Q.get_Q(i,l); 36 double alpha_i = alpha[i]; 37 for(j=active_size;j<l;j++) 38 G[j] += alpha_i * Q_i[j]; 39 } 40 } 41 }
5.10 迭代优化整体框架


1 void Solve(int l, QMatrix Q, double[] p_, byte[] y_, 2 double[] alpha_, double Cp, double Cn, double eps, SolutionInfo si, int shrinking)
Solver类中最重要的迭代优化函数 Solve 的接口格式。由于这个函数行数太多,下面分段进行剖析。
1 this.l = l; 2 this.Q = Q; 3 QD = Q.get_QD(); 4 p = (double[])p_.clone(); 5 y = (byte[])y_.clone(); 6 alpha = (double[])alpha_.clone(); 7 this.Cp = Cp; 8 this.Cn = Cn; 9 this.eps = eps; 10 this.unshrink = false;
对Solver类的一些成员变量进行初始化。
1 // initialize alpha_status 2 { 3 alpha_status = new byte[l]; 4 for(int i=0;i<l;i++) 5 update_alpha_status(i); 6 }
初始化拉格朗日乘子状态向量值。
1 // initialize active set (for shrinking) 2 { 3 active_set = new int[l]; 4 for(int i=0;i<l;i++) 5 active_set[i] = i; 6 active_size = l; 7 }
初始化需要参与迭代优化计算的拉格朗日乘子集合。
1 // initialize gradient 2 { 3 G = new double[l]; 4 G_bar = new double[l]; 5 int i; 6 for(i=0;i<l;i++) 7 { 8 G[i] = p[i]; 9 G_bar[i] = 0; 10 } 11 for(i=0;i<l;i++) 12 if(!is_lower_bound(i)) 13 { 14 float[] Q_i = Q.get_Q(i,l); 15 double alpha_i = alpha[i]; 16 int j; 17 for(j=0;j<l;j++) 18 G[j] += alpha_i*Q_i[j]; 19 if(is_upper_bound(i)) 20 for(j=0;j<l;j++) 21 G_bar[j] += get_C(i) * Q_i[j]; 22 } 23 }
初始化梯度G,以及为了重建梯度时候节省计算开销而维护的中间变量G_bar。
1 // optimization step 2 3 int iter = 0; 4 int max_iter = Math.max(10000000, l>Integer.MAX_VALUE/100 ? Integer.MAX_VALUE : 100*l); 5 int counter = Math.min(l,1000)+1; 6 int[] working_set = new int[2]; 7 8 while(iter < max_iter) 9 { 10 // show progress and do shrinking 11 12 if(--counter == 0) 13 { 14 counter = Math.min(l,1000); 15 if(shrinking!=0) do_shrinking(); 16 svm.info("."); 17 } 18 19 if(select_working_set(working_set)!=0) 20 { 21 // reconstruct the whole gradient 22 reconstruct_gradient(); 23 // reset active set size and check 24 active_size = l; 25 svm.info("*"); 26 if(select_working_set(working_set)!=0) 27 break; 28 else 29 counter = 1; // do shrinking next iteration 30 } 31 32 int i = working_set[0]; 33 int j = working_set[1]; 34 35 ++iter; 36 37 // update alpha[i] and alpha[j], handle bounds carefully 38 39 float[] Q_i = Q.get_Q(i,active_size); 40 float[] Q_j = Q.get_Q(j,active_size); 41 42 double C_i = get_C(i); 43 double C_j = get_C(j); 44 45 double old_alpha_i = alpha[i]; 46 double old_alpha_j = alpha[j]; 47 48 if(y[i]!