一、列表list
1、list定义
列表即数组 ,list或array.。列表中的每个元素都有自己的编号,从0开始,编号也可叫做下标,角标,索引。最后一个元素的下标也可用-1表示.:
list定义时,需要用中括号[]括起来元素,每个元素之间用逗号分隔开。示例:stus=[‘小白’,'小红,‘小明’,'小兰'] 元素如果是字符串需要用引号括起来
2、list操作
增:
stus.append('北京') #在列表末尾增加一个元素 stus.insert(0,'上海') #在指定的位置增加元素
stus.extend(list1)#将list1合并到stus中
stus+list1 #合并list1和stus
删:
stus.pop(0) #删除指定位置的元素 stus.remove('北京') #删除指定的元素 del stus[2] #删除指定位置元素 stus.clear()#清空list
改:
stus[1]='深圳'# 修改指定位置的元素,但是如果下标不存在,则会报错
查:
print(stus[1])#获取指定位置的元素,并打印出来 print(stus.index('北京'))#获取元素对应的下标,如果元素不存在,下标找不到,会报错 print()stus.count('深圳'))#获取元素在list中出现的次数
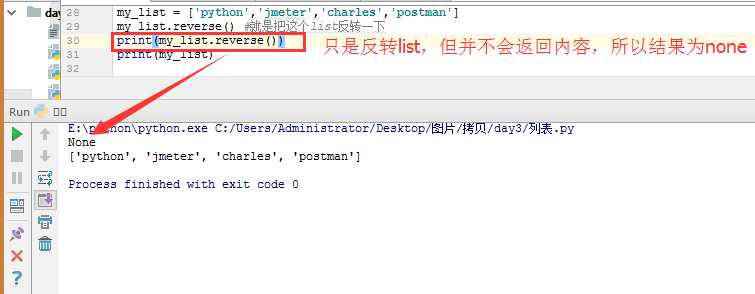
list反转:
my_list = ['python','jmeter','charles','postman'] my_list.reverse() #就是把这个list反转一下,并不会返回任何内容。如果你直接打印会发现,结果显示none : print(my_list.reverse()) print(my_list)#显示翻转后的list
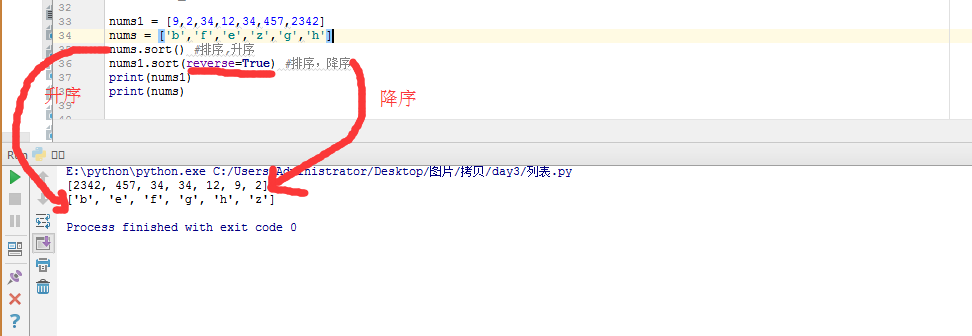
list排序:
可对数值型元素排序也可对字符串型元素排序,默认按升序排序。如果加上参数reverse=True,则按照降序排序
list合并:
list的合并,只需要多个list用加号+链接即可
nums1 = [9,2,34,12,34,457,2342] nums = ['b','f','e','z','g','h'] print(nums1+nums2)#结果就是两个list合并后[9,2,34,12,34,457,2342,'b','f','e','z','g','h']
如果同一个list中的内容,复制合并,则直接用原来的list*n(n表示次数):
print(nums1*3),则输出:[9, 2, 34, 12, 34, 457, 2342, 9, 2, 34, 12, 34, 457, 2342, 9, 2, 34, 12, 34, 457, 2342],把原来的nums1重复3次后输出,
字符串也可以这样用:print('东方大厦'*3),输出:东方大厦东方大厦东方大厦
3、多维数组
多维数组就是数组中的元素仍是数组。维数根据数组嵌套层次计算:
stus=['aaaa','bbbb','cccc','dddd','eeee','ffff',['ggg','hhh'],'jjjjj']#这就是一个2维数组
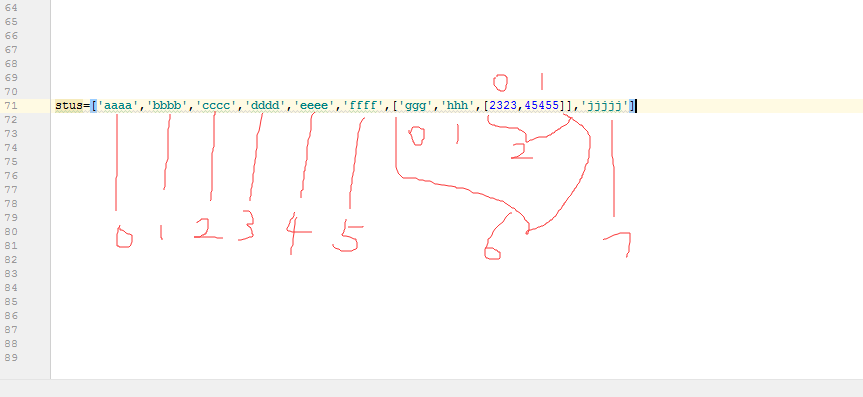
stus=['aaaa','bbbb','cccc','dddd','eeee','ffff',['ggg','hhh',[2323,45455]],'jjjjj']#这就是一个3维数组,最外层是stus[],第二层是['ggg','hhh',[2323,45455]],第三层是[2323,45455]
