Python字节码
我们知道,Python源代码在执行前,会先将源代码编译为字节码序列,Python虚拟机就根据这些字节码进行一系列的操作,从而完成对Python程序的执行。在Python2.5中,一共定义了104条字节码指令:
opcode.h
#define STOP_CODE 0 #define POP_TOP 1 #define ROT_TWO 2 #define ROT_THREE 3 #define DUP_TOP 4 #define ROT_FOUR 5 #define NOP 9 #define UNARY_POSITIVE 10 #define UNARY_NEGATIVE 11 #define UNARY_NOT 12 #define UNARY_CONVERT 13 #define UNARY_INVERT 15 #define LIST_APPEND 18 #define BINARY_POWER 19 ………… #define CALL_FUNCTION_KW 141 /* #args + (#kwargs<<8) */ #define CALL_FUNCTION_VAR_KW 142 /* #args + (#kwargs<<8) */ /* Support for opargs more than 16 bits long */ #define EXTENDED_ARG 143
如果我们仔细看上面的字节码指令,会发现虽然字节码是从0定义到143,但中间有发生跳跃,比方5直接跳跃到9,13直接跳跃到15,15直接跳跃到18。所以,Python2.5实际上只定义了104条字节码指令
在Python2.5的104条指令中,有一部分需要参数,另一部分是没有参数的。所有需要参数的字节码指令的编码都是大于90。Python中提供了专门的宏来判断一条字节码指令是否需要参数:
opcode.h
#define HAVE_ARGUMENT 90 /* Opcodes from here have an argument: */ #define HAS_ARG(op) ((op) >= HAVE_ARGUMENT)
我们在Python之code对象与pyc文件(一)、Python之code对象与pyc文件(二)和Python之code对象与pyc文件(三)介绍了PyCodeObject对象,这个对象是Python对源代码进行编译后在内存中产生的静态对象,这个对象当然也包含了源代码编译后的字节码,我们可以用Python提供的code对象解析工具dis对其进行解析
# cat demo.py
i = 1
s = "Python"
d = {}
l = []
# python
…………
>>> source = open("demo.py").read()
>>> co = compile(source, "demo.py", "exec")
>>> import dis
>>> dis.dis(co)
1 0 LOAD_CONST 0 (1)
3 STORE_NAME 0 (i)
2 6 LOAD_CONST 1 ('Python')
9 STORE_NAME 1 (s)
3 12 BUILD_MAP 0
15 STORE_NAME 2 (d)
4 18 BUILD_LIST 0
21 STORE_NAME 3 (l)
24 LOAD_CONST 2 (None)
27 RETURN_VALUE
最左边的一列是字节码指令在源代码中所对应的行数,左起第二列是当前字节码在co_code中的偏移位置,第三列显示了当前字节码的指令,第四列是指令的参数,最后一列是计算后的实际参数
Python虚拟机的运行框架
当Python启动后,首先会进行Python运行时环境的初始化。注意,这里的运行时环境与之前的章节《Python之code对象与pyc文件》中的执行环境是不同的。运行时环境是一个全局的概念,而执行环境实际就是一个栈帧。是一个与某个Code Block对应的概念。而Python虚拟机的实现,是在一个函数中,这里我们列一下源码,与实际的源代码会做一些删改:
ceval.c
PyObject * PyEval_EvalFrameEx(PyFrameObject *f, int throwflag)
{
…………
co = f->f_code;
names = co->co_names;
consts = co->co_consts;
fastlocals = f->f_localsplus;
freevars = f->f_localsplus + co->co_nlocals;
first_instr = (unsigned char*) PyString_AS_STRING(co->co_code);
next_instr = first_instr + f->f_lasti + 1;
stack_pointer = f->f_stacktop;
assert(stack_pointer != NULL);
f->f_stacktop = NULL;
…………
}
PyEval_EvalFrameEx首先会初始化一些变量,其中PyFrameObject对象中的PyCodeObject对象包含的重要信息都被照顾到了。当然,另一个重要的动作就是初始化了堆栈的栈顶指针stack_pointer,使其指向f->f_stacktop。PyCodeObject对象中的co_code域中保存着字节码指令和字节码指令的参数,Python虚拟机执行字节码指令序列的过程就是从头到尾遍历整个co_code、依次执行字节码指令的过程
在Python虚拟机中,利用3个变量来完成整个遍历过程。co_code实际上是一个PyStringObject对象,而其中的字符数组才是真正有意义的东西,整个字节码指令序列实际上在C中就是一个字符数组。因此,遍历过程中所使用的3个变量都是char *类型的变量,first_instr永远指向字节码指令序列的开始位置,next_instr永远指向下一条待执行的字节码指令的位置,f_lasti指向上一条已经执行过的字节码指令的位置

