Spark是由加州大学伯克利分校的AMPLab于2009年开发,并于2014年成为Apache的顶级项目,其本身是一个基于内存的分布式处理框架,能够处理批运算,在Spark Streaming模块的支持下,也可以用于流式实时处理,Spark从一开始便是作为一个生态系统出现,是一个通用的计算框架,本文参考了网上相关的spark资料,期望能对spark有个快速的全貌了解
1:Spark思维导图
2:支持语言
Spark框架本身是由Scala语言编写,这是一种类似java的语言,兼具面向对象和函数式编程特点,其编译结果为java字节码,运行与java虚拟机上,并可以直接使用Java库,在实际开发过程中,Spark支持Scala,Java,Python 及R 4种语言,如果使用Scala,可以在spark-shell中方便的通过交互式方式来查询和打草稿,如果使用python语言,也可以使用pyspark shell上来执行命令和查询
3:生态系统
Spark从诞生之初就是一个生态系统,称之为BDAS(伯克利数据分析栈Berkeley data analytics stack)
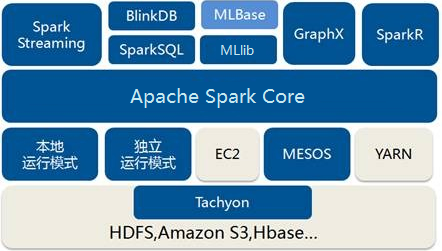
在Spark Core之上提供了4个模块
SparkSQL:提供类似SQL的查询,返回Spark DataFrame数据结构
Spark Streaming:流式计算模块,用于实时数据流处理
MLlib:机器学习模块
GraphX:基于图的算法模块
Spark Core:Spark 的核心模块,提供基本的RDD及算子,DAG计算框架
4:运行模式
Spark可以提供多种运行模式,

- 本地模式:
运行于单机上,以多线程的方式模拟Spark分布式计算,通常用于开发阶段及调试,此模式下没有master,worker角色,参数Local[N]表示启动N个线程,每个线程一个core,如果不指定N,则默认是1个线程(该线程有1个core)
