三剑客之awk
第1章 awk简介
1.1 awk简介
- 一种名字怪异的语言。
- 模式扫描和处理。处理文本流,水流。
awk不仅仅是linux系统中的一个命令,而且是一种编程语言,可以用来处理数据和生成报告。
处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入,awk可以
在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。这里主要讲解
awk命令行的运用。
学完本章你会了解:
- 域(字段)与记录
- 模式与匹配
- 基本的awk执行过程
- awk常用内置变量(预定义变量)
- awk数组(工作中比较常用)
还有一些其他awk用法:(这里不作介绍)
- awk语法:循环,条件
- awk常用函数:print
- 向awk传递参数
- awk引用shell变量
- awk编程
1.2 awk环境简介
[root@linux-node1 ~]# cat /etc/redhat-release
CentOS release 6.6 (Final)
[root@linux-node1 ~]# uname -r
2.6.32-504.el6.x86_64
[root@linux-node1 ~]# awk --version
GNU Awk 3.1.7
[root@linux-node1 ~]# which awk
/bin/awk
#/bin下和/sbin下的命令区别:
/bin : commands in this dir are all system installed user commands 系统的一些指令
/sbin: commands in this dir are all system installed super user commands 超级用户指令 系统管理命令,这里存放的是系统管理员使用的管理程序
/usr/bin: user commands for applications 后期安装的一些软件的运行脚本
/usr/sbin: super user commands for applications 超级用户的一些管理程序
1.3 awk的格式
awk指令是由模式,动作,或者模式和动作的组合组成。
模式既pattern,可以类似理解成sed的模式匹配,可以由表达式组成,也可以是两个正斜杠之间的正则表达式。比如NR=1,这就是模式,可以把他理解为一个条件。
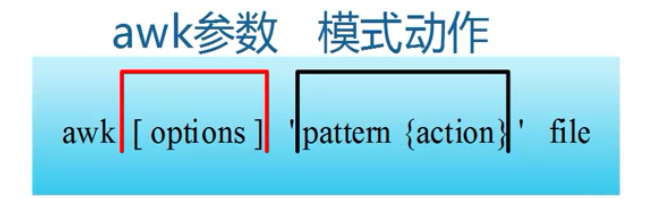
动作即action,是由在大括号里面的一条或多条语句组成,语句之间用分号隔开。如awk使用格式:
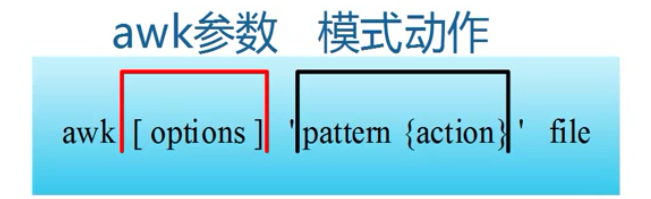
图1-1 awk命令行格式
awk处理的内容可以来自标准输入(<),一个或多个文本文件或管道。
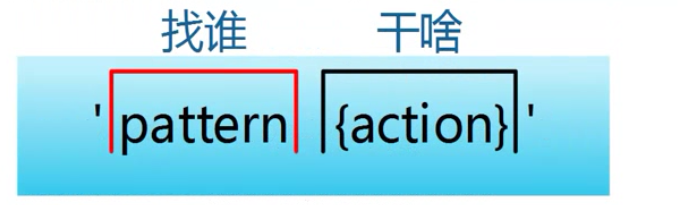
图1-2 awk模式动作解释图
pattern既模式,也可以理解为条件,也叫找谁,你找谁?高矮,胖瘦,男女?都是条件,既模式。
action 既动作,可以理解为干啥,找到人之后你要做什么。
1.4 awk执行过程
在深入了解awk前,我们需要知道awk如何处理文件的。
示例1-1 示例文件的创建
[root@linux-node1 ~]# mkdir -p /server/files/
