六房间地址:https://www.6.cn/
方式一:通过浏览器自带开发工具进行查看抓取
1、打开浏览器。进入六房间网页,点击小视频。F12打开开发工具,打开Network,刷新网页后,可以看到,在Network—>Headers中可以查看到请求的URL。

2、在Network—>Preview中可以查看到url请求到JSON文件。
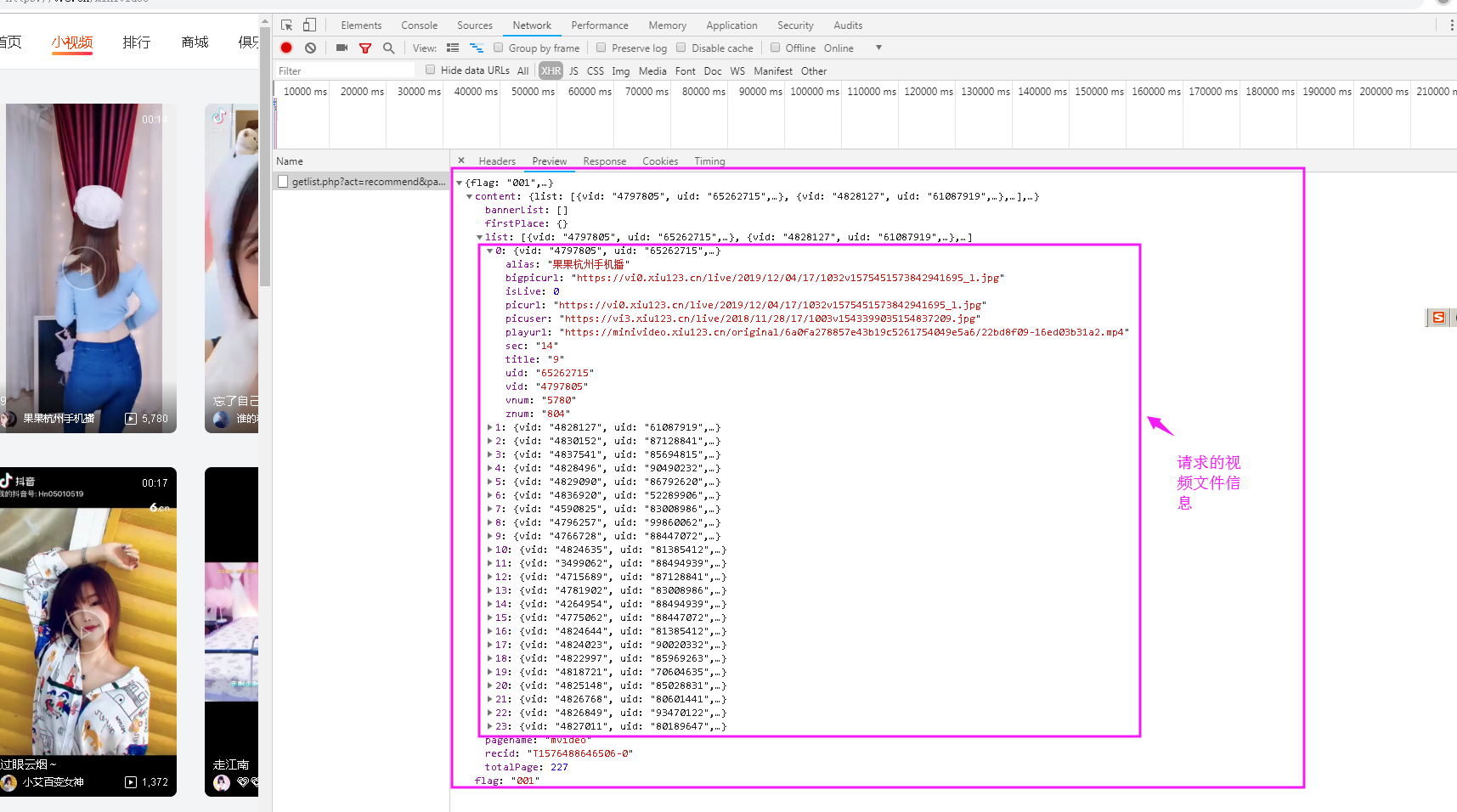
还可以通过把URL地址:https://v.6.cn/minivideo/getlist.php?act=recommend&page=1&pagesize=20 新打开一个浏览器页面进行查看。可以看到获得的数据是为json数据。

3、在获得URL和json数据后,我们就可以编写代码进行小视频的爬取了。
import requests
def Video_URL():
'''请求url地址,得到网页数据,并且进行网页数据的提取(json)'''
url="https://v.6.cn/minivideo/getlist.php?act=recommend&page=1&pagesize=20"
