PHP写的后台服务,后面出现导致微信小程序使用过程中,安卓用户会出现的一系列问题,而苹果手机确不会出现,排查了一系列原因,是编码原因导致。不要使用记事本用来编辑PHP代码,使用editplus编辑器后解决问题。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
【格式介绍】:
在windows平台下,打开内置的记事本小程序Notepad.exe.打开后,点击【文件】→【另存为】,弹出一个对话框,在最低部有一个"编码"的下拉条。
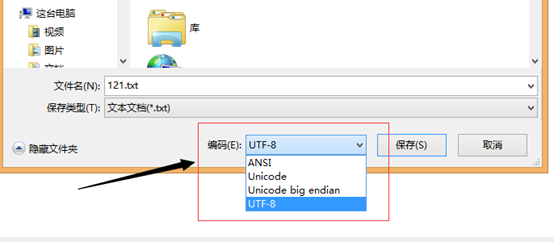
里面有个四个编码选型:ANSI,Unicode,Unicode big endian,UTF-8
UTF-8是unicode的实现方式之一,它规定了字符如何在计算机中存储,传输等。
1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。
2)Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。这个选项用的little endian格式。
3)Unicode big endian编码与上一个选项相对应。两个字节中,高位字节在前。
4)UTF-8编码。
(1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
(2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
详解
Windows早期是ANSI字符集,也就是说一个中文文本,在windows简体中文版显示的是中文,到Windows日文版显示的就不知道是什么东西了。
后来,Windows支持Unicode,但当时大部分软件依然使用ANSI编码,Unicode还不流行,如何推广和支持Unicode?,windows想了个办法,就是允许一个默认语言编码,就是当遇到一个字符串,不是Unicode的时候,就用默认语言编码解释,(在区域和语言选项里修改默认语言)。这个默认语言,在不同Windows语言版本里是不同的,在简体中文版里,是GBK,在繁体中文版本里面,是BIG5,在日文版里是JIS。
而记事本的ANSI编码,就是这种默认编码,所以,一个中文文本,用ANSI编码保存,在中文版里编码是GBK模式保存的时候,到繁体中文版里,用BIG5读取,就全乱套了。
记事本为了解决这个问题,所以支持Unicode,但有一个问题,一段二进制编码,如何确定它是GBK,还是Big5、UTF-8、UTF-16等,记事本的做法是在.txt文本的最前面保存一个标签,这个标签叫"BOM",在读取这个文本时,如果是0xEF 0xBB 0xBF则是UTF-8,如果是0xFF 0xFE,则是UTF-16LE,如果是0xFE 0xFF则UTF-16BE。如果没有这三个东西,那么就是ANSI,使用操作系统的默认语言设置来解析。
一句话建议:涉及兼容性考量时,不要用记事本,用专业的文本编辑器保存为不带 BOM 的 UTF-8。
如果是为了跨平台兼容性,只需要知道,在 Windows 记事本的语境中:
·所谓的「ANSI」指的是对应当前系统 locale 的遗留(legacy)编码。[1]
·所谓的「Unicode」指的是带有 BOM 的小端序 UTF-16。[2]
·所谓的「UTF-8」指的是带 BOM 的 UTF-8。[3]
GBK 等遗留编码最麻烦,所以除非你知道自己在干什么否则不要再用了。
UTF-16 理论上其实很好,字节序也标明了,但 UTF-16 毕竟不常用。
UTF-8 本来是兼容性最好的编码但 Windows 偏要加 BOM 于是经常出问题。
所以,跨平台兼容性最好的其实就是不用记事本。
建议用 Notepad++ 等正常的专业文本编辑器保存为不带 BOM 的 UTF-8。
另外,如果文本中所有字符都在 ASCII 范围内,那么其实,记事本保存的所谓的「ANSI」文件,和 ASCII 或无 BOM 的 UTF-8是一样的。
阮一峰那篇〈字符编码笔记:ASCII,Unicode和UTF-8〉的确很有名,但从那篇文章能看出来他其实还是没完全搞清楚 Unicode和 UTF-8 的关系。他依旧被 Windows 的混乱措词误导。事实上,几年前我读完他那篇文章之后依旧一头雾水,最终还是自己看维基百科看明白的。
BOM 介绍
http://baike.baidu.com/link?url=IkDPo2LgL7zL3UwtzKDMZ0fpG6NHE9kpkeYbl93WDh7VNkkSI1rGGbVGc6GUc6QmOj59_xkQ0ft8UrTQFvcuKfy7_rIrgzRUuyZetw9_CTu
(字节顺序标记(ByteOrderMark))
BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码。
中文名
BOM
外文名
ByteOrderMark
实 质
字节顺序标记
BOM —— Byte Order Mark,中文名译作"字节顺序标记"。在这里找到一段关于 BOM 的说明:
在UCS 编码中有一个叫做 "Zero Width No-Break Space" ,中文译名作"零宽无间断间隔"的字符,它的编码是 FEFF。而 FFFE 在 UCS 中是不存在的字符,所以不应该出现在实际传输中。UCS 规范建议我们在传输字节流前,先传输字符 "Zero Width No-Break Space"。这样如果接收者收到 FEFF,就表明这个字节流是 Big-Endian 的;如果收到FFFE,就表明这个字节流是 Little- Endian 的。因此字符 "Zero Width No-Break Space" ("零宽无间断间隔")又被称作 BOM。
UTF-8 不需要 BOM 来表明字节顺序,但可以用 BOM 来表明编码方式。字符 "Zero Width No-Break Space" 的 UTF-8 编码是 EF BB BF。所以如果接收者收到以 EF BB BF 开头的字节流,就知道这是 UTF-8编码了。Windows 就是使用 BOM 来标记文本文件的编码方式的。
字符U+FEFF如果出现在字节流的开头,则用来标识该字节流的字节序,是高位在前还是低位在前。如果它出现在字节流的中间,则表达零宽度非换行空格的意义,用户看起来就是一个空格。从Unicode3.2开始,U+FEFF只能出现在字节流的开头,只能用于标识字节序,就如它的名称——字节序标记——所表示的一样;除此以外的用法已被舍弃。取而代之的是,使用U+2060来表达零宽度无断空白。
类似WINDOWS自带的记事本等软件,在保存一个以UTF-8编码的文件时,会在文件开始的地方插入三个不可见的字符(0xEF 0xBB 0xBF,即BOM)。它是一串隐藏的字符,用于让记事本等编辑器识别这个文件是否以UTF-8编码。对于一般的文件,这样并不会产生什么麻烦。但对于 PHP来说,BOM是个大麻烦。
PHP并不会忽略BOM,所以在读取、包含或者引用这些文件时,会把BOM作为该文件开头正文的一部分。根据嵌入式语言的特点,这串字符将被直接执行(显示)出来。由此造成即使页面的 top padding 设置为0,也无法让整个网页紧贴浏览器顶部,因为在html一开头有这3个字符呢!
不同编码的字节顺序标记的表示
编辑
|
编码 |
表示 (十六进制) |
表示 (十进制) |
|
EF BB BF |
239 187 191 |
|
|
UTF-16(大端序) |
FE FF |
254 255 |
|
UTF-16(小端序) |
FF FE |
255 254 |
|
UTF-32(大端序) |
00 00 FE FF |
0 0 254 255 |
|
UTF-32(小端序) |
FF FE 00 00 |
255 254 0 0 |
|
2B 2F 76和以下的一个字节:[ 38 | 39 | 2B | 2F ] |
43 47 118和以下的一个字节:[ 56 | 57 | 43 | 47 ] |
|
|
en:UTF-1 |
F7 64 4C |
247 100 76 |
|
en:UTF-EBCDIC |
DD 73 66 73 |
221 115 102 115 |
|
en:Standard Compression Scheme for Unicode |
0E FE FF |
14 254 255 |
|
en:BOCU-1 |
FB EE 28及可能跟随着FF |
251 238 40及可能跟随着255 |
|
GB-18030 |
84 31 95 33 |
132 49 149 51 |