[root@linux-node1 ~]# head /etc/passwd > /server/files/awkfile.txt
[root@linux-node1 ~]# cat /server/files/awkfile.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
[root@linux-node1 ~]# awk 'NR>=2{print $0}' /server/files/awkfile.txt
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
[root@linux-node1 ~]# awk 'NR>=2{print NR,$0}' /server/files/awkfile.txt
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
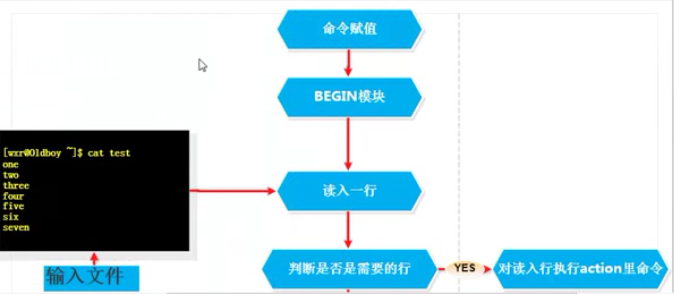
awk是通过一行一行的处理文件,这条命令中包含模式部分(条件)和动作部分(动作),awk将处理模式指定的行。
小结awk执行过程:
a)awk读入第一行内容
b)判断符合模式中的条件(NR>=2)
l 如果匹配默认则执行对应的动作({print $0})
l 如果不匹配条件,继续读取下一行
c))继续读取下一行
d)重复过程a-c,直到读取到最后一行(EOF:end of file)
1.5 区域和记录
|
名称 |
含义 |
|
field |
域,区域,字段 |
|
record |
记录,默认一整行 |
eg:$1,$2,$3,$NF
$0: 整行,一个记录
$ 取 引用
1.5.1 字段(区域)
每条记录都是由多个字段(field)组成的,默认情况下之间的分隔符是由空白符(即空格或制表符)来分隔,并且将分隔符记录在内置变量FS中。每行记录的字段数保存在awk的内置变量NF中。
图1-4 awk区域分隔符
awk使用内置变量FS来记录字段分隔符的内容,可以通过BEGIN语句来更改,也可以在命令行上通过-F参数来更改,下面通过示例来加强学习。
示例1-3 FS演示文件生成
[root@linux-node1 ~]# awk -F ":" 'NR>=2&&NR<=5{print $1,$3}' /server/files/awkfile.txt
bin 1
daemon 2
adm 3
lp 4
1.5.2记录
awk对每个要处理的输入数据人为都是具有格式和结构的,而不仅仅是一堆字符串。默认情况下,每一行内容都成为一条记录,并以换行符结束。
² 默认情况 -一行==一个记录,每行都是一个记录。
² RS ==》 record separator 每个记录读入的时候的分隔符。
² NR==》 number of record 行号,记录的数。awk当前处理着的,记录的数。
² ORS==》 output record separate 输出食肉的分隔符
awk使用内置变量来存放记录分隔符,RS表示的是输入的记录分隔符,这个值也可以以特定的方式修改。
前面我们讲到过的$0,awk使用$0来表示整条记录。记录分隔符 保存在RS变量中。另外awk对每一行的记录号都有一个内置变量NR来保存,每处理完一条记录NR的值就会自动+1.
下面通过示例来加强一下什么是记录,记录分隔符。
示例1-5 NR记录行号
[root@linux-node1 files]# awk '{print NR,$0}' awkfile.txt
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
示例1-6 RS记录分隔符
#以/为分隔符记录一行
[root@linux-node1 files]# awk 'BEGIN{RS="/"}{print NR,$0}' awkfile.txt
1 root:x:0:0:root:
2 root:
3 bin
4 bash
bin:x:1:1:bin:
5 bin:
6 sbin
7 nologin
daemon:x:2:2:daemon:
8 sbin:
9 sbin
10 nologin
adm:x:3:4:adm:
11 var
12 adm:
13 sbin
14 nologin
lp:x:4:7:lp:
15 var
16 spool
17 lpd:
18 sbin
19 nologin
#以:为分隔符记录一行
[root@linux-node1 files]# awk 'BEGIN{RS=":"}{print NR,$0}' awkfile.txt
1 root
2 x
3 0
4 0
5 root
6 /root
7 /bin/bash
bin
8 x
9 1
10 1
11 bin
12 /bin
13 /sbin/nologin
daemon
14 x
15 2
16 2
17 daemon
18 /sbin
19 /sbin/nologin
adm
20 x
21 3
22 4
23 adm
24 /var/adm
25 /sbin/nologin
lp
26 x
27 4
28 7
29 lp
30 /var/spool/lpd
31 /sbin/nologin
awk 眼中的文件,从头到尾一段连续的字符串,恰巧中间有些 (回车换行符)
示例1-7 RS为空值
#RS为空值的时候将指定行输出为一行
[root@linux-node1 files]# awk 'BEGIN{RS=""}{print NR,$1,$2,$3}' awkfile.txt
说明:
在行首打印输出记录号,并打印出每一行$0的内容
企业案例1:计算文件中每个单词的重复数量
[root@linux-node1 files]# sed -ri.bak 's#[:/0-9]+# #g' awkfile.txt
1)单词弄成一列(排队)
其中 -o 表示“only-matching 精确匹配
[root@linux-node1 files]# egrep -o "[a-zA-z]+" awkfile.txt |sort| uniq -c|sort -r
5 x
5 sbin
4 nologin
4 bin
3 root
3 adm
2 var
2 lp
2 daemon
1 spool
1 lpd
1 bash
2)统计
[root@linux-node1 files]# awk 'BEGIN{RS="() | "}{print $0}' awkfile.txt|sort |uniq -c|sort -rn
5 x
5 sbin
4 nologin
4 bin
3 root
3 adm
2 var
2 lp
2 daemon
1 spool
1 lpd
1 bash
1
企业案例2: 统计文件中每个字母的重复数量
记录小结:
- 大象放冰箱分几步?打开冰箱,把大象放进去,关闭冰箱门。
- 多用NR,NF,$数字,配合你进行调试awk命令。
- NR存放着每个记录的号(行号)读取新行时候会自动+1
- RS是记录的分隔符,简单理解就是可以指定每个记录的结尾标志。
- (用RS替换 )
- RS作用就是表示一个记录的结束。
- FS标识着每个区域的结束。
1.6 模式匹配
1.6.1 正则表达式
awk支持的正则表达式元字符
|
元字符 |
功能 |
示例 |
解释 |
|
^ |
字符串开头 |
/^cool/ |
匹配所有以cool开头的字符串 |
|
$ |
字符串结尾 |
/cool$/ |
匹配所有以cool结尾的字符串 |
|
. |
匹配任意单个字符 (包括回车符) |
/c..l/ |
匹配字母c,然后两个任意字符,再以l结尾的行,比如ckk1,c@#1等 |
|
* |
匹配0个或多个前导字符 |
/a*cool/ |
匹配0个或多个a之后紧跟着cool的行,比如cool,aaacool |
|
+ |
重复一次或一次以上 |
/a+b/ |
匹配一个或多个a加b的行 |
|
? |
匹配0个或一个前导字符 |
/a?b/ |
匹配b或ab的行 |
|
[] |
匹配指定字符组内的任一个字符 |
/^[abc]/ |
匹配以字母a或b或c开头的行 |
|
[^] |
匹配不在指定字符组 |
/^[^abc]/ |
匹配不以字母a或b或c开头的行 |
|
x{m} |
x重复m次 x重复至少m次 x重复至少m次,但不超过n次 需要指定参数:--posix或者--re-interval |
/(cool){5} |
需要注意的一点是,cool加括号或不加括号的区别,x可以使字符串也可以只是一个字符,所有/cool{5}/表示匹配coo再加上5个l,即coolllll, ^(cool){2,}则表示匹配coolcool, coolcoolcool等 |
|
x{m,} |
/(cool){2,}/ |
||
|
/(cool){5,6}/ |
正则表达式的运用,默认是在行内查找匹配的字符串,若有匹配则执行action操作,但是有时候仅需要固定的列来匹配指定的正则表达式,比如:$3这一列查找匹配tom的行,这样就需要另外两个匹配操作符:
~:用于对记录或字段的表达式进行(匹配)
!~:用于表达与~想法的意思。(不匹配)
#匹配 第五列以l或者a开头的所有行 ,这里(l|a) 可以换成[al]
[root@linux-node1 files]# awk '$3~/^(l|a)/{print $0}' awkfile.txt
adm x adm var adm sbin nologin
lp x lp var spool lpd sbin nologin
#取eth0 ip
[root@linux-node1 files]# ifconfig eth0| awk -F "[ :]+" 'NR==2{print $4}'
10.0.0.7
[root@linux-node1 files]# ifconfig eth0| awk -F "addr:| Bcast:" 'NR==2{print $2}'
10.0.0.7
[root@linux-node1 files]# echo "-----=====1#######2"
-----=====1#######2
[root@linux-node1 files]# echo "-----=====1#######2"|grep "[-=#]"
-----=====1#######2
[root@linux-node1 files]# echo "-----=====1#######2"|grep -o "[-=#]"
-
-
-
-
-
=
=
=
=
=
#
#
#
#
#
#
#
[root@linux-node1 files]# echo "-----=====1#######2"|egrep -o "[-=#]+"
-----=====
#######
#匹配o出现一次或者两次的行打印第一列和最后一列
[root@linux-node1 files]# awk --posix '$1~/o{1,2}/{print NR,$1,$NF}' awkfile.txt
1 root bash
3 daemon nologin
1.6.2比较表达式
示例1-18
[root@linux-node1 files]# awk 'NR>=2&&NR<=5{print NR,$0}' awkfile.txt
2 bin x bin bin sbin nologin
3 daemon x daemon sbin sbin nologin
4 adm x adm var adm sbin nologin
5 lp x lp var spool lpd sbin nologin
1.6.3范围模式
awk ‘/start pos/,/end pos/{print $0} ‘ test.txt
awk ‘/start pos/,NR==XXX{print $0}’ passwd.oldboy
范围模式的时候,范围条件的时候,表达式必须匹配一行,
[root@linux-node1 files]# awk 'NR==2,NR==5{print NR,$1,$3}' awkfile.txt
2 bin bin
3 daemon daemon
4 adm adm
5 lp lp
[root@linux-node1 files]# awk 'NR==2,NR==5{print NR,$0}' awkfile.txt
2 bin x bin bin sbin nologin
3 daemon x daemon sbin sbin nologin
4 adm x adm var adm sbin nologin
5 lp x lp var spool lpd sbin nologin
[root@linux-node1 files]# awk 'NR==2,NR<=5{print NR,$0}' awkfile.txt
2 bin x bin bin sbin nologin
1.6.4企业案例:取出常用服务端口号
ftp http https mysql ssh 端口号 /etc/services 文件
[root@linux-node1 files]# awk -F "[ /]+" '$1~/ftp|https|mysql|ssh)$/{print $1,$2}' /etc/services|uniq
小结:
- 模式===》条件
- 正则表达式
- 条件表达式(NR>=2 NR==2)
- 范围表达式
- (NR==2,NR==5)
- /正则表达式-开始/,/正则结束/
- $1~/正则表达式-开始/,$3~/正则结束/ 行,记录。
- 区域:FS刀分隔的,FS区域分隔符
- 记录:RS刀分隔的,RS记录分隔符
- FS===>NF 区域的数量
- RS===>NR 记录号,随着记录的增加NR自动+1
1.7 awk结构的回顾
1.7.1 BEGIN模块
BEGIN模式之前我们有在示例中提到,自定义变量,给内容变量赋值等,都是用过。需要注意的是BEGIN模式后面要接跟一个action操作块,包含在大括号内。awk必须在对输入文件进行任何处理前先执行BEGIN定义的action操作块。我们可以不要任何输入文件,就可以对BEGIN模块进行测试,因为awk需要先执行完BEGIN模式,菜对输入文件做处理。BEGIN模式常常被用来修改内置变量ORS,RS,FS,OFS等的值。
示例1-25
[root@linux-node1 files]# awk 'BEGIN{print "this is begin! and thiscommand donnot have file"}'
this is begin!
and thiscommand donnot have file
说明:
没有文件awk依旧可以处理BEGIN模式下的操作块。
1.7.2 END模块
END 在awk读取完所有的文件的时候
awk编程思想:
1.先处理,最后再END模块输出。
与BEGIN模式相对于的END模式,格式一样,但是END模式仅在awk处理完所有输入行后才进行处理。并且在END模式下awk不匹配任何输入行。
1.7.3 总结awk执行过程
1.读入一行
2.判断是否是需要的行 条件$3>15 满足大于15 执行action :print
3.不满足条件重复1,2步骤
1.7.4 企业案例3:统计文件里面的空行数量
[root@linux-node1 files]# grep -c "^$" /etc/services
16
[root@linux-node1 files]# awk '/^$/{a=a+1;print a}' /etc/services
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[root@linux-node1 files]# awk '/^$/{a=a+1}END{print a}' /etc/services
16
head -20 /etc/passwd >awkfile2.txt
面试题:awkfile2.txt 里面 以:为分隔符,区域3大于15行,一共有多少个?
[root@linux-node1 files]# awk -F ":" '$3>15{print $0}' awkfile2.txt
nobody:x:99:99:Nobody:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin
vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin
rtkit:x:499:497:RealtimeKit:/proc:/sbin/nologin
#计算一次,输出一次
[root@linux-node1 files]# awk -F ":" '$3>15{a=a+1;print a}' awkfile2.txt
1
2
3
4
5
6
#处理完文件以后再输出a 这里a=a+1 可以用a++代替
[root@linux-node1 files]# awk -F ":" '$3>15{a=a+1;}END{print a}' awkfile2.txt
6
企业面试题5:1+.....+100 1加到100的值,用awk实现
root@linux-node1 files]# seq 100 > test.txt
[root@linux-node1 files]# cat test.txt |awk '{a+=$0}END{print a}'
5050
[[root@linux-node1 files]# awk 'a=a+$0;END{print a}' test.txt |sed -n '$p'
5050
1.7.4 企业案例4:
找出环境变量$PATH中,所有只有三个任意字符的命令,例如tee,并将他们重定向到command.txt中,要求一行显示1个,并在文件尾部统计他们的个数.
[root@linux-node1 files]# find $(echo $PATH|tr ":" " ") -type f -name "???"| awk '{a++}END{print "result:"a}'
find: `/root/bin': No such file or directory
result:75
通配符:用来匹配文件名的。{}字符序列
正则表达:字符串
1.7.5 总结awk执行过程
[root@linux-node1 files]# awk -F ":" 'BEGIN{print FS}'
:
先执行命令再执行BEGIN模块
思想:
- awk核心思想就是现处理,然后END模块输出。(累加(a++;a+=$0),awk数组)
- BEGIN模块用于awk内置变量FS,RS的赋值,打印标题头的信息,(excel表格里面标题行)
- END模块用来最后输出,统计信息,awk数组信息。
- 区域,记录
- BEGIN和END模块只能有一个。不能BEGIN{}BEGIN{}或者END{}END{}
- 找谁干啥模块,可以是多个。
NR=2{print $1}NR=5{print $0}
1.8awk内置变量(预定义变量)
|
变量名 |
属性 |
|
$0 |
当前记录 |
|
$1-$n |
当前记录的第n个字段,字段间由FS分隔 |
|
FS |
输入字段分隔符 默认是空格 |
|
NF |
当前记录中的字段个数。就是有多少列 |
|
NR |
已经读出的记录数,就是行号,从1开始 |
|
RS |
输入的记录分隔符默认为换行符 |
|
OFS |
输出字段分隔符 默认也是空格 |
|
ORS |
输出的记录分隔符,默认为 |
|
FNR |
当前文件的读入记录号 |
1.9 awk数组
示例1-9数组演示
array[b]=”aaa”:array.....