response=requests.get(url).json()
print(response)
#获取每个小视频的标题和播放URl
data=response['content']['list']
for i in data:
title=i['title']
palyur=i['playurl']
Video_Downloads(title,palyur)
def Video_Downloads(title,palyurl):
response=requests.get(palyurl)
#在py执行文件同路径下,建一个video的文件夹,用于存放小视频文件。文件保存 a 文件追加 进制文件读写
with open('video/{}.mp4'.format(title),'ab')as f:
f.write(response.content)
print('正在下载{}……'.format(title))
Video_URL()
以上代码是获取一页的小视频的代码,调整修改下可获取多页小视频:
import requests
def Video_URL(page):
'''请求url地址,得到网页数据,并且进行网页数据的提取(json)'''
url="https://v.6.cn/minivideo/getlist.php?act=recommend&page={}&pagesize=20".format(page)
response=requests.get(url).json()
print(response)
#获取每个小视频的标题和播放URl
data=response['content']['list']
for i in data:
title=i['title']
palyur=i['playurl']
Video_Downloads(title,palyur)
def Video_Downloads(title,palyurl):
response=requests.get(palyurl)
#在py执行文件同路径下,建一个video的文件夹,用于存放小视频文件。文件保存 a 文件追加 进制文件读写
with open('video/{}.mp4'.format(title),'ab')as f:
f.write(response.content)
