背景:
大多数情况下,我们遇到的是访问频率限制。如果你访问太快了,网站就会认为你不是一个人。这种情况下需要设定好频率的阈值,否则有可能误伤。如果大家考过托福,或者在12306上面买过火车票,你应该会有这样的体会,有时候即便你是真的用手在操作页面,但是因为你鼠标点得太快了,它都会提示你: “操作频率太快...”。
遇到这种网页,最直接的办法是限制访问时间。例如每隔5秒钟访问一次页面。但是如果遇到聪明一点的网站,它检测到你的访问时间,这个人访问了几十个页面,但是每次访问都刚好5秒钟,人怎么可能做到这么准确的时间间隔?肯定是爬虫,被封也是理所当然的!所以访问时间间隔你可以设定为一个随机值,例如0到10之间的随机秒数。
当然,如果遇到限制访问频率的网站,我们使用Selenium来访问就显得比较有优势了,因为Selenium这个东西打开一个页面本身就需要一定的时间,所以我们因祸得福,它的效率低下反而让我们绕过了频率检查的反爬虫机制。而且Selenium还可以帮我们渲染网页的JavaScript,省去了人工分析JavaScript源代码的麻烦,可谓一举两得。
下面是我经常使用的修改访问频率的几种场景,供大家参考:
1、Request 单机版爬虫:
上面的代码可以放在request请求之后

2、scrapy 单机版爬虫或者scrapy_redis分布式爬虫

在这里设置请求间隔时间,其他参数的讲解,我会更新到新的博文中,敬请大家期待
另外,不明确 scapy 和 scrapy_redis 区别的朋友们,可以移步到这里
https://www.cnblogs.com/beiyi888/p/11283823.html
3、有一种情况可以忽略
有些网站,比如在我之前遇到过的这种网站(hwt),服务器会限制你的访问频率,但是并不会封IP,页面将持续显示403(服务器拒绝访问),偶尔显示200(请求成功),那么就证明(前提是我们设置过请求头等信息),这样的反爬机制,只是限制了请求的频率,但是并不会影响到正常的采集,当然这样的情况也不多见,所以我们要学会针对性地写爬虫。
4、某些服务器由于性能原因,响应较慢(会导致响应超时,从而终止请求)
这种场景一般出现在小网站较多,如(DYW),在我们将请求的参数都安排好之后,却发现,由于服务器的性能原因,采集程序持续报网页404,出现这种情况我们只能延长响应超时的时长,如下图所示:

5、代理IP或者分布式爬虫:
如果对页的爬虫的效率有要求,那就不能通过设定访问时间间隔的方法来绕过频率检查了。
代理IP访问可以解决这个问题。如果用100个代理IP访问100个页面,可以给网站造成一种有100个人,每个人访问了1页的错觉。这样自然而然就不会限制你的访问了。
代理IP经常会出现不稳定的情况。你随便搜一个“免费代理”,会出现很多网站,每个网站也会给你很多的代理IP,但实际上,真正可用的代理IP并不多。你需要维护一个可用的代理IP池,但是一个免费的代理IP,也许在你测试的时候是可以使用的,但是几分钟以后就失效了。使用免费代理IP是已经费时费力,而且很考验你运气的事情。
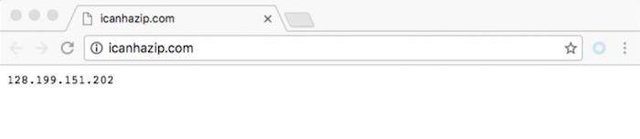
大家可以使用http://icanhazip.com/ 这个网站来检测你的代理IP是否设定成功。当你直接使用浏览器访问这个网站的时候,它会返回你的IP地址。如下图所示:
通过requests,我们可以设置代理访问网站,在requests的get方法中,有一个proxies参数,它接收的数据是一个字典,在这个字典中我们可以设置代理。
大家可以在requests的官方中文文档中看到关于设置代理的更多信息:http://docs.python-requests.org/zh_CN/latest/user/advanced.html#proxies
我选择第一个HTTP类型的代理来给大家做测试,运行效果如下图所示:
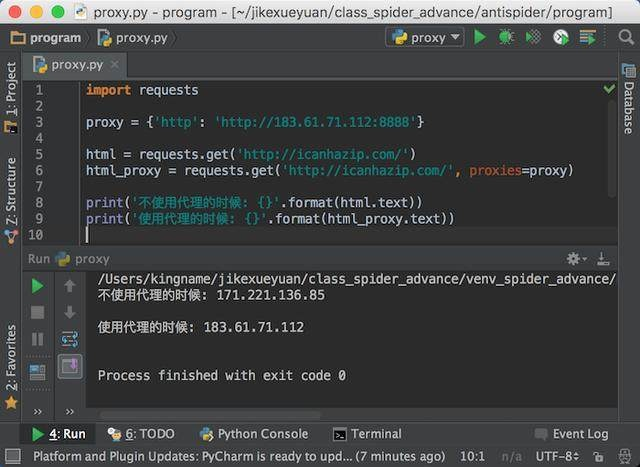
从上图可以看出,我们成功通过了代理IP来访问网站。
我们还可以使用分布式爬虫。分布式爬虫会部署在多台服务器上,每个服务器上的爬虫统一从一个地方拿网址。这样平均下来每个服务器访问网站的频率也就降低了。由于服务器是掌握在我们手上的,因此实现的爬虫会更加的稳定和高效。这也是我们这个课程最后要实现的目标。
那么分布式的爬虫,动态代理IP是在settings.py中设置的,如下图:

然后在这里调用

最终是在middlewares.py中生效
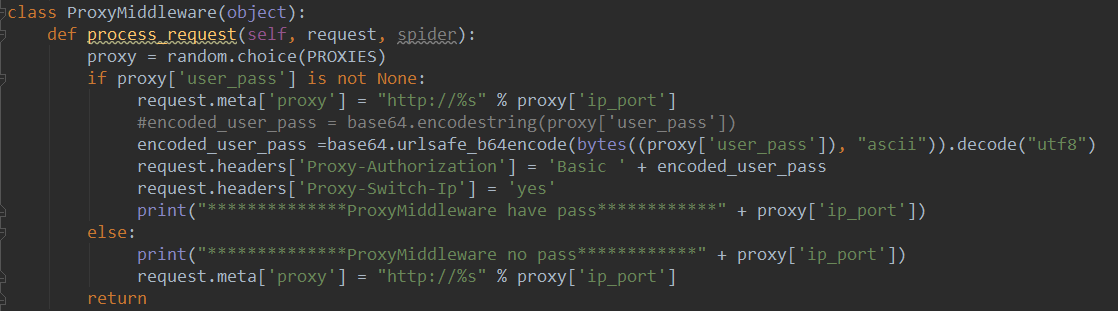
有一些网站,他们每个相同类型的页面的源代码格式都不一样,我们必需要针对每一个页面写XPath或者正则表达式,这种情况就比较棘手了。如果我们需要的内容只是文本,那还好说,直接把所有HTML标签去掉就可以了。可是如果我们还需要里面的链接等等内容,那就只有做苦力一页一页的去看了。