1.9.1企业面试题1
处理以下文件内容,将域名取出并根据域名进行计数排序处理(去重):(百度和sohu面试题)
[root@linux-node1 files]# cat awkfile3.txt
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://post.etiantian.org/index.html
http://mp3.etiantian.org/index.html
http://www.etiantian.org/3.html
http://post.etiantian.org/2.html
[root@linux-node1 files]# awk -F "/" '{array[$3]++}END{for(key in array) print key,array[key]}' awkfile3.txt
mp3.etiantian.org 1
post.etiantian.org 2
www.etiantian.org 3
[root@linux-node1 files]# awk -F "/+" '{array[$2]++}END{for(key in array)print key,array[key]}' awkfile3.txt
mp3.etiantian.org 1
post.etiantian.org 2
www.etiantian.org 3
小结:
- awk数组去重
- 选好分隔符 -F “/”
- 选好处理的区域,print $1,$3,$2
- array[$3]++
- 先处理,最后END模块输出
- 输出awk数组我们使用for(key in array)
- ===>for ()循环
- key in array 手去框里,抓苹果。
- key 就是苹果名字(数组元素的名字)
- array数组名(框的名字)
- 打印输出print key,array[key]
1.9.2 企业案例2统计每个IP的访问量
access_awk.log
1.10 awk相关英语总结
|
名称 |
含义 |
|
filed |
域,区域,字段 |
|
record |
记录,默认一整行 |
|
Filed Separator |
FS:区域分隔符,表示一个区域的结束,字段,域 |
|
Number of Filed |
NF:每一个记录中区域的数量 |
|
Record Separator |
RS:记录分隔符,表示每个记录的结束 |
|
output filed separator |
OFS |
|
output Record Separator |
ORS |
|
awk当前处理的文件的记录号 |
FNR |
[root@linux-node1 files]# seq 20 30 >20-30.txt
[root@linux-node1 files]# seq 50 60 >50-60.txt
[root@linux-node1 files]# awk '{print FNR,NR,$0}' 20-30.txt 50-60.txt
1 1 20
2 2 21
3 3 22
4 4 23
5 5 24
6 6 25
7 7 26
8 8 27
9 9 28
10 10 29
11 11 30
1 12 50
2 13 51
3 14 52
4 15 53
5 16 54
6 17 55
7 18 56
8 19 57
9 20 58
10 21 59
11 22 60
第2章awk总结:
2.1.找谁干啥模块

2.2awk执行过程-完全
BEGIN模块输出一些提示性文字。awk内置变量FS,RS,ORS,OFS。
END 模块输出一些提示性文字,显示最后的结果,计算空行,awk数组,去苹果的过程把苹果展示处理。
awk里面的普通变量不用初始化。
awk先处理,一行一行的处理,然后END模块输出。
- 域与记录
FS指定各种各样的刀(正则表示),RS正则表达
- 模式匹配===》条件 如何找人。
正则表达式
^字符串开头
$字符串结尾
$3~/^http$/
--posix或 --re-interval
r{n,m}
匹配精确,模糊
NR==1
NR>=2
模式默认匹配 一行$0
$3~/^r/
awk ‘$3~/[4-6]/{print $0}’ passwd.txt
范围匹配
NR=2,NR=5 ==>2,5p
/start 位置/,/结束位置/
- 遇到正则表达式/ /
- $3~/reg/
- > = <
- NR==2,NR=5 /start位置/,/结束位置/
- awk数组
数组 ==>元素
一个筐==》苹果



题目来源:
http://edu.51cto.com/course/course_id-4319.html
3. 考试题
考试题1:处理以下文件内容,将域名取出并根据域名进行计数排序处理:(百度和sohu面试题)
oldboy.log
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://post.etiantian.org/index.html
http://mp3.etiantian.org/index.html
http://www.etiantian.org/3.html
http://post.etiantian.org/2.html
答案 (4种)
#这里的
root@linux-node1 files]# awk -F "/" '{array[$3]++}END{for(key in array) print key,array[key]}' awkfile3.txt
[root@linux-node1 files]# awk -F "/+" '{array[$2]++}END{for(key in array)print key,array[key]}' awkfile3.txt
[root@linux-node1 files]# cut -d / -f3 awkfile3.txt|sort|uniq -c|sort -nrk2
[root@linux-node1 files]# sort -t / -rk3 awkfile3.txt|awk -F / '{print $3}'|uniq -c
考试题2:统计企业工作中高并发web服务器不同网络连接状态对应的数量
[root@linux-node1 files]# netstat -ant|awk 'NR>=3{array[$6]++}END{for(key in array)print key,array[key]}'
TIME_WAIT 134
SYN_SENT 1