在本地模式中,还可以通过修改参数,运行伪集群模式,在单机启动多个进程来模拟分布式场景
单机多线程:spark-submit --class {mainClass} --master local[N] {jar file}
local[N] 指N个线程,如果设置为local[*]则指定线程数为cpu的逻辑内核数
单机多进程(本地伪集群模式):spark-submit --class {mainClass} --master local[2,3,1024] {jar file}
表示2个executor,每个executor有3个core,且分配1G内存
- 独立模式(独立集群模式):这是部署spark的最简单方式,参见 Ubuntu18.04 下 Spark 2.4.3 standalone模式集群部署
这是Spark自带资源调度框架,不需要依赖其他的资源管理系统,由master,slave角色组成,使用ZooKeeper实现Master HA,在独立模式下,有2种部署方式,client 模式及 cluster模式
- Spark on Mesos模式:
官方推荐的是Mesos,因为Spark原生的就对Mesos支持,存在2种调度模式来运行程序:粗粒度模式,细粒度模式
- Spark on YARN模式:
Spark支持YARN资源调度框架,通过使用YARN,使得Spark与Hadoop生态能很好的有机结合,又细分2种模式,yarn-cluster和yarn-client
5:Spark应用架构
Spark主要用来对大规模数据进行离线或流式处理,其本身是一种微批系统,借助于Spark Streaming,能近乎实时的处理流式数据,Spark具备DAG执行引擎,计算模型统一基于内存RDD的多次迭代,常部署在集群环境下,除了可以Standlone模式运行外,更多的是与第3方资源管理调度系统结合,如Mesos及YARN,下图为Spark框架:
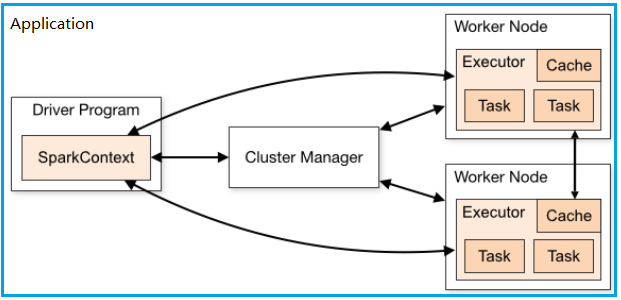