多维数组的取值:根据下标逐层取:
比如上例要取最里层的45455,一层一层深入,首先45455在最内层[2323,45455]的1位置(或者-1位置),然后最内层在第二层['ggg','hhh',[2323,45455]]的2位置,第二层整体在最外层的6位置,所以最终结果为stus[6][2][1]或者stus[6][-1][-1],最后一个元素也可用-1取
4、循环遍历数组
一维数组:
for var in words: #var此时代表的就是words中的每个元素
print var
#第二种方法 for i in range(5) #i表示循环次数,从0开始,同时也充当words的下标 print(words[i])
多维数组
words=['1','sdf ','3232','ddsdff','fffdfdf',[1,2,4,'dsfsd']]
#如果想要遍历所有元素,包括内置的list[1,2,4,'dsfsd']的所有元素。则在遍历words的时候,可以做一下判断,当words的元素类型为list时,再次循环
for name in words:
if type(name)==list: #判断一个变量的类型,是否是list
for i in name: #如果是list,继续遍历该变量
print(i)
print(name)
5、切片
# 切片是list取值的一种方式,可一次取出多个元素
nums=['12','34','sdf','fere','dsfds'] print(nums[1:3]) #取出下标从1开始至2的元素,即:nums[1]nums[2],顾头不顾尾,nums[3]的取不到 print(nums[1:]) #取值从下标1开始,到结束。如果从某个下标开始取,取到末尾结束,那么末尾的下标可以省略不写 print(nums[:3]) #取值从下标1开始,到下标1.如果是从头开始取,取到后面某个下标结束,那么开头的下标可以不写 print(nums[:]) #取所有的
#如果想有规律的隔几个取一个,则可以加上步长
例:lis=[1,2,3,4,5,6,7,8,9] print(lis[::2]) #步长是2,结果是1,3,5,7,9
这里步长是正数,则按照从左往右依次取,如果步长为负数,则需要从右往左取值:
print(lis[::-1]) #步长是负数,反向取,结果是9,8,7,6,5,4,3,2,1 这个反转取值,是会产生一个新的list,在原来list的基础上反向,并不会改变原来list的顺序,此时如果你继续输出print(lis),会发现,并没有任何变化 但是如果用reverse函数,那就回改变原有list的值: lis.reverse() print(lis)#此时,lis输出顺序就是反向的
切片同样适用于字符串:
s='abcdefg' print(s[:3]) #输出abc,下标从开始到2,顾头不顾尾,所以下标3取不到
6、元组
元祖也是一种list,但他和list的区别在于,元祖里面的元祖不可修改。元组定义的格式是用一个小括号括起来所有的元素,元素中间用逗号分隔,需要注意的是,如果元祖中只有1个元素,则需要在最后加一个逗号
例:yuanzu=(1,2,3,4,5,'wewew')
yuanzu=(1,)#只有一个元素,要加上逗号
相关操作和list一样:
print(yuanzu.index('wewew')) #找到元素的下标
print(yuanzu.count('wewew')) #找到元素的个数
元祖只有index和count方法,元祖的元素不可变更,修改增加都不行:
如果yuanzu[3]=43,会提示错误 TypeError: 'tuple' object does not support item assignmen