print('正在下载{}……'.format(title))
for page in range(1,20):
'''获取多页小视频'''
Video_URL(page)
方式二:通过抓包工具Fiddler来进行抓包分析获取url和json数据。
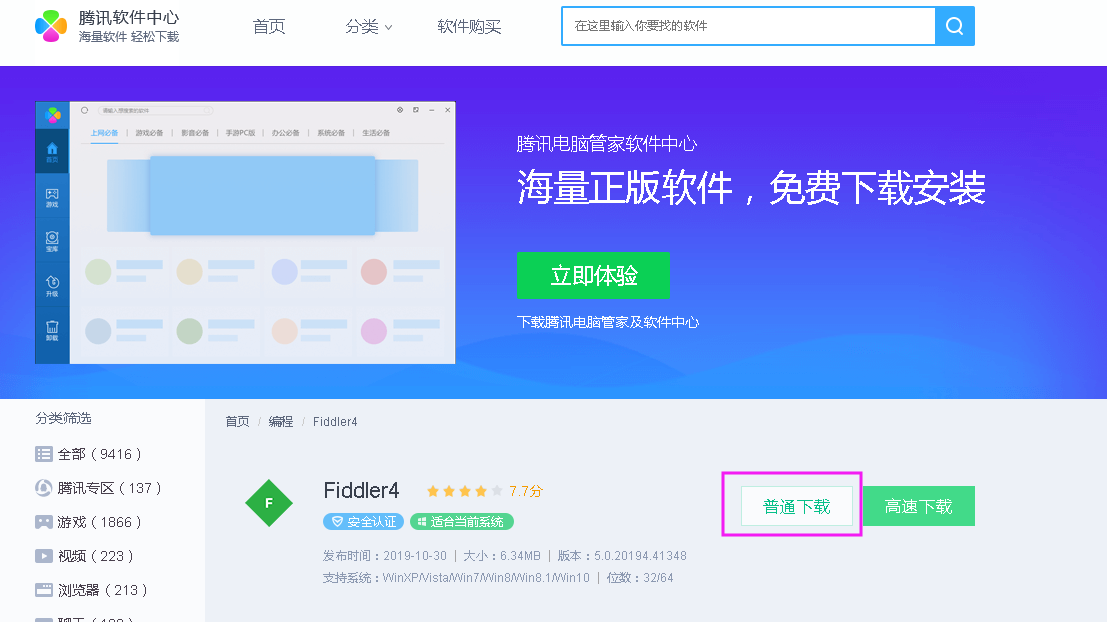
1、下载fiddler工具包。
官网下载https://www.telerik.com/download/fiddler(版本为英文版 fidder4)
汉化版下载:http://soft.huweishen.com/soft/302.html(直接是一个安装包,解压就可以用)
腾讯软件下载地址:https://pc.qq.com/detail/10/detail_3330.html
fiddler配置:(因为涉及ssl)
Tools—>"options",

https设置:
勾选后需要安装安全证书,如果是win 7中不会提示安装安全证书,会报错:creation of the root certificate was not successful