在上面Spark架构中,可以看到以下特定的概念:
- Application:Spark的应用程序,包含一个Driver和若干Executor
- Worker Node:实际运行Application的节点,启动一个或多个Executor
- Driver:运行Application的main()函数并且创建SparkContext,其与ClusterManager通信,进行资源的申请,任务分配等,Task的分发
- Executor:在Worker Node上的一个进程,该进程负责运行一个或多个Task,并且负责将数据存在内存或者磁盘上。
- Cluster Manager:在集群上负责统一的资源管理,如Spark自动的资源管理系统,或者YARN及Mesos
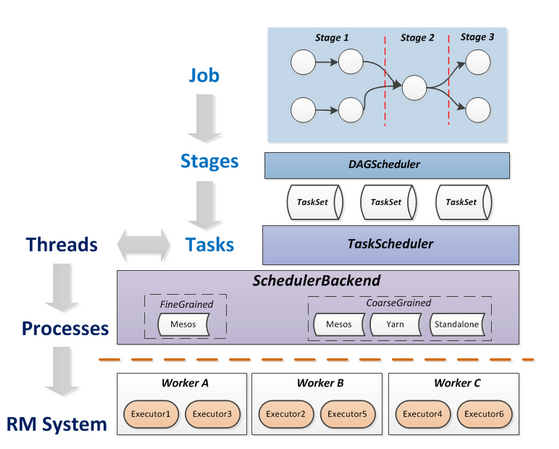
- Job:SparkContext提交的每一个action,会生成一个Job,Spark以最远端的RDD为起点(最远端指的是对外没有依赖的 RDD 或者 数据已经缓存下来的 RDD),到Action为终点,形成一个DAG(有向无环图)
- Stage:在一个Job中,Spark调度器(DAGScheduler)以shuffle类算子来划分stage边界,
- Task:在每个stage中,划分成多个task,Driver会将Task及所依赖的file和jar序列化后传递到某个Executor上运行
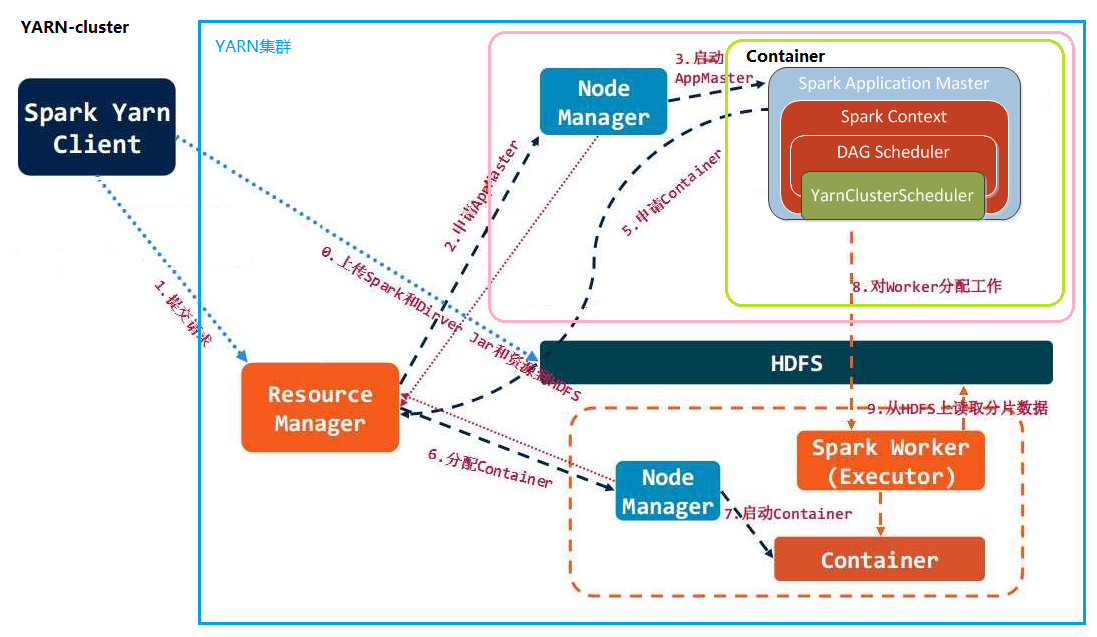
基于YARN的Spark,因cluster及client的不同,其架构流程又存在差别
YARN client:Driver运行在Client中,Application Master仅向YARN请求Container,Client将和Container通信并调度Executor
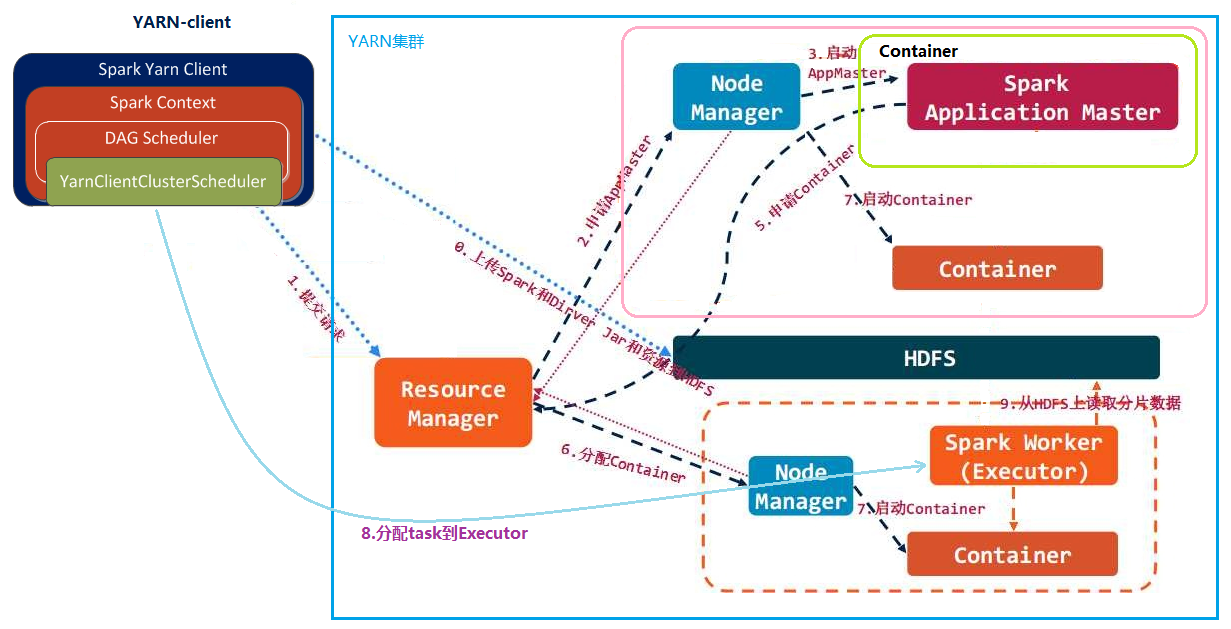