7、字典
字典是一种通过名字或者关键字引用的得数据结构,其键可以是数字、字符串、元组,为key-value格式,取数据非常方便,而且速度很快。
字典的定义用大括号{}将元素括起来,里面是一对一的键值对key-value.,key和value之间用冒号分隔
例:infos = {'name':'小红','sex':'女','addr':'北京','age':15} #name,sex,addr,age是key, 小红,女,北京,15是对应的value
1、字典操作:
增加
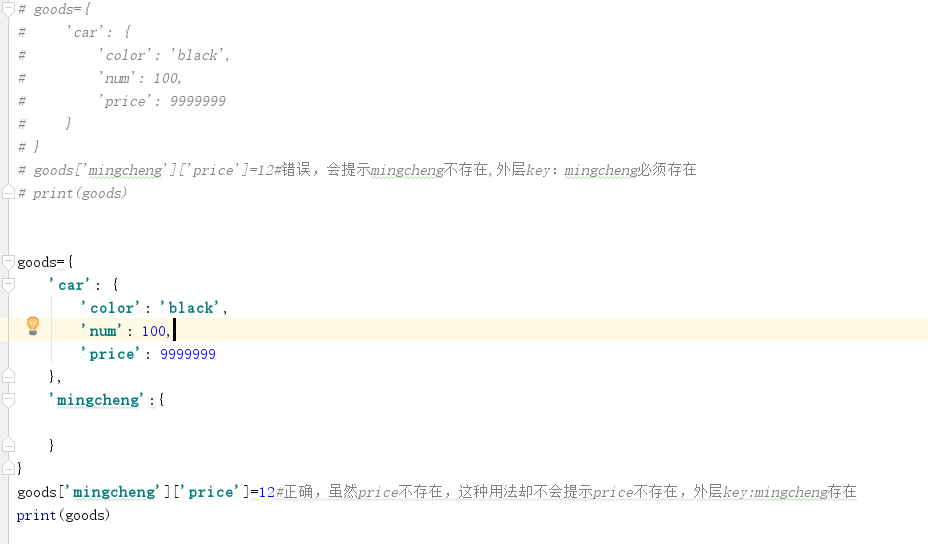
#增 infos['phone']=13611087045 #通过指定key来增加,但是如果key原本就存在,就会修改原来key值.如果key不存在,会新增一对key-value
注意:对于嵌套字典,这种方式新增key-value时,外层的key必须存在,否则会出错
infos.setdefault('phone','13611087045')#但是如果用setdefault方法,key值原本就存在的话,是不会改变原来的值
infos.setdefault('name','使劲地激发')#不会改变原来的值,print(infos['name'])的结果还是小红 infos['name']='熊阿兰' #会改变原来的值,print(infos['name'])#输出结果就是熊阿兰
infos.update(set1)# 将set1字典的元素,加入到infos字典中,如果key有重复的,则覆盖
改:
修改的话,就直接调用key修改即可:infos['name']='熊阿兰'
删:
infos.pop('name') #指定key来删除 infos.popitem() #随机删除一个key del infos['phone'] #指定key来删除 infos.clear() #清空字典
查:
print(infos.get('phone'))#取不到这个key的话,就是None print(infos.get('phone',110))#如果取不到这个key的话,默认就是110 print(infos['phone'])#如果key不存在会报错,所以一般不用这个
print(infos.values())#获取到字典所有的value
print(infos.keys()) #获取到字典所有的key
print(infos.items()) # 获取字典所有的k-v
#如果字典多层嵌套,想要取字典中某个value时,方法同list,一层一层深入取值
people = {
'小红':{
'age':18,
'class':'二年一班'
'shoes':['nike','addis','lv','chanle']
}}
要想取到lv,则 people['小红']['shoes'][2]
1、先people['小红']取到key 小红对应的value:
{
'age':18,
'class':'二年一班'
'shoes':['nike','addis','lv','chanle']
}
2、 然后再用[shoes]取到key shoes对应的values:['nike','addis','lv','chanle']
3、然后这是一个数组,所以用索引[2]取到对应的lv,综上people['小红']['shoes'][2]
循环字典:
#直接循环一个字典的话,那么循环的是字典的key
for p in infos:
print(p)#书出来是people中的所有key
for k,v in infos.items(): #循环的时候,同时取key和value
print(k,'======》',v)
8、常用的字符串方法
如下,需要用时,直接参考使用
a=' 字 符 串 ' c = a.strip() #默认去掉字符串两边的空格和换行符 c= a.lstrip() #默认去掉字符串左边的空格和换行符 c = a.rstrip() #默认去掉字符串右边的空格 print('c...',c) print('a...',a) words = 'http://www.nnzHp.cn' print(words.strip('day')) #如果strip方法指定一个值的话,那么会去掉这两个值 print(words.count('a')) #统计字符串出现的次数 print(words.index('z')) #找下标,如果元素找不到的话,会报错 print(words.find('z')) #找下标,如果元素找不到的话,返回-1 print(words.replace('day','DAY')) #替换字符串 print(words.isdigit()) #判断字符串是否为纯数字 print(words.startswith('http')) #判断是否以某个字符串开头 print(words.endswith('.jpg')) #判断是否以某个字符串结尾 print(words.upper()) #变成大写的 print(words.lower()) #变成小写的 username = 'abcdefADS12345@#¥' print(username.isalpha()) #判断字符串是否全为字母和汉字 print(username.isalnum()) #判断是否包含汉字,字母和数字,它是只要有没有特殊符号就返回true
print(a.islower()) #是否全都是x小写字母
print(a.isupper()) #是否全都是大写字母
join方法:用特定的字符,将可循环的数据类型链接起来,比如list,字符串等,
如下两个例子
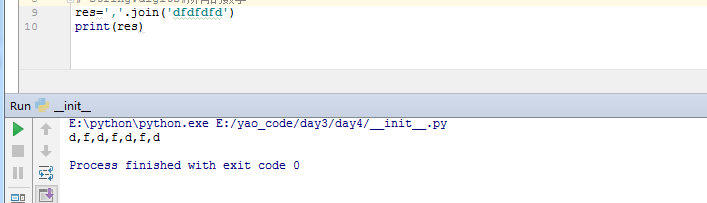
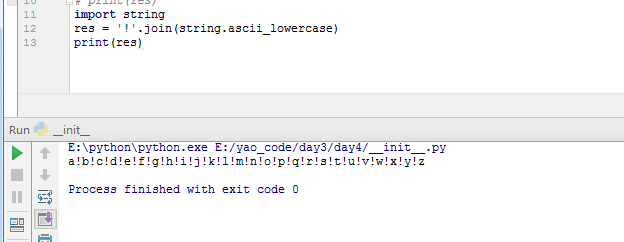
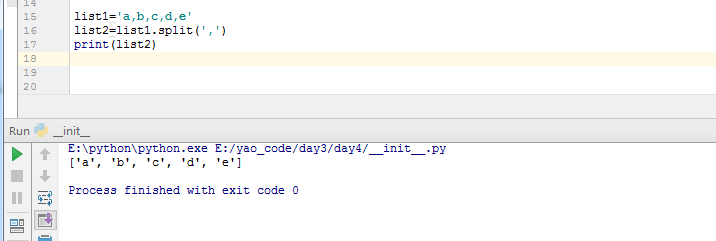
split(‘,’):根据某个字符串,分割字符串,什么也不传的话,是以空格分割的。最终返回一个list
字符串格式化:format
字符串格式化有两种方式,第一种就是前面写的%s %d占位符方式:
import datetime name='zhangyoa' date=datetime.date.today() print('%s你好,欢迎你登陆,今天的日期是%s'%(name,date)) 这种方式要求前面的占位符跟后面跟着的变量要一一对应,如果碰到变量比较多的情况,就比较麻烦,要对准哪个对应哪个。
第二种方式就是用字符串的format函数
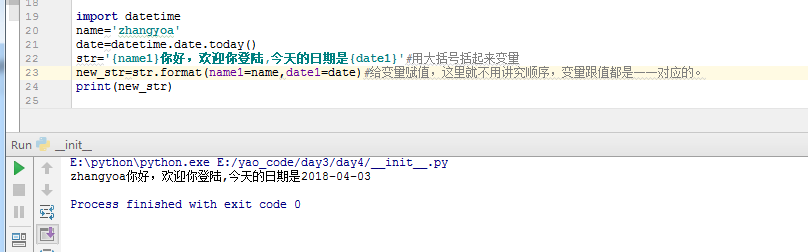
str.center()方法:让字符串居中显示,可以规定总长度,长度不够,用字符代替
'str' .zfill(n)方法:将用0将字符串str补充至长度为n,
print('1'.zfill(4))#输出结果就是0001
9、string模块的常用方法
使用string模块的方法之前,先要导入该模块,import string
import string string.ascii_letters#所有的大小写字母 string.ascii_lowercase#所有的小写字母 string.ascii_uppercase#所有的大写字母 string.punctuation#所有的符号 string.digits#所有的数字