图1-1 遍历字节码指令序列
图1-1展示了3个变量在遍历中某时刻的情景
Python虚拟机执行字节码指令的架构,其实就是一个for循环加上一个巨大的switch/case结构:
ceval.c
PyObject *PyEval_EvalFrameEx(PyFrameObject *f, int throwflag)
{
…………
why = WHY_NOT;
for (;;) {
…………
fast_next_opcode:
f->f_lasti = INSTR_OFFSET();
//获得字节码指令
opcode = NEXTOP();
oparg = 0;
//如果指令需要参数,获取指令参数
if (HAS_ARG(opcode))
oparg = NEXTARG();
dispatch_opcode:
switch (opcode) {
case NOP:
goto fast_next_opcode;
case LOAD_FAST:
…………
}
…………
}
…………
}
上面的代码只是一个极度简化之后的Python虚拟机的样子,完整的代码实现在ceval.c文件的PyEval_EvalFrameEx方法中
在这个执行架构中,对字节码的一步一步地遍历是通过几个宏来实现的:
ceval.c
#define INSTR_OFFSET() ((int)(next_instr - first_instr)) #define NEXTOP() (*next_instr++) #define NEXTARG() (next_instr += 2, (next_instr[-1]<<8) + next_instr[-2])
在对PyCodeObject对象分析中我们说过,Python字节码有的是带参数的,有的是没带参数的,判断字节码是否带参数具体参考HAS_ARG这个宏的实现,对于不同字节码指令,由于存在是否需要指令参数的区别,所以next_instr的位移可能是不同的,但无论如何,next_instr总是指向Python下一条要执行的字节码
Python在获得了一条字节码和其需要的指令参数后,会对字节码指令利用switch进行判断,根据判断的结果选择不同的case语句,每一条字节码指令都会对应一个case语句。在case语句中,就是Python对字节码指令的实现
在成功执行完一条字节码指令后,Python的执行流程会跳转到fast_next_opcode处,或者是for循环处,不管如何,Python接下来的动作都是获得下一条字节码指令和指令参数,完成对下一条指令的执行。如此一条一条地遍历co_code中包含的所有字节码指令,最终完成了对Python程序的执行
这里还需要提到一个变量"why",它指示了退出这个巨大的for循环时Python执行引擎的状态,因为Python执行引擎不一定每次执行都会正确无误,很有可能在执行某条字节码时产生了错误,这就是我们熟悉的异常——exception。所以在Python退出执行引擎的时候,就需要知道执行引擎是因为什么而结束的,是正常结束呢?还是因为错误的发生,无法执行下去了?why就承担起这一重则
变量why的取值范围在ceval.c中被定义,其实也是Python结束字节码执行时的状态:
ceval.c
enum why_code {
WHY_NOT = 0x0001, /* No error */
WHY_EXCEPTION = 0x0002, /* Exception occurred */
WHY_RERAISE = 0x0004, /* Exception re-raised by 'finally' */
WHY_RETURN = 0x0008, /* 'return' statement */
WHY_BREAK = 0x0010, /* 'break' statement */
WHY_CONTINUE = 0x0020, /* 'continue' statement */
WHY_YIELD = 0x0040 /* 'yield' operator */
};
Python运行时环境初探
前面我们说过,PyFrameObject对应于可执行文件在执行时的栈帧,但一个可执行文件要在操作系统中运行只有栈帧是不够的,我们还忽略了两个对于可执行文件至关重要的概念:进程和线程。Python在初始化时会创建一个主线程,所以其运行环境中存在一个主线程。因为在后面剖析Python异常机制会利用到Python内部的线程模型,因此,我们需要对Python线程模型有一个整体概念上的了解。
以Win32平台为例,我们知道,对于原生Win32可执行文件,都会在一个进程内执行。进程并非是与机器指令序列相对应的活动对象,这个可执行文件中机器指令序列对应的活动对象是由线程这个概念来进行抽象的,而进程则是线程的活动环境
对于通常的单线程可执行文件,在执行时操作系统会创建一个进程,在进程中,又会有一个主线程,而对于多线程的可执行文件,在执行时操作系统会创建出一个进程和多个线程,该多个线程能共享进程地址空间中的全局变量,这就自然而然地引出线程同步的问题。CPU对任务的切换实际上是在线程间切换,在切换任务时,CPU需要执行线程环境的保存工作,而在切换至新线程后,需要恢复该线程的线程环境
前面我们所看到的Python虚拟机的运行框架,实际上就是对CPU的抽象,可以看做一个软CPU,Python中所有线程都使用这个软CPU来完成计算工作。真实机器的任务切换机制对应到Python中,就是使不同的线程轮流使用虚拟机的机制
CPU切换任务时需要保存线程运行环境。对于Python来说,在切换线程之前,同样需要保存关于当前线程的信息。在Python中,这个关于线程状态信息的抽象是通过PyThreadState对象来实现的,一个线程将拥有一个PyThreadState对象。所以从另一种意义来说,这个PyThreadState对象也可以看成是线程本身的抽象。但实际上,这两者是有很大的区别的,PyThreadState并非是对线程本身的模拟,因为Python中的线程仍然使用操作系统的原生线程,PyThreadState仅仅是对线程状态的抽象