ESTABLISHED 5
LISTEN 10
[root@linux-node1 files]# netstat -ant|awk '{print $6}'|uniq -c|sort -nr
138 TIME_WAIT
7 LISTEN
5 ESTABLISHED
3 LISTEN
1 Foreign
1 established)
考试题3.分析图片服务日志,把日志(每个图片访问次数*图片大小的总和)排行,取top10,也就是计算每个url的总访问大小【附加题:加分题】。
说明:本题生产环境应用:这个功能可以用于IDC网站流量带宽很高,然后通过分析服务器日志哪些元素占用流量过大,进而进行优化或裁剪该图片,压缩js等措施。
本题需要输出三个指标: 【访问次数】 【访问次数*单个文件大小】 【文件名(可以带URL)】
测试数据
59.33.26.105 - - [08/Dec/2010:15:43:56 +0800] "GET /static/images/photos/2.jpg HTTP/1.1" 200 11299 "http://oldboy.blog.51cto.com/static/web/column/17/index.shtml?courseId=43" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"
59.33.26.105 - - [08/Dec/2010:15:43:56 +0800] "GET /static/images/photos/2.jpg HTTP/1.1" 200 11299 "http://oldboy.blog.51cto.com/static/web/column/17/index.shtml?courseId=43" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"
59.33.26.105 - - [08/Dec/2010:15:44:02 +0800] "GET /static/flex/vedioLoading.swf HTTP/1.1" 200 3583 "http://oldboy.blog.51cto.com/static/flex/AdobeVideoPlayer.swf?width=590&height=328&url=/[[DYNAMIC]]/2" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"
124.115.4.18 - - [08/Dec/2010:15:44:15 +0800] "GET /?= HTTP/1.1" 200 46232 "-" "-"
124.115.4.18 - - [08/Dec/2010:15:44:25 +0800] "GET /static/js/web_js.js HTTP/1.1" 200 4460 "-" "-"
124.115.4.18 - - [08/Dec/2010:15:44:25 +0800] "GET /static/js/jquery.lazyload.js HTTP/1.1" 200 1627 "-" "-"
答案:
[root@linux-node1 files]# awk 'BEGIN{print"URL:"" ""num: ""total_size:"}{a[$7]++;b[$7]=$10}END{for(key in a)print key" "a[key]" "a[key]*b[key]}' images.log
URL: num: total_size:
/?= 1 46232
/static/js/web_js.js 1 4460
/static/images/photos/2.jpg 2 22598
/static/flex/vedioLoading.swf 1 3583
/static/js/jquery.lazyload.js 1 1627
理解透上述问题并搞定后,你将可以轻松搞定如下扩展的考试题:
扩展考试题1:
4.假如现在有个文本,格式如下:
a 1
b 3
c 2
d 7
b 5
a 3
g 2
f 6
d 9
即左边是随机字母,右边是随机数字,要求写个脚本使其输出格式为:
a 4
b 8
c 2
d 16
f 6
g 2
即将相同的字母后面的数字加在一起,按字母的顺序输出。
答案:
答案
[root@linux-node1 files]# awk '{if(! a[$1]++)b[++n]=$1;c[$1]+=$2}END{for(i=1;i<=n;i++)print b[i],c[b[i]]}' a.txt
a 4
b 8
c 2
d 16
g 2
f 6
扩展考试题2:用shell处理以下内容
1、按单词出现频率降序排序!
2、按字母出现频率降序排序!
the squid project provides a number of resources to assist users design,implement and support squid installations. Please browse the documentation and support sections for more infomation
1.答案
[root@linux-node1 files]# sed -r 's#,| # #g' b.txt|awk '{array[$0]++}END{for(key in array) print array[key],key}'|sort -r
2 the
2 support
2 squid
2 and
1 users
1 to
1 sections
1 resources
1 provides
1 project
1 of
1 number
1 more
1 installations.
1 infomation
1 implement
1 for
1 documentation
1 design
1 browse
1 assist
1 a
1 Please
1
2.答案
[root@linux-node1 files]# sed 's#[a-zA-Z]#& #g' b.txt|awk 'BEGIN{RS=" "}{arr[$1]++}END{for(i in arr) print arr[i],i}'|sort -nr
25
19 s
17 e
16 o
14 t
12 n
11 r
11 i
9 a
8 u
7 p
7 d
6 m
4 l
4 c
3 f
2 q
2 h
2 b
1 w
1 v
1 j
1 g
1 P
1 .
1 ,i