=y[j]) 49 { 50 double quad_coef = QD[i]+QD[j]+2*Q_i[j]; 51 if (quad_coef <= 0) 52 quad_coef = 1e-12; 53 double delta = (-G[i]-G[j])/quad_coef; 54 double diff = alpha[i] - alpha[j]; 55 alpha[i] += delta; 56 alpha[j] += delta; 57 58 if(diff > 0) 59 { 60 if(alpha[j] < 0) 61 { 62 alpha[j] = 0; 63 alpha[i] = diff; 64 } 65 } 66 else 67 { 68 if(alpha[i] < 0) 69 { 70 alpha[i] = 0; 71 alpha[j] = -diff; 72 } 73 } 74 if(diff > C_i - C_j) 75 { 76 if(alpha[i] > C_i) 77 { 78 alpha[i] = C_i; 79 alpha[j] = C_i - diff; 80 } 81 } 82 else 83 { 84 if(alpha[j] > C_j) 85 { 86 alpha[j] = C_j; 87 alpha[i] = C_j + diff; 88 } 89 } 90 } 91 else 92 { 93 double quad_coef = QD[i]+QD[j]-2*Q_i[j]; 94 if (quad_coef <= 0) 95 quad_coef = 1e-12; 96 double delta = (G[i]-G[j])/quad_coef; 97 double sum = alpha[i] + alpha[j]; 98 alpha[i] -= delta; 99 alpha[j] += delta; 100 101 if(sum > C_i) 102 { 103 if(alpha[i] > C_i) 104 { 105 alpha[i] = C_i; 106 alpha[j] = sum - C_i; 107 } 108 } 109 else 110 { 111 if(alpha[j] < 0) 112 { 113 alpha[j] = 0; 114 alpha[i] = sum; 115 } 116 } 117 if(sum > C_j) 118 { 119 if(alpha[j] > C_j) 120 { 121 alpha[j] = C_j; 122 alpha[i] = sum - C_j; 123 } 124 } 125 else 126 { 127 if(alpha[i] < 0) 128 { 129 alpha[i] = 0; 130 alpha[j] = sum; 131 } 132 } 133 } 134 135 // update G 136 137 double delta_alpha_i = alpha[i] - old_alpha_i; 138 double delta_alpha_j = alpha[j] - old_alpha_j; 139 140 for(int k=0;k<active_size;k++) 141 { 142 G[k] += Q_i[k]*delta_alpha_i + Q_j[k]*delta_alpha_j; 143 } 144 145 // update alpha_status and G_bar 146 147 { 148 boolean ui = is_upper_bound(i); 149 boolean uj = is_upper_bound(j); 150 update_alpha_status(i); 151 update_alpha_status(j); 152 int k; 153 if(ui != is_upper_bound(i)) 154 { 155 Q_i = Q.get_Q(i,l); 156 if(ui) 157 for(k=0;k<l;k++) 158 G_bar[k] -= C_i * Q_i[k]; 159 else 160 for(k=0;k<l;k++) 161 G_bar[k] += C_i * Q_i[k]; 162 } 163 164 if(uj != is_upper_bound(j)) 165 { 166 Q_j = Q.get_Q(j,l); 167 if(uj) 168 for(k=0;k<l;k++) 169 G_bar[k] -= C_j * Q_j[k]; 170 else 171 for(k=0;k<l;k++) 172 G_bar[k] += C_j * Q_j[k]; 173 } 174 } 175 176 }
迭代优化最重要的循环部分。每间隔若干次迭代进行一次shrinking,使得部分变量不用参与迭代计算。选择工作集合(包含2个拉格朗日乘子),对工作集合进行更新计算操作。具体的更新原理可见paper:《Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines》。更新完工作集合后,再更新梯度G,拉格朗日乘子的状态向量,以及维护的中间变量G_bar。
1 // calculate rho 2 3 si.rho = calculate_rho(); 4 5 // calculate objective value 6 { 7 double v = 0; 8 int i; 9 for(i=0;i<l;i++) 10 v += alpha[i] * (G[i] + p[i]); 11 12 si.obj = v/2; 13 } 14 15 // put back the solution 16 { 17 for(int i=0;i<l;i++) 18 alpha_[active_set[i]] = alpha[i]; 19 } 20 21 si.upper_bound_p = Cp; 22 si.upper_bound_n = Cn; 23 24 svm.info(" optimization finished, #iter = "+iter+" ");
收尾工作。
6. Multi-class classification
LibSVM使用了“one-against-one”的方法实现了多分类。如果有 k 类样本,则需要建立 k(k-1)/2个分类器。
在预测时,用k(k-1)/2个分类器对预测样本进行预测,得出k(k-1)/2个预测类别,使用投票策略,选择预测数最多的那个类别作为最终的预测类别。
7. 参考文献
1. LIBSVM: A Library for Support Vector Machines
2. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines
3. Working Set Selection Using Second Order Information
版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。