在Win32下,线程是不能独立存活的,它需要存活在进程的环境中,而多个线程可以共享进程的一些资源。在Python中也是一样,如果Python程序中有两个线程,都会进行同样一个动作——import sys,那么这个sys module应该存多少份?是全局共享还是每个线程但单独一个sys module?如果每个线程单独一份sys module,那么对Python内存的消耗会非常的惊人,所以在Python中,module都是全局共享的,仿佛这些module都是进程中的共享资源一样,对于进程这个概念,Python以PyInterpreterState对象来实现
在Win32下,通常都会有多个进程,而Python实际上也可以由多个逻辑上的interpreter存在。在通常情况下,Python只有一个interpreter,这个interpreter中维护了一个或多个的PyThreadState对象,与这些PyThreadState对象对应的线程轮流使用一个字节码执行引擎
现在,展示一下刚提到的表示进程概念的PyInterpreterState对象和表示线程概念的PyThreadState对象:
pystate.h
typedef struct _is {
struct _is *next;
struct _ts *tstate_head; //模拟进程环境中的线程集合
PyObject *modules;
PyObject *sysdict;
PyObject *builtins;
PyObject *modules_reloading;
PyObject *codec_search_path;
PyObject *codec_search_cache;
PyObject *codec_error_registry;
…………
} PyInterpreterState;
typedef struct _ts {
/* See Python/ceval.c for comments explaining most fields */
struct _ts *next;
PyInterpreterState *interp;
struct _frame *frame; //模拟线程中的函数调用堆栈
int recursion_depth;
int tracing;
int use_tracing;
Py_tracefunc c_profilefunc;
Py_tracefunc c_tracefunc;
PyObject *c_profileobj;
PyObject *c_traceobj;
PyObject *curexc_type;
PyObject *curexc_value;
PyObject *curexc_traceback;
PyObject *exc_type;
PyObject *exc_value;
PyObject *exc_traceback;
PyObject *dict; /* Stores per-thread state */
int tick_counter;
int gilstate_counter;
PyObject *async_exc; /* Asynchronous exception to raise */
long thread_id; /* Thread id where this tstate was created */
} PyThreadState;
在PyThreadState对象中,我们看到熟悉的PyFrameObject(_frame)对象。也就是说,在每个PyThreadState对象中,会维护一个栈帧列表,以与PyThreadState对象的线程中的函数调用机制对应。在Win32上,情形也是一样,每个线程都会有一个函数调用栈
当Python虚拟机开始执行时,会将当前线程状态对象中的frame设置为当前的执行环境(frame):
PyObject *PyEval_EvalFrameEx(PyFrameObject *f, int throwflag)
{
…………
//通过PyThreadState_GET获得当前活动线程对应的线程状态对象
PyThreadState *tstate = PyThreadState_GET();
tstate->frame = f;
//设置线程状态对象中的frame
co = f->f_code;
names = co->co_names;
consts = co->co_consts;
…………
//虚拟机主循环
for (;;) {
opcode = NEXTOP();
oparg = 0; /* allows oparg to be stored in a register because
it doesn't have to be remembered across a full loop */
if (HAS_ARG(opcode))
oparg = NEXTARG();
//指令分派
switch (opcode) {
…………
}
…………
}
…………
}
而在建立新的PyFrameObject对象时,则从当前线程的状态对象中取出旧的frame,建立PyFrameObject链表:
PyFrameObject *
PyFrame_New(PyThreadState *tstate, PyCodeObject *code, PyObject *globals,
PyObject *locals)
{
//从PyThreadState中获得当前线程的当前执行环境
PyFrameObject *back = tstate->frame;
PyFrameObject *f;
…………
//创建新的执行环境
f = PyObject_GC_Resize(PyFrameObject, f, extras);
…………
//链接当前执行环境
f->f_back = back;
f->f_tstate = tstate;
return f;
}
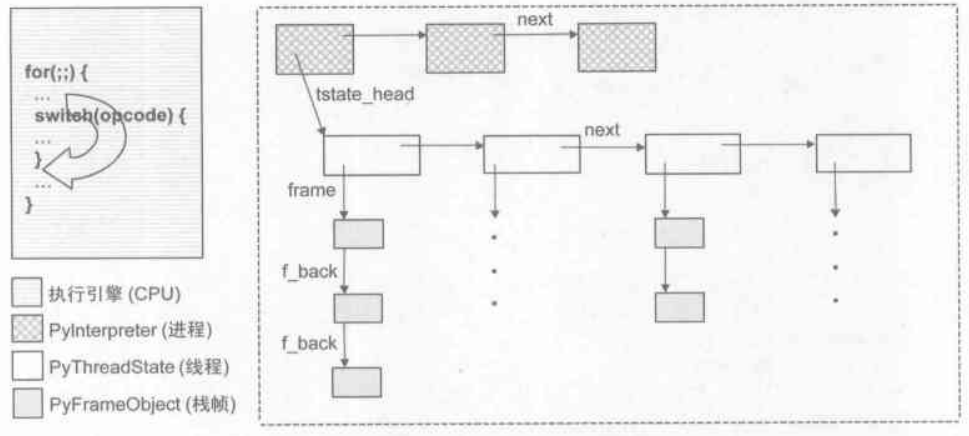
图1-2Python运行时环境