YARN cluster:Driver运行在Application Master中,其负责向YARN申请资源,并监督作业的运行状况,当用户提交了作业之后,就可以关闭Client,作业会继续在YARN上运行,此模式不适合运行交互类型的作业
6:Spark核心概念
RDD(Resilent Distributed Datasets),弹性分布式数据集,是 Spark 底层的分布式存储的数据结构,是 Spark 的核心概念,Spark API 的所有操作都是基于 RDD 的
对RDD的理解:
Resilent:节点失败(分区丢失)可重新计算
Distributed:数据集被拆分到多个分区中
Dataset:可以包含任意类型或用户自定义对象
RDD具有以下特定:
- 是在集群节点上的只读不可变的、已分区的集合对象;
- 通过并行转换的方式或外部文件读取来创建(如 Map、 filter、join 等);
- 失败自动重建;
- 可以控制存储级别(内存、磁盘等)来进行重用;
- 是可序列化的;
RDD是一种只读数据块,可以通过2种方式创建
- 并行化(Parallelizing):从一个已经存在于驱动程序(Driver Program)中的集合如set、list创建
val arr = Array("help","morning","sun")
val rdd = sc.parallize(arr)
- 读取外部数据:从外部本地文件读取或从HDFS等读取
val rdd= sc.textFile("D:\temp\holdings.txt",2)
在RDD上可以进行函数操作,主要有2 种类型:Transformation和Action
Action操作是创建DAG的前提条件,而Transformation操作是lazy的,不会立刻执行,只有遇到Action操作才会触发生成DAG并执行job命令
Transformation:返回值还是 RDD,不会马上 提交 Spark 集群运行
Action:返回值不是 RDD,会形成 DAG 图,提交 Spark 集群运行 并立即返回结果