解决办法参考:fiddler报错:creation of the root certificate was not successful 证书安装不成功

connections设置:监听端口
将Fiddler listens on port设为8888,勾选Allow remote computers to connect

代理设置完成,重启Fiddler配置生效。
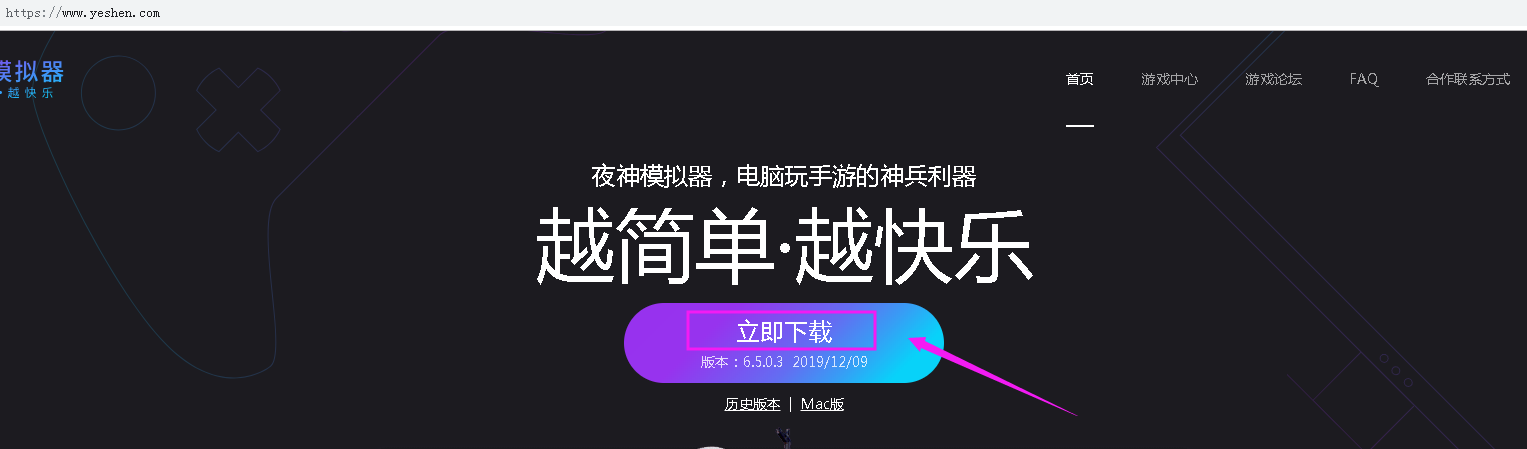
2、通过夜神模拟器来进行抓包分析。
夜神模拟器下载:https://www.yeshen.com/
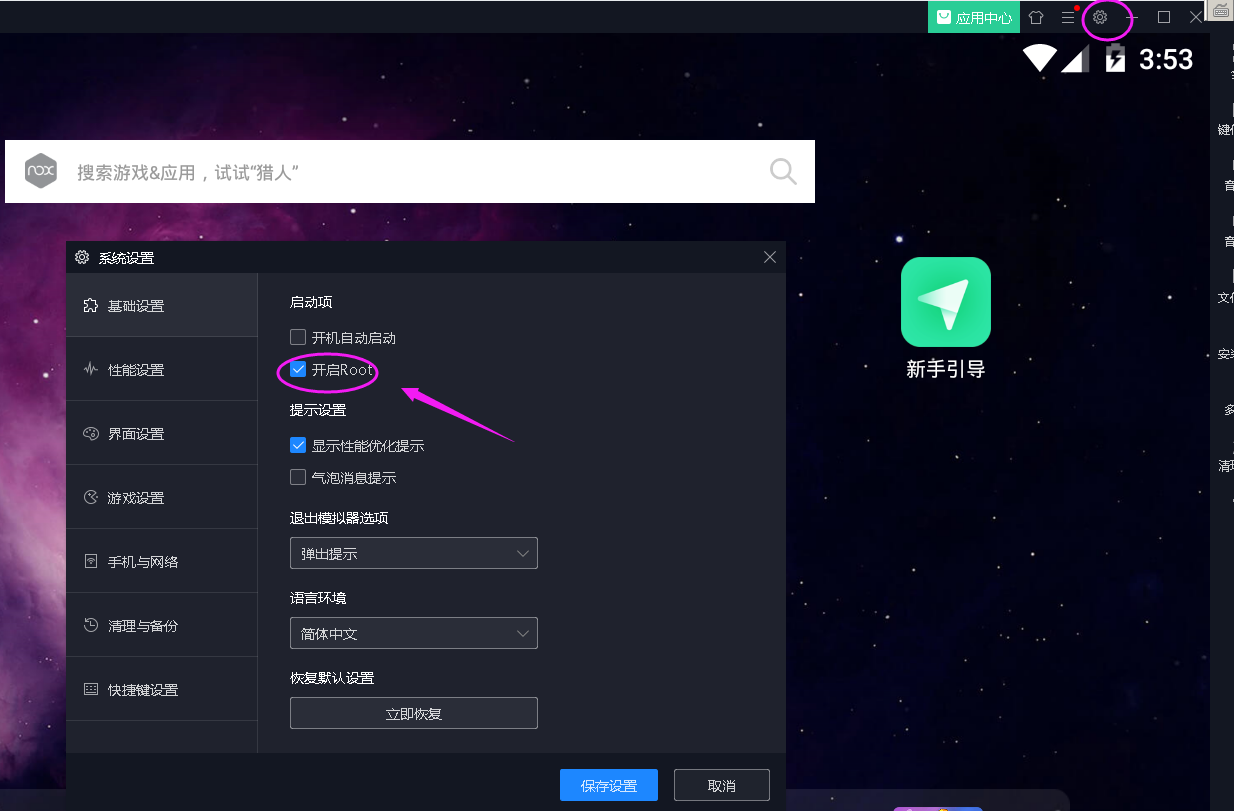
安装后夜神模拟器配置:
①开启root权限
②设置代理

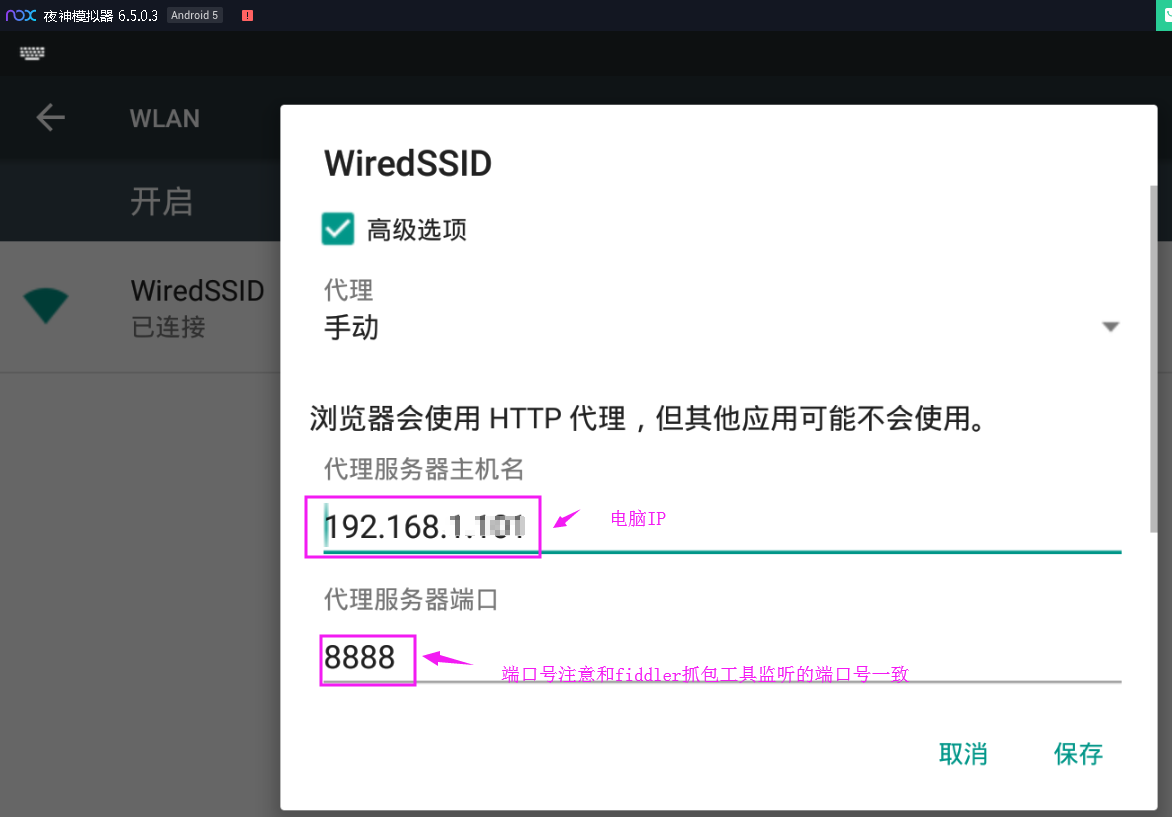
鼠标左键长按,打开修改网络

代理选择“手动”,代理服务器主机名填写电脑的ip就行了(windows系统可用ipconfig查看),端口注意和fiddler·设置的端口号保持一致。
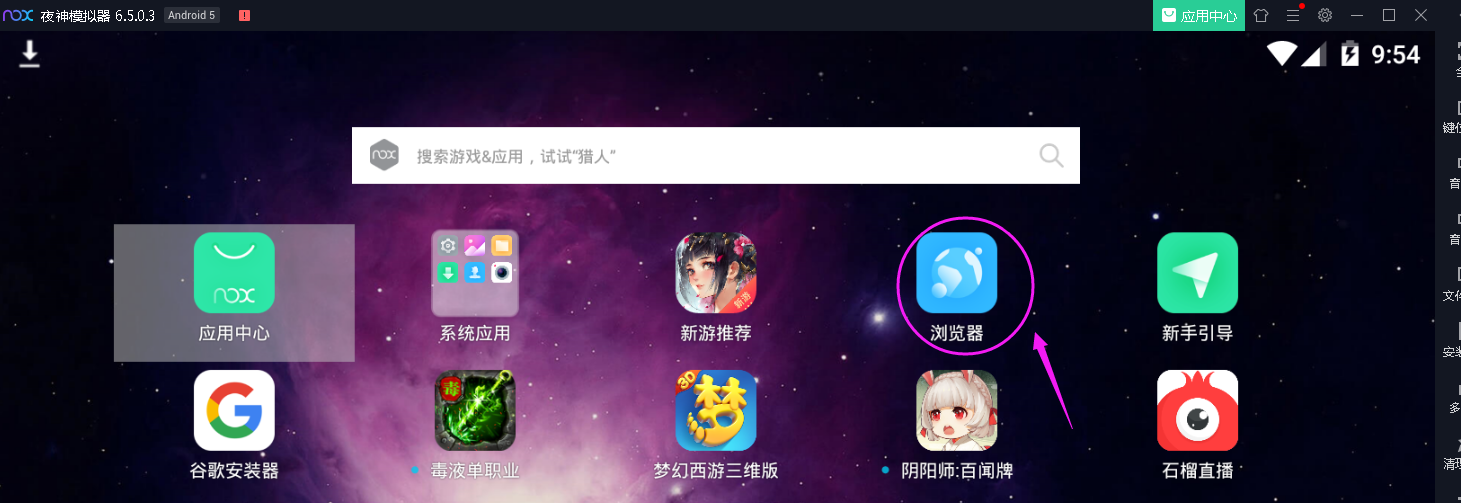
③给夜神模拟器安装https证书
打开浏览器
在地址栏输入:http://ip地址:端口。点击![]() 进行下载。
进行下载。
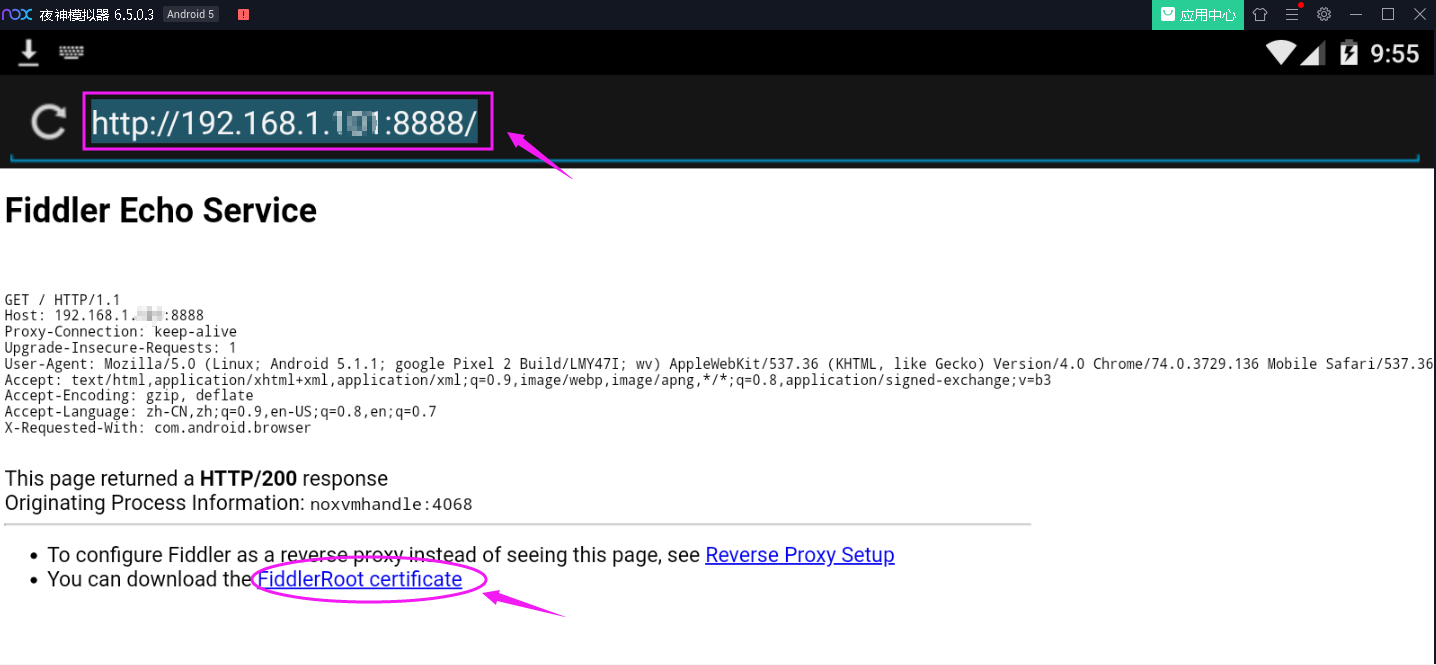
点击下载进行安装。出现
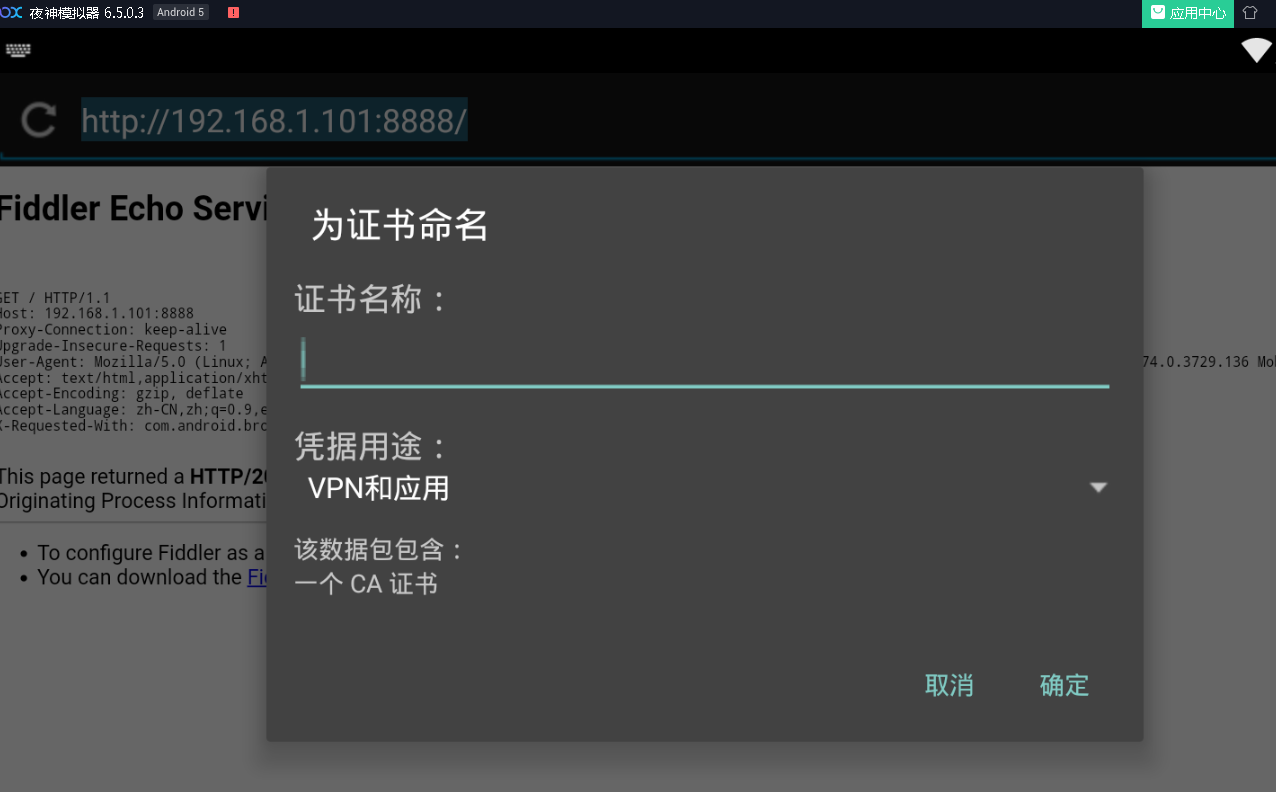
凭证 用途如果两个都不知道怎么使用的话,那么就都安装。
在fiddler和夜神模拟器配置好的情况下就可以进行抓取数据。例如
抓取到的url地址为:https://v.6.cn/coop/mobile/index.php?act=recommend&padapi=minivideo-getlist.php&page=1
把该地址在浏览器中打开,可以看到是为json的数据格式:

python代码如下:
import requests
def Video_URL(page):
'''请求url地址,得到网页数据,并且进行网页数据的提取(json)'''
url="https://v.6.cn/coop/mobile/index.php?act=recommend&padapi=minivideo-getlist.php&page={}".format(page)
response=requests.get(url).json()
print(response)
#获取每个小视频的标题和播放URl
data=response['content']['list']
for i in data:
title=i['title']
palyur=i['playurl']
Video_Downloads(title,palyur)
def Video_Downloads(title,palyurl):
response=requests.get(palyurl)
#在py执行文件同路径下,建一个video的文件夹,用于存放小视频文件。文件保存 a 文件追加 进制文件读写
with open('video/{}.mp4'.format(title),'ab')as f:
f.write(response.content)
print('正在下载{}……'.format(title))
for page in range(1,20):
Video_URL(page)