常见的算子如下列表所示:
| Transformation | Action |
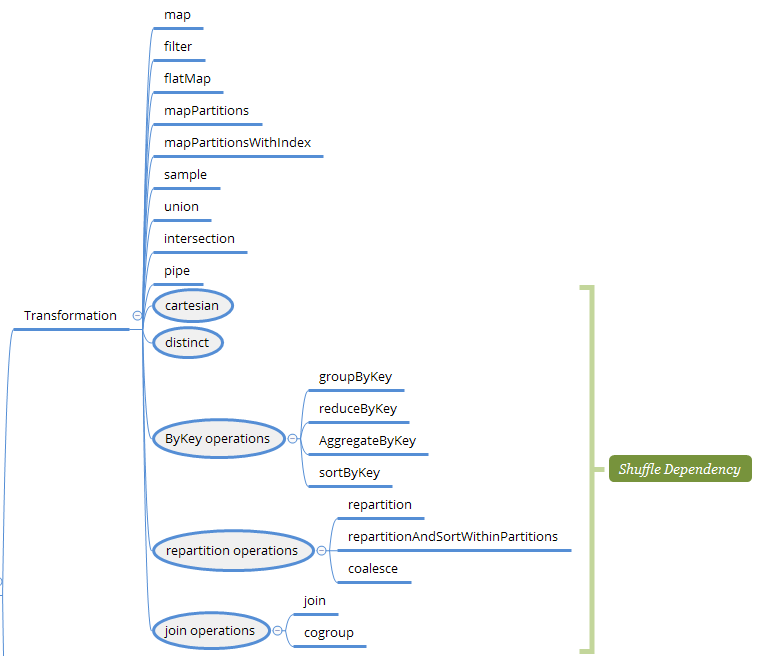
|
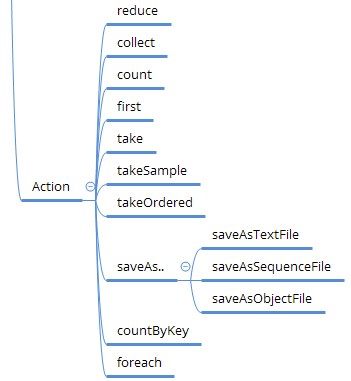
|
当在RDD上应用Transformation操作时,将创建RDD Lineage,每个RDD都包含了其是如何由父RDD变换过来的,记录的是粗颗粒度的特定Transformation操作行为。RDD的容错机制称为“血统(Lineage)”容错,当这个RDD的部分分区数据丢失时,可以通过Lineage的信息来重新运算和恢复丢失的数据分区
RDD调度过程:
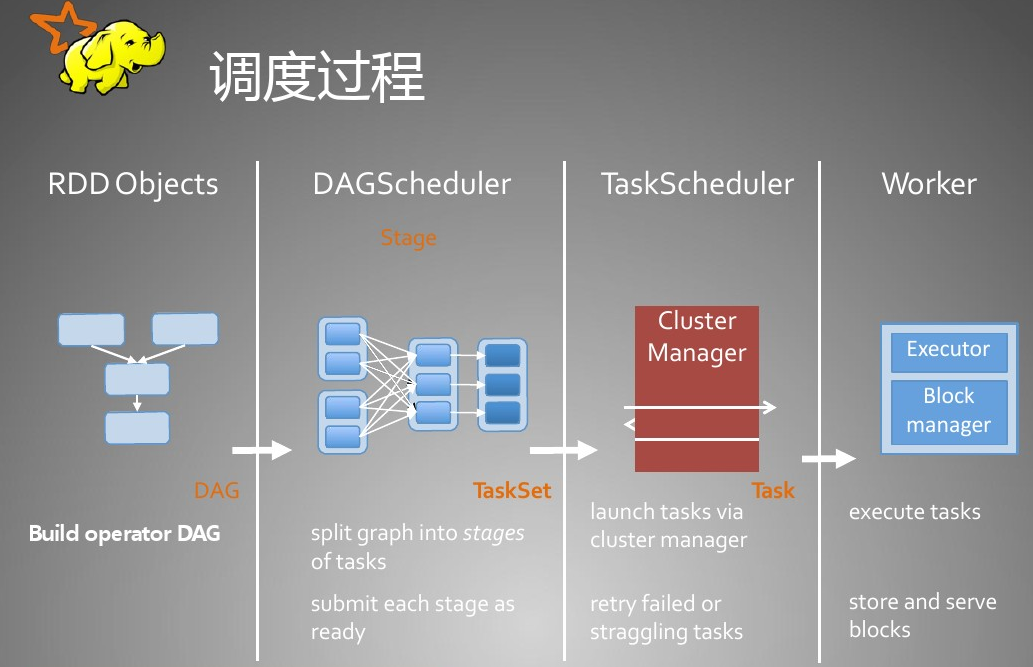
对于Job/Stage/Task,从DAG图的生成到DAGScheduler--> TaskScheduler --> 最后提交到每一个Executor执行,下图清晰的表达了内部的执行逻辑
RDD依赖
在调用RDD的transformation函数时,分为窄依赖(narrow dependency)和宽依赖(wide dependency),其区别在于是否会发生洗牌(shuffle)过程,所以宽依赖又称为shuffle dependency,如果RDD的每个分区最多只能被child RDD的一个分区使用,则为窄依赖,若每个分区被child RDD多个分区使用,则为宽依赖,宽依赖将导致数据在内存中重新分布,及多个节点间的数据传输,非常影响性能,是优化的关键点
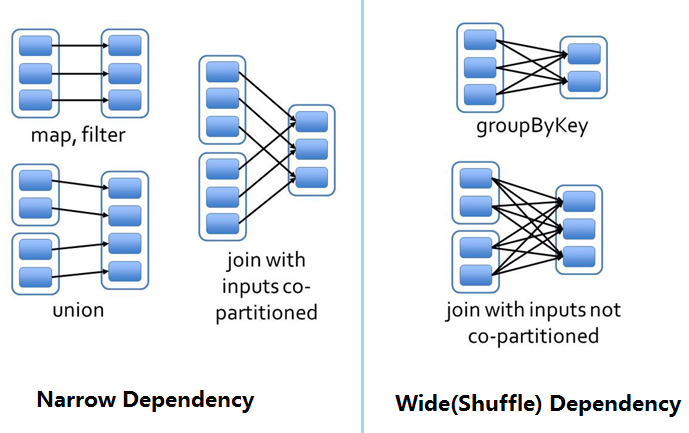
对于这2种依赖,在Berkeley的论文RDD:基于内存的集群计算容错抽象中非常清晰的描述了它们的对比:
区分这两种依赖很有用